
机器学习—车辆种类图片识别
机器学习—车辆种类图片识别
一、选题的背景
随着城市化建设不断发展,我国对交通建设的需求也不断增长,成为了世界上在交通领域基础设施建设最快的国家之一,但车辆管控问题、道路交通问题、车辆违章问题等层出不穷,很难做到全面、有效的管理。马路上的摄像头每天拍摄下的许多汽车照片,怎么在大量的图片中筛选出是汽车的图片,并且识别出车辆种类,这时车辆识别就显得尤为重要。
二、机器学习案例设计方案
1.本选题采用的车辆不同种类数据集来自于网站,总共包含十种不同的车辆,分别为公交车、房车、消防车、卡车、吉普、小型客车、赛车、SUV、出租车和货车。在训练之前,把同种类型的车辆图片放到一个相同的文件夹并命名分类,在训练时因为图片像素大小不同而采用进行数据处理。
2.选题采用的机器学习框架为:使用的anaconda3环境下的pytorch深度学习库,pytorch版本为1.13.1,python的版本为3.9,cuda版本为11.3,开发环境为pycharm 2022.3。
3.涉及到的技术难点与解决思路:首先是构建深度学习环境时遇到了各种困难,比如安装pytorch时与python版本不一致,不知道怎么创建anaconda的虚拟环境,使用conda或pip安装不了一些库,不知道怎么预处理数据以及传入神经网络等。解决方式是在csdn等网站搜索相关问题并尝试解决。最终确定的最终方案是:划分数据集-用csv文件索引数据集-预处理图片数据(比如resize,totensor等)-构建神经网络-将数据输入网络进行训练以及测试-验证网络模型
三、机器学习的实现步骤
1.数据集的准备(十分类问题):
下载所需要的数据集:
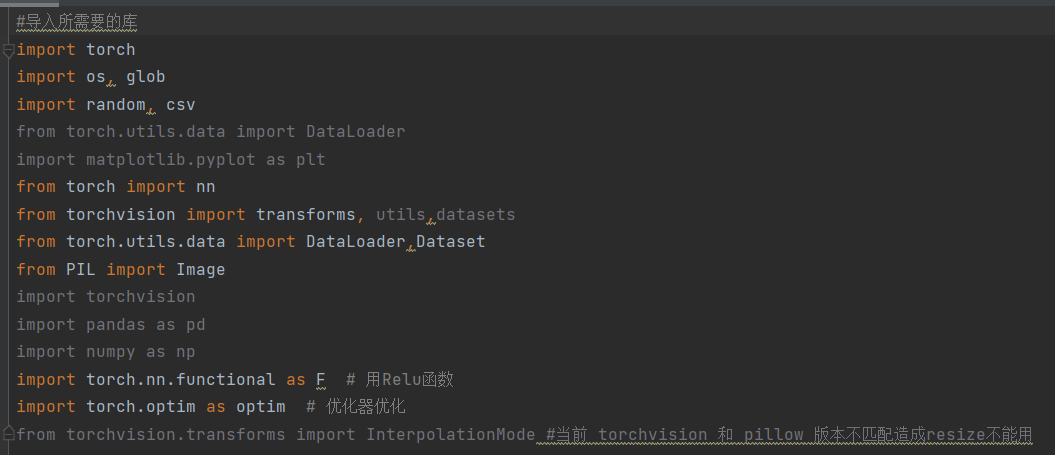
2.导入需要用到的库:
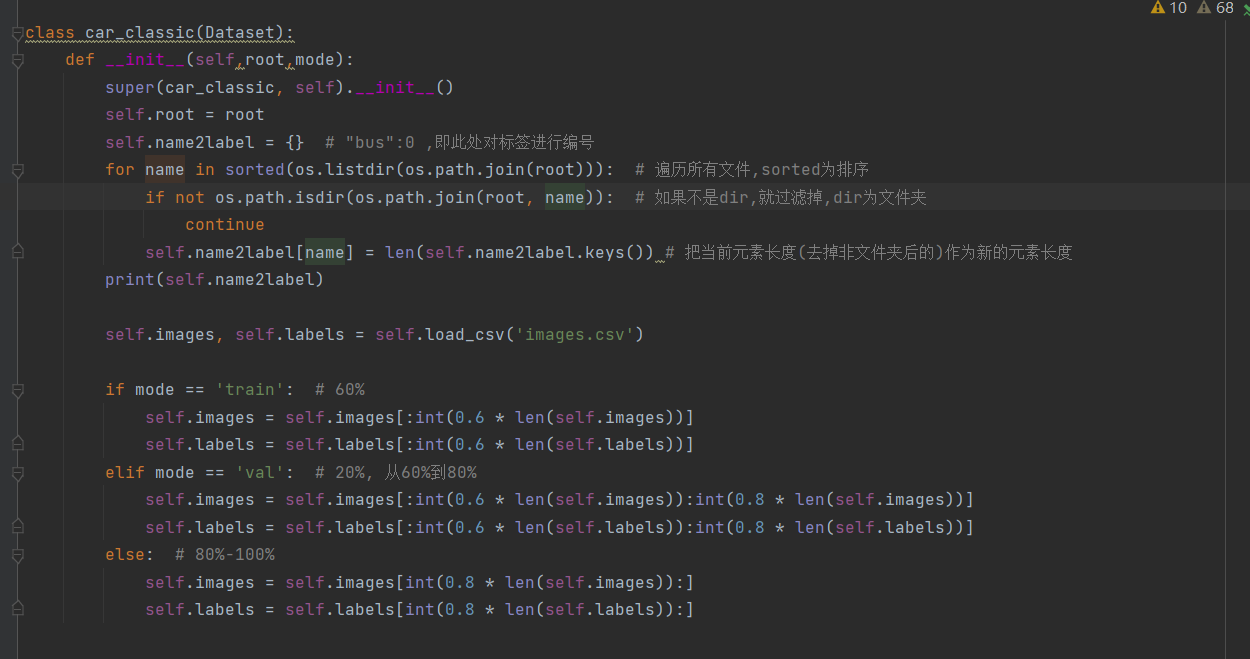
3,遍历所有文件并对标签进行编号,划分训练集、验证集与测试集:
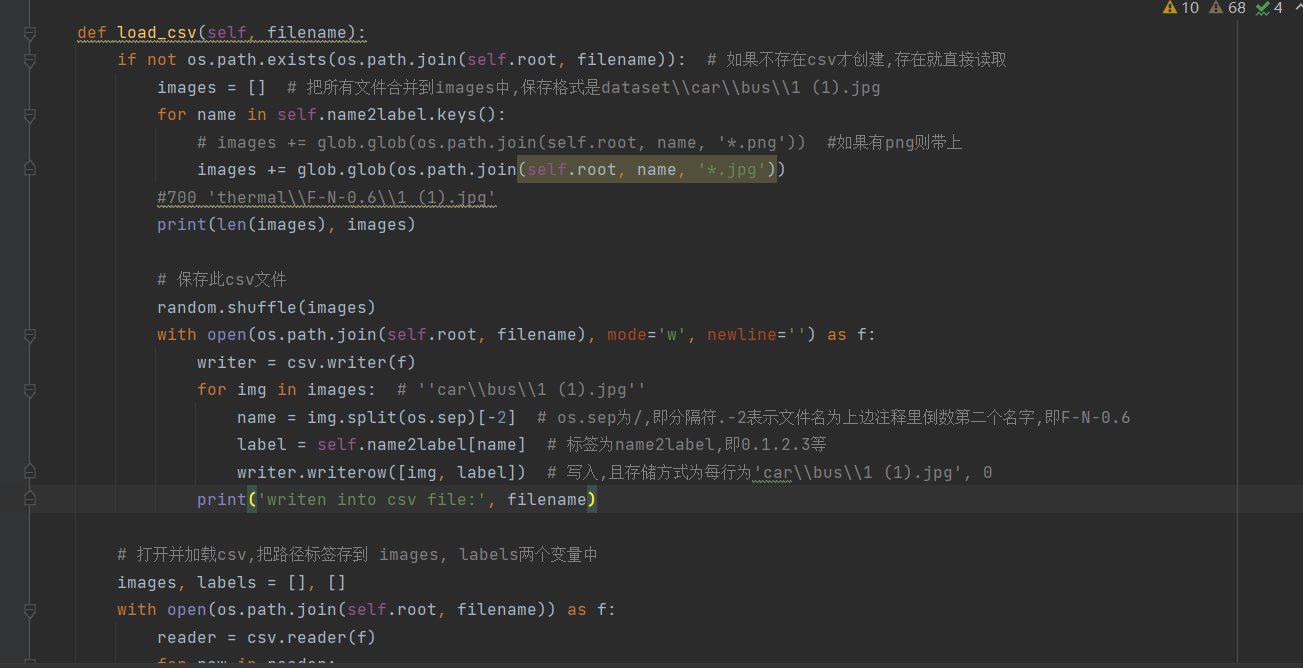
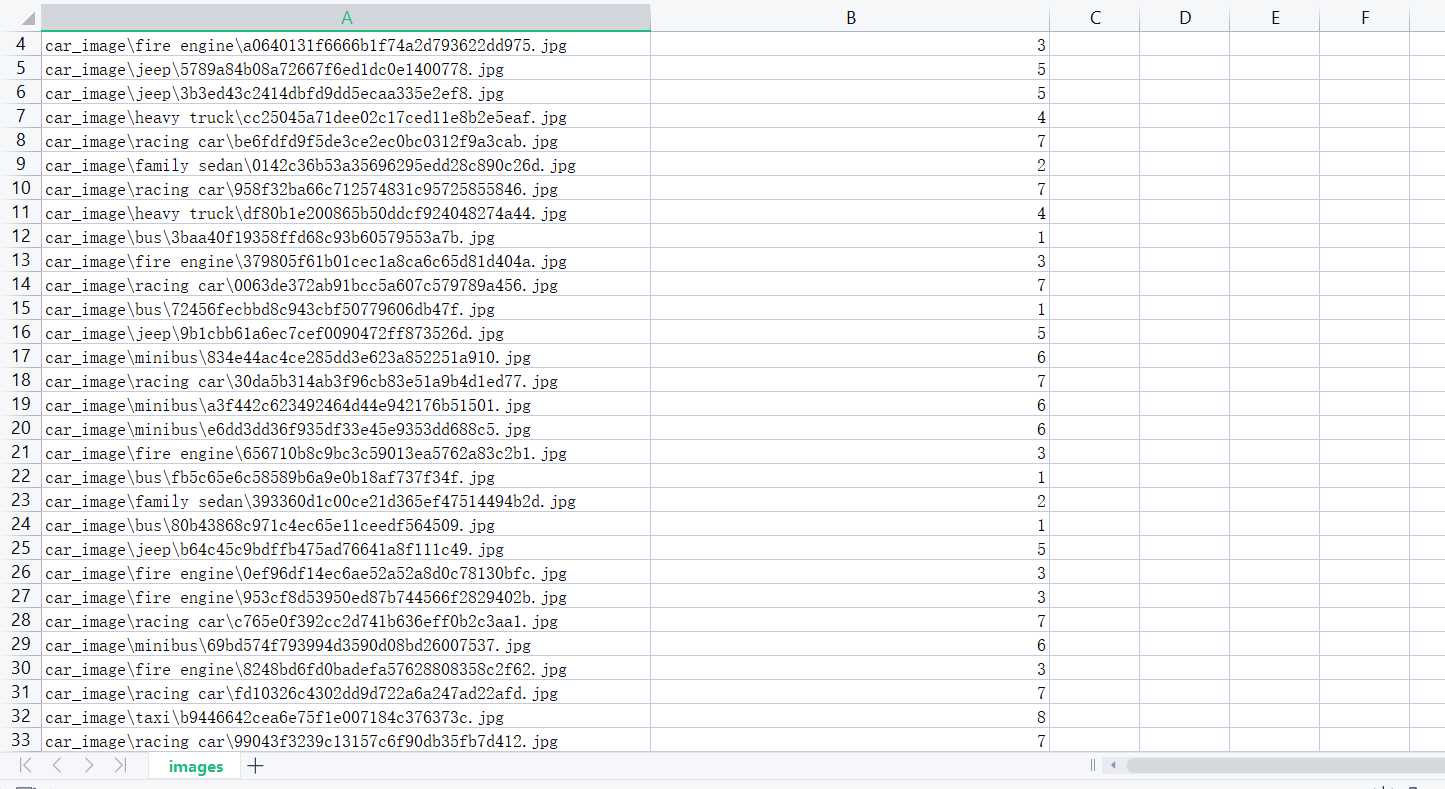
4. ,建立csv文件保存图片的数据与标签:
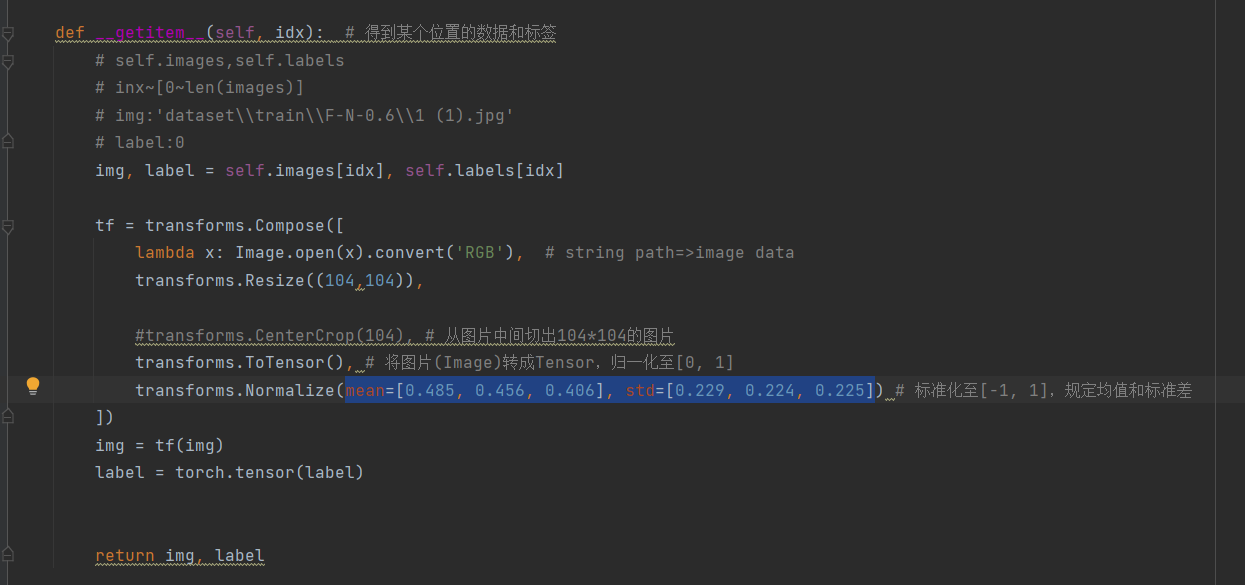
5.设置getitem方法得到某个位置的数据和标签并做图像预处理:
利用pytorch库中的transformes方法将图片先用rgb格式打开,然后统一缩放为104X104的像素格式以便于输入网络进行训练,利用totensor函数将图片转换成向量的格式并利用ImageNet提供的均值和方差mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
进行归一化处理,以便于数据可以在(-1,1)之间,减小数据量以及使其服从正态分布。
处理前和处理后的图片的对比:

处理前的图片

处理后的图片
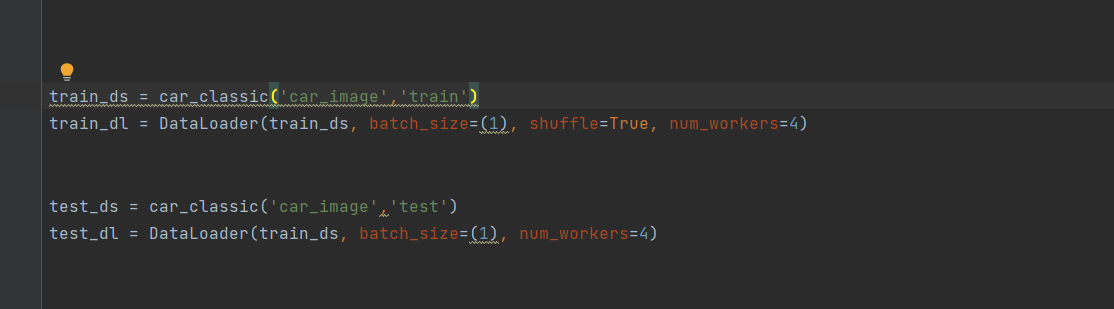
6.读取训练集和测试集的照片:
7.构建神经网络:
神经网络采用经典的lenet-5网络,两个卷积层,两个池化层,一个全连接层,最后输出为10维的向量:
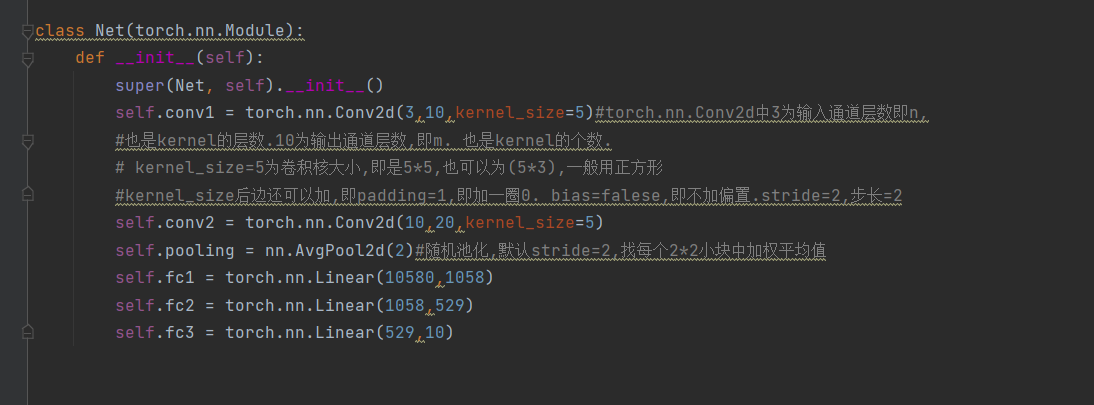
8.设置前向传播函数,优化器选择sgd,参数为lr=0.005, momentum=0.5,如果有显卡,设置可以使用cuda进行加速:

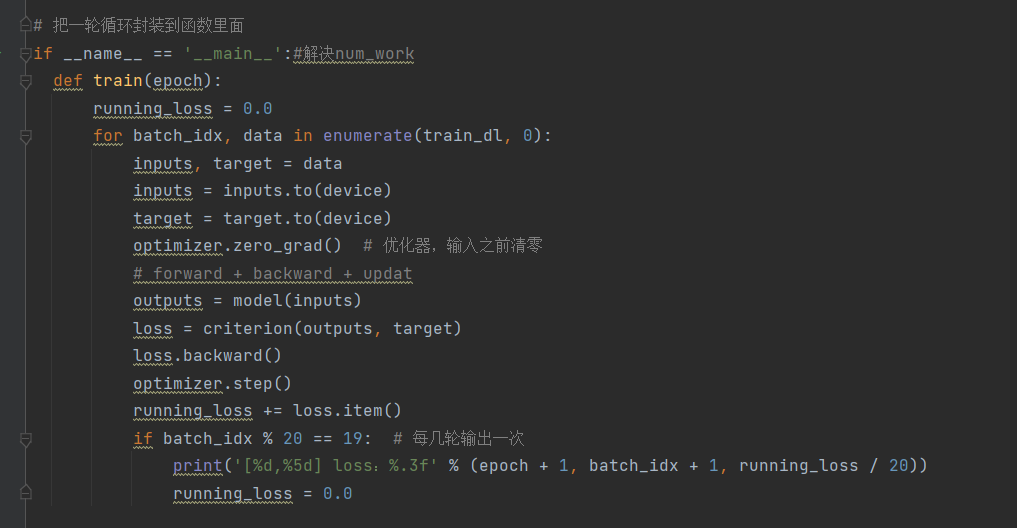
9.封装函数进行训练,设置每训练20次输出一次loss值,设置每一次epoch进行一次test来验证当前神经网络的准确率:
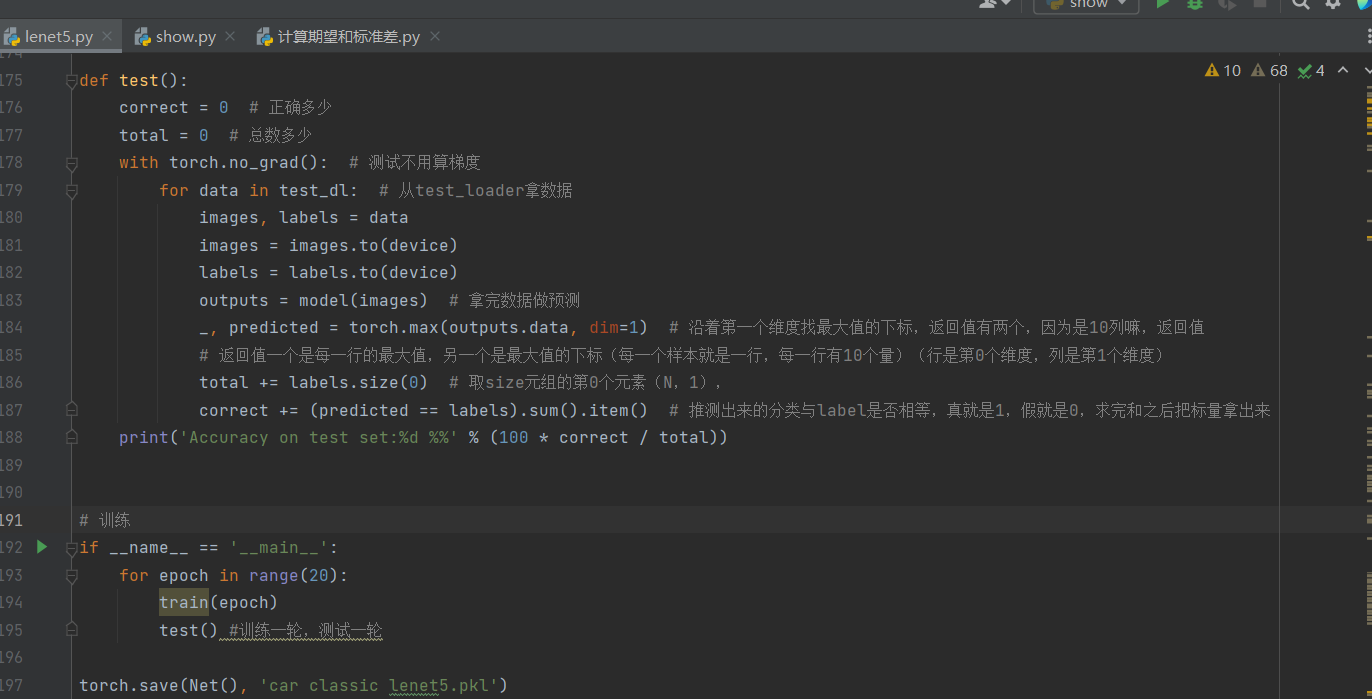
10.每次epoch进行一次网络模型的保存,一共设置20次epoch:
11.训练过程展示:
第一次epoch后准确率为35%
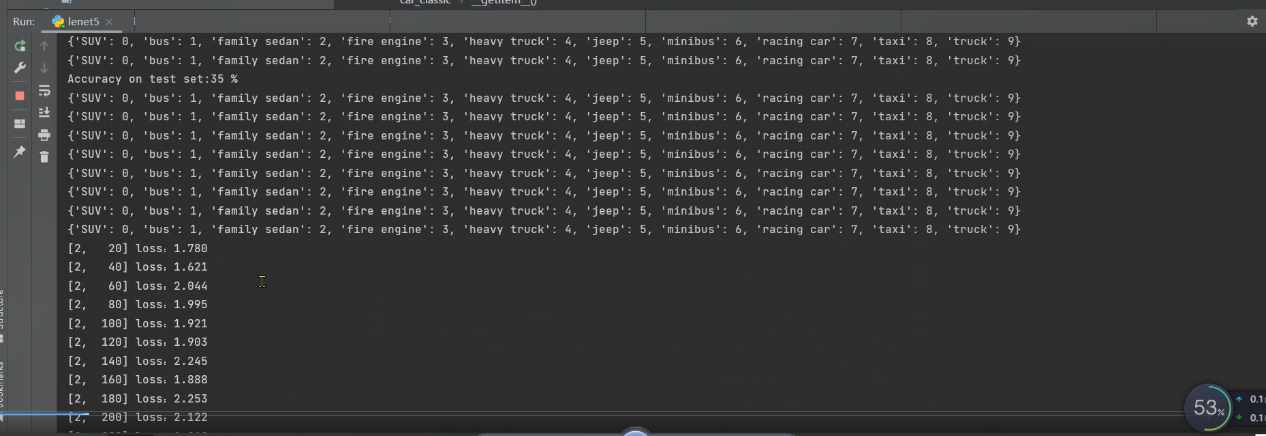
第三次epoch训练过程中的梯度下降展示:

训练时读取图片与标签展示:

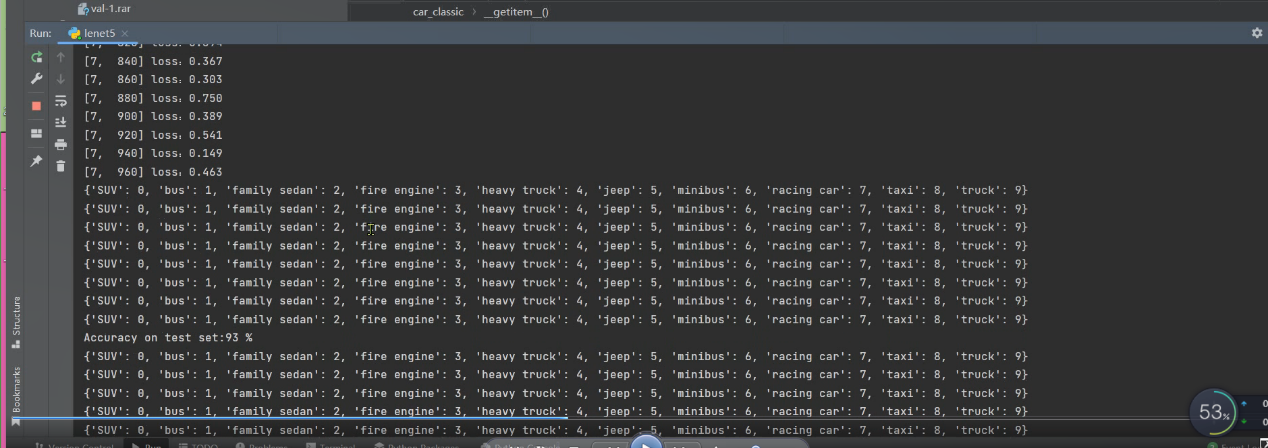
在第七次epoch时,准确率已达到93%:
四、总结
本次的程序设计主要内容是机器学习的图片标签分类学习,通过本次课程设计,加深了我对于机器学习以及图片分类任务的理解。
机器学习其实就是通过让计算机理解数据,并对数据进行对比处理进而获得一种模型对未被训练过的数据进行预测的一种方法.此次学习主要是对图片的十分类问题进行实践,多分类函数使用的是softmax,可以计算矩阵中不同维度模块的比重,且具有归一与非线性激活作用。而卷积层可以对矩阵进行维度扩大,从而获得更大的感受野,进而可以感知到图片中更多的特征。损失函数使用带有向量的sgd函数可以使训练在遇到死点时更好的跨越过去从而保证梯度的下降。
本次程序实际的不足:没有做到训练过程中图片的可视化,可以进一步学习matplotlib库或者vidsom库进行训练的可视化。可以使用更好的神经网络结构进行训练,比如vgg-16或者resnet等。
以下附上完整代码


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步