selenium(一)---selenium基础
一、selenium介绍
selenium是一个用于测试web程序的工具。selenium测试直接运行在浏览器上,就像真正的用户在操作浏览器一样。
selenium的主要功能有:测试与浏览器的兼容性,测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能,创建回归测试检验软件功能和用户需求。
selenium的优点:
- 免费且开源
- 支持linux、windows、macos系统
- 支持IE、Chorme、Firefox、 Safari、Opera等浏览器
- 支持Java、Python、Ruby、JS、C#、PHP语言等编程语言
- 可以轻松地与其他工具进行集成,例如unittest、pytest、Junit、TestNG、Maven、Jenkins等
- 通过Selenium Grid实现并行分布式测试
二、selenium安装
1.安装selenium
pip install selenium
2.下载驱动
不同的浏览器的不同版本下载不同的驱动,驱动下载解压,然后添加环境变量。下载驱动地址:https://www.selenium.dev/documentation/en/webdriver/driver_requirements/
如果要打开IE浏览器的话,需要在浏览器的Internet选项中的安全页里有4个安全选项,Internet、本地Internet、受信任的站点、受限制的站点,这4个里面都有一个启用保护模式,都需要勾选上才可以,还得把驱动的路径加入到环境变量中。
三、selenium启动浏览器
本文以python语言,Chorme浏览器为例
1.启动浏览器
from selenium import webdriver driver = webdriver.Chrome() #启动浏览器 driver.get("https://www.baidu.com") #在浏览器中打开百度页面 driver.quit() #退出浏览器
2.屏蔽chrome浏览器的信息提示栏
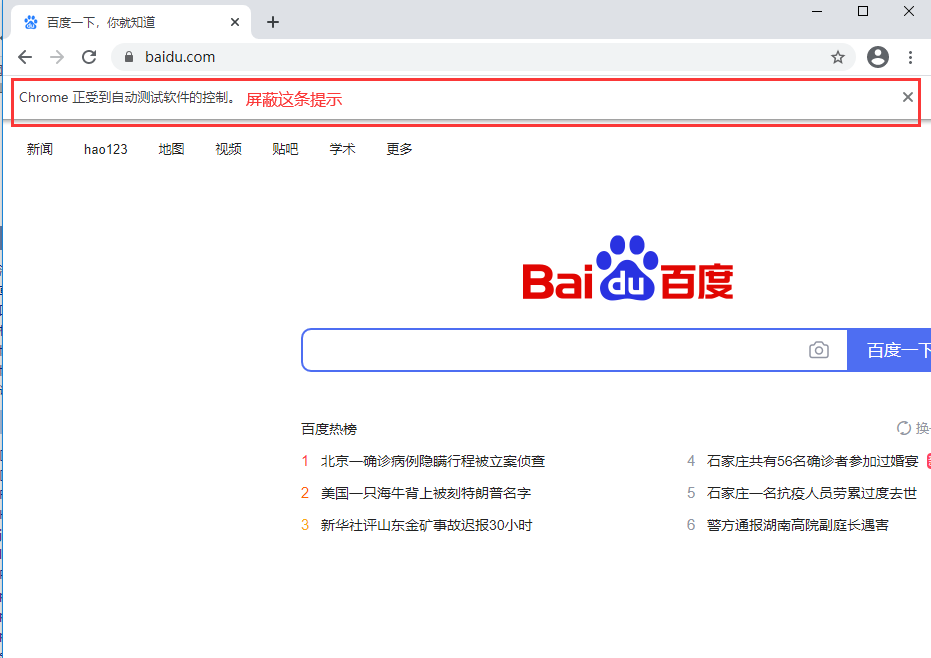
from selenium import webdriver options = webdriver.ChromeOptions() #设置chrome浏览器选项 # options.add_argument('disable-infobars') #这种方式失效了 options.add_experimental_option("excludeSwitches",['enable-automation']) driver = webdriver.Chrome(chrome_options=options) driver.get("https://www.baidu.com") driver.quit()
3.chrome浏览器模拟手机
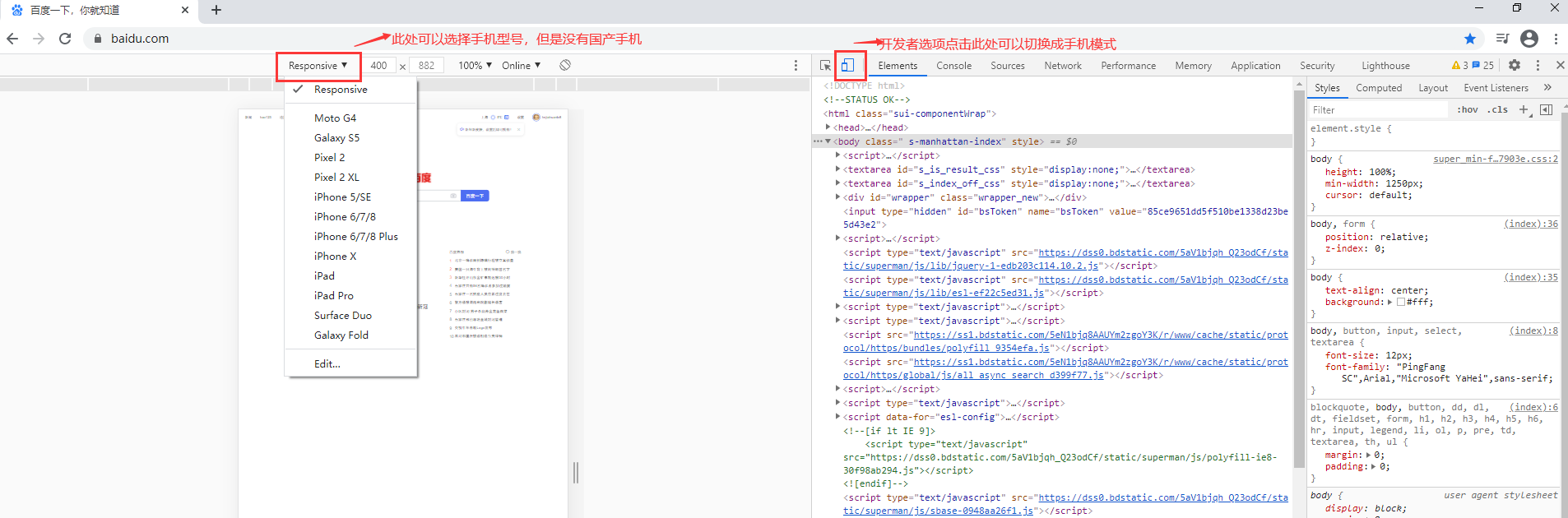
from selenium import webdriver mobileEmulation = {"deviceName":"iPhone 6"} #设置手机型号,都是比较老的机型 options = webdriver.ChromeOptions() options.add_experimental_option("mobileEmulation",mobileEmulation) driver = webdriver.Chrome(chrome_options=options) driver.get("https://www.baidu.com") driver.quit()
4.设置无头模式
# chrome无头浏览 from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument("--headless") #设置无头浏览 options.add_argument("log-level=1") #设置log显示等级为1,默认为0,不然会有很多info信息打印;INFO=0 WARNING=1 LOG_ERROR =2 LOG_FATAL=3 driver = webdriver.Chrome(chrome_options=options) driver.get("http://www.baidu.com") element = driver.find_element_by_id("kw") print(element.get_attribute("outerHTML")) driver.quit()
5.设置浏览器窗口大小
driver.set_window_size(400,800) #设置浏览器窗口大小为宽400,高800 driver.maximize_window() #最大化浏览器窗口 driver.minimize_window() #最小化浏览器窗口
6.浏览器的前进后退和刷新
driver.forward() #前进 driver.back() #后退 driver.refresh() #刷新
7.浏览器的关闭
driver.close() #关闭浏览器当前页面 driver.quit() #关闭浏览器所有页面和驱动
四、selenium定位方式
在操作页面元素之前我们首先要对页面元素进行定位,元素定位的过程就是查找HTML元素的过程。find_element通过定位方式查找一个元素,如果有多个返回第一个;find_elements通过定位方式查找所有符合条件的元素,返回一个list
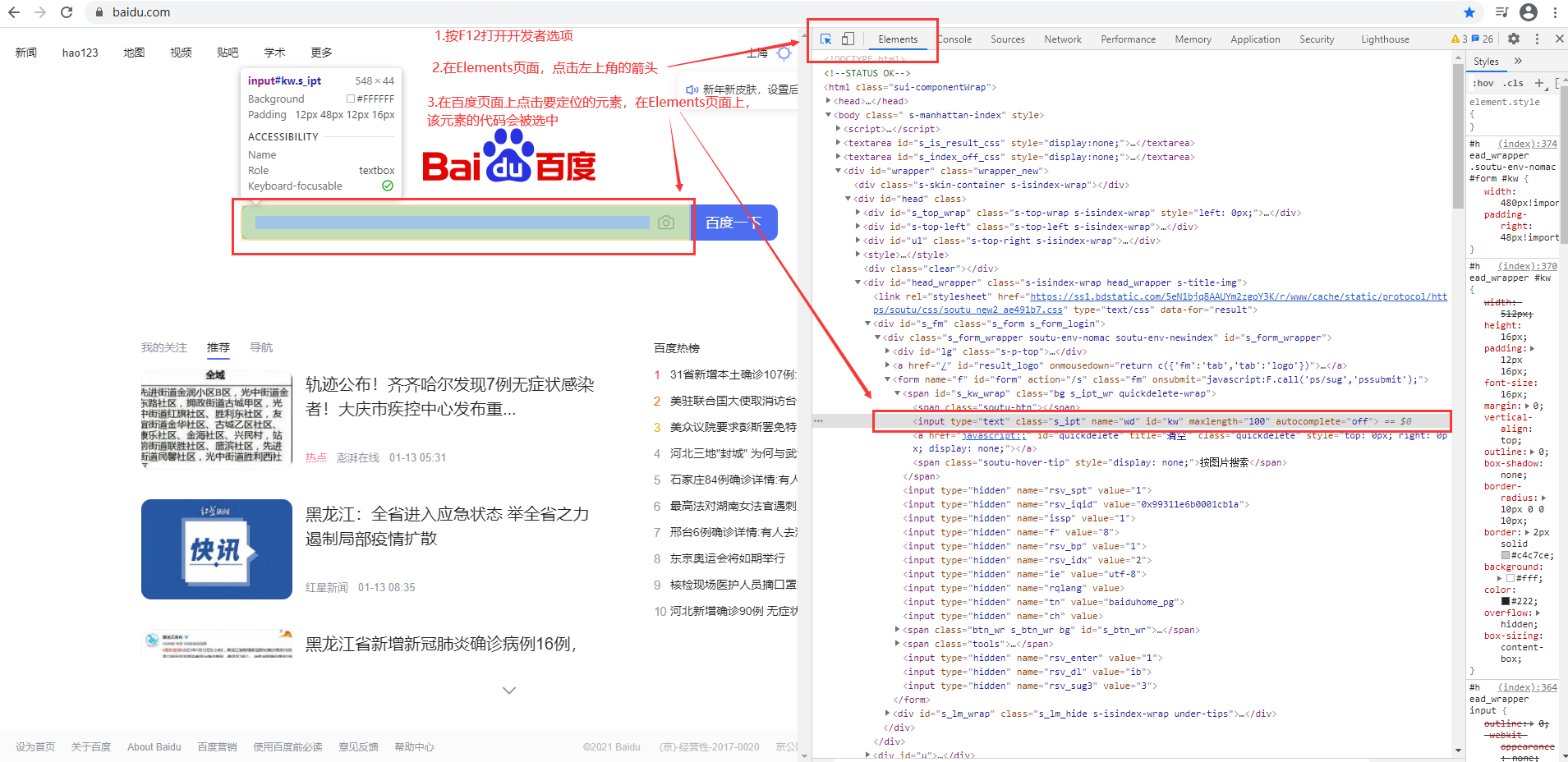
1.使用元素的属性定位
element = driver.find_element_by_id("kw") #通过元素的id属性值定位,id属性通常都是唯一的,但是id可能是动态的 element = driver.find_element_by_name("wd") #通过元素的name属性值定位,name属性不一定是唯一的 element = driver.find_element_by_class_name("s_ipt") #通过元素的class属性值定位,class属性不一定是唯一的 element = driver.find_elements_by_tag_name("input") #通过元素的标签名称定位,元素名称通常都不止只有一个,经常用find_elements_by_tag_name定位一组元素 element = driver.find_element_by_link_text("1石家庄今日新增确诊病例26例新") #通过有超链接的元素文本定位,需要输入完整的文内内容,否则会定位失败;一般用来定位页面上的超链接 element = driver.find_element_by_partial_link_text("石家庄今日新增确诊病例26例") #通过有超链接的元素的部分文本定位,一般用来定位页面上的超链接
2.使用xpath定位
xpath 是一门在 XML 文档中查找信息的语言,了解相关信息https://www.w3school.com.cn/xpath/index.asp
element = driver.find_element_by_xpath('xpath路径')
2.1 使用绝对路径定位:从根节点开始一层一层查找
/表示绝对路径,例如使用driver.find_element_by_xpath("html/body/div/div/div/div/div/form/span/input")可以定位到百度搜索输入框,但是繁琐
2.2通过相对路径定位
//表示相对路径,.表示当前元素,..表示父元素
- 通过属性定位,//*代表所有标签名,//*[@属性名="属性值"]
- 使用标签+属性查找;//标签名[@属性名="属性值"];
- 使用层级定位,先定位目标标签的父标签来定位子标签;//父标签名[@父标签属性名="父标签属性值"]/子标签;层级定位不限于两层,可以是多层的
- 索引,当一个父标签有多个相同标签名的子标签时使用;//父标签名[@父标签属性名="父标签属性值"]/子标签[索引值];xpath的索引值是从1开始的;不写标签值,如果有多个相同子标签默认定位第一个
- 逻辑and/or/not,当元素属性与其他元素有相同的部分,需要使用多个属性定位一个元素时使用and连接多个属性;//标签名[@属性名1="属性值1" and @属性名2="属性值2"]
- text关键字,//*[text()="百度一下"] 文本是百度一下的元素
- 模糊匹配,contains包含,starts-with匹配开头,ends-with匹配结尾,matchs正则匹配;//*[contain(@属性名,"部分属性值")]
- | 连接符 通过在路径表达式中使用|,可以选取若干个路径;//div/p | //input查找div标签下的所有p标签和所有input标签
- 通过轴定位关联标签;//标签名称/轴名称::标签名称;轴名称:
- ancestor:祖先节点 包括父
- parent:父节点
- prceding-sibling:当前元素节点标签之前的所有兄弟节点
- prceding:当前元素节点标签之前的所有节点
- following-sibling:当前元素节点标签之后的所有兄弟节点
- following:当前元素节点标签之后的所有节点
element = driver.find_element_by_xpath('//input[@id="kw"]') #利用标签名+属性定位百度搜索框 element = driver.find_element_by_xpath('//*[@name="wd" and @class="s_ipt"]') #利用2种属性定位百度搜索框 element = driver.find_element_by_xpath('//div[@id="s-top-left"]/a[2]') #利用层级定位和索引定位百度页面左上角的hao123超链接地址
3.使用CSS定位
css是一种语言,用来描述HTML和XML文档的表现。css使用选择器来为页面元素绑定属性,这些选择器可以被selenium用作定位。css比xpath定位快
element = driver.find_element_by_css_selector('css表达式')
3.1通过属性定位,id用#表示,#kw;class用.表示,.s_ipt;其实属性使用属性名,[属性名="属性值"];还可以加上标签,标签名[属性名="属性值"]
3.2使用层级定位,父标签[父标签属性名="父标签属性值"]>子标签
3.3使用索引定位,父标签[父标签属性名="父标签属性值"]>子标签:nth-child(索引值),索引值从1开始;nth-child(索引值)表示父标签下所有子标签的顺序值,可省略子标签名;父标签[父标签属性名="父标签属性值"]>p:nth-of-type(n) 表示父标签下第n个p标签
3.4使用逻辑定位,标签名[属性名1="属性值1"][属性名2="属性值2"] 表示and
3.5使用模糊匹配,^表示匹配开头,$匹配结尾,*表示包含;标签名[属性名*="属性值"]
element = driver.find_element_by_css_selector('#kw') #利用id属性定位百度搜索框 element = driver.find_element_by_css_selector('input[name="wd"][class*="ipt"]') #利用2种属性定位百度搜索框 element = driver.find_element_by_css_selector('div#s-top-left>a:nth-child(2)') #利用层级定位和索引定位百度页面左上角的hao123超链接地址
4.如何选择元素定位
如果有标签有id属性,使用id定位;如果没有id,或者id是动态的,使用xpath或css定位,css定位更快,推荐使用css;如果有超链接,使用link_text或partial_link_text定位
5.复制xpath路径和css路径
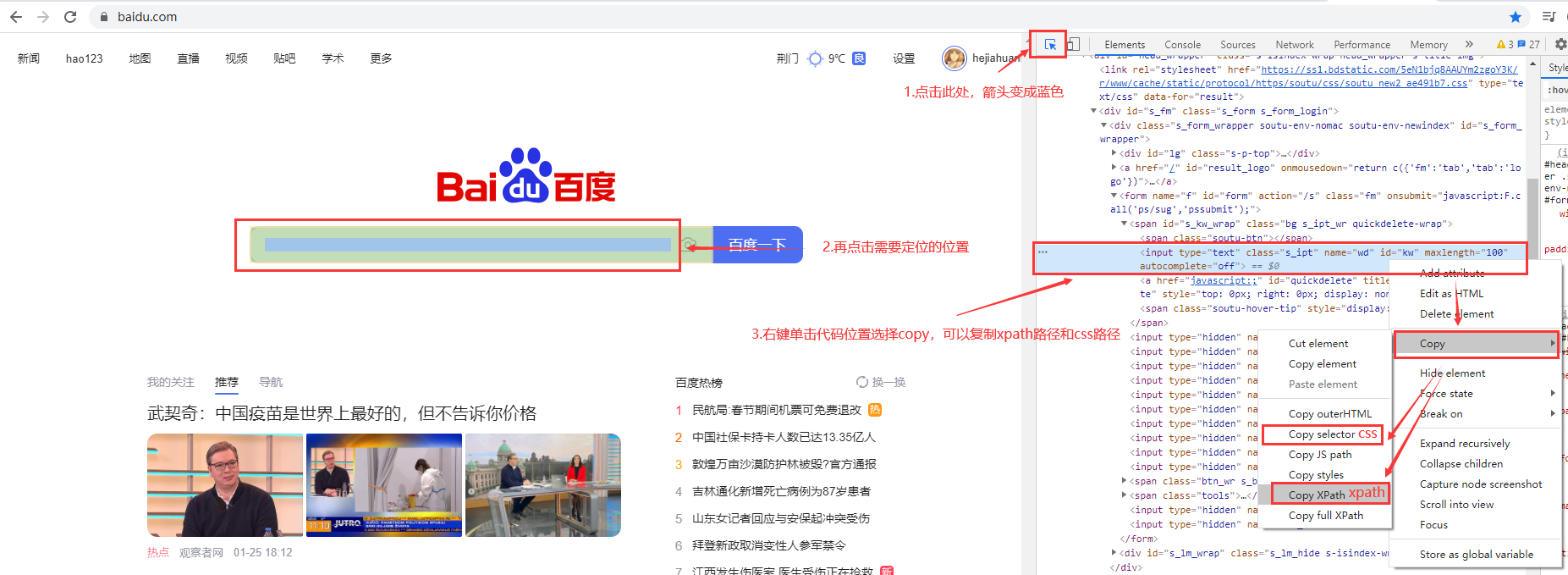
五、元素操作
element.click() #点击 element.send_keys("输入的内容") #输入 element.clear() #清空
element.submit() #用于表单提交
element.size #获取元素的尺寸大小 element.text #获取元素的文本 element.tag_name #获取元素标签名 driver.title #获取当前页面的标题 driver.current_url #获取当前页面的url element.get_attribution("属性名") #获取元素的属性值 element.is_displayed() #判断元素是否可见 element.is_enabled() #判断元素是否可用
element.is_selected() #判断元素是否被选中,可用于单选框和复选框的选项
print(element.get_attribute("outerHTML")) #可以打印被定位的element的代码
from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() #最大化窗口 time.sleep(3) element = driver.find_element_by_id("kw") #定位百度搜索框 print(element.get_attribute("outerHTML")) #打印元素代码 element.send_keys("python") #在百度搜索框输入python driver.find_element_by_id("su").click() #再点击百度一下 time.sleep(3) print(driver.title) #打印页面标题 element.clear() #清空输入框 time.sleep(3) driver.quit()

六、鼠标事件
在测试中除了简单的click()点击鼠标左键的操作,还会涉及到点击鼠标右键,双击鼠标左键等操作,webdriver中使用ActionChains()类来提供鼠标相关操作。ActionChains()提供鼠标事件的常用方法:
- click(element):单击鼠标左键
- double_click(element):双击鼠标左键
- click_and_hold(element):长按鼠标左键
- context_click(element):单击鼠标右键
- drag_and_drop(source,target):把元素拖拽到目标元素上然后松开
- drag_and_drop_by_offset(source,x,y):把元素拖拽到(x,y)位置
- move_by_offset(x,y):把鼠标移动到(x,y)位置
- move_to_element(element):把鼠标移到元素位置
- move_to_element_by_offset(element,x,y):把鼠标移动到距离元素多少距离的位置
- release(element):在某个元素位置松开鼠标左键
- perform():执行链中的所有操作
在使用ActionChains之前需要导入类from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains #导入鼠标操作类 import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() #最大化窗口 time.sleep(3) setting = driver.find_element_by_id("s-usersetting-top") #定位右上角设置菜单 ActionChains(driver).move_to_element(setting).perform() #鼠标悬停在设置菜单上,显示出子菜单选项 gs = driver.find_element_by_link_text("高级搜索") #定位子菜单上的高级搜索 gs.click() #点击高级搜索 time.sleep(3) driver.quit() #关闭浏览器
七、键盘事件
有时我们在测试中需要使用tab键将标点聚焦到下一个元素,用于验证元素的排序是否正确;webdriver中的Keys()类提供键盘上的所有键输入,甚至可以模拟一些组合键操作,例如ctrl+a等;在某些复杂情况还会使用send_keys()来模拟上下键操作下拉列表的情况。
使用Keys()类来模拟键盘操作:
- send_keys(Keys.BACK_SPACE):删除键Backapace
- send_keys(Keys.SPACE):空格键Space
- send_keys(Keys.ESCAPE):退出键Esc
- send_keys(Keys.ENTER):回车键Enter
- send_keys(Keys.CONTROL,"a"):全选ctrl+a
- send_keys(Keys.CONTROL,"c"):复制ctrl+c
- send_keys(Keys.CONTROL,"v"):粘贴ctrl+v
- send_keys(Keys.CONTROL,"x"):剪切ctrl+x
- send_keys(Keys.F1):按F1
- send_keys(Keys.F12):按F12
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() #最大化窗口 time.sleep(3) element = driver.find_element_by_id("kw") #定位百度搜索框 element.send_keys("python") #在搜索框中输入python element.send_keys(Keys.ENTER) #在搜索框中回车 time.sleep(3) driver.quit()
八、二次定位
1.二次定位:先定位父元素再定位其子孙元素

from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() #最大化窗口 time.sleep(3) e1 = driver.find_element_by_id("s-top-left") #先定位父元素左上方导航栏 # e1.find_elements_by_tag_name("a")[1].click() #定位导航栏的子元素,在父元素的代码找a标签返回一个列表,取第二个hao123 # e1.find_element_by_css_selector("a:nth-child(2)").click() #二次定位使用css e1.find_element_by_xpath("./a[2]").click() #二次定位使用xpath要写.表示e1元素,再根据e1元素找子元素,写//会在全页面里找 time.sleep(3) driver.quit()
2.使用select二次定位,只能select下拉框使用
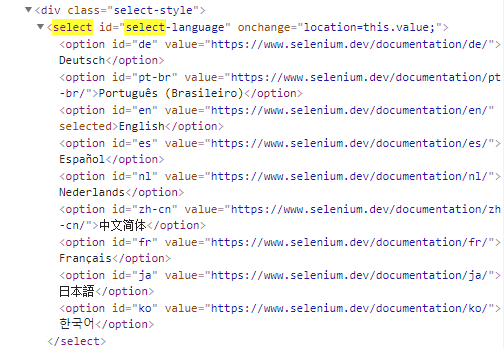
from selenium import webdriver from selenium.webdriver.support.select import Select #导入Select import time driver = webdriver.Chrome() driver.get("https://www.selenium.dev/documentation/en/") #国外网站selenium,加载很慢,加载完成后才开始进行下步操作 driver.maximize_window() #最大化窗口 time.sleep(3) s = driver.find_element_by_id("select-language") #首先定位到select元素 # s.find_elements_by_tag_name("option")[5].click() #使用二次定位定位option元素 # Select(s).select_by_index(5) ##根据索引选择,从0开始 # Select(s).select_by_value("https://www.selenium.dev/documentation/zh-cn/") #根据value属性选择 Select(s).select_by_visible_text("中文简体") #根据文本内容选择,不需要click() time.sleep(3) driver.quit()
九、页面操作
1.滚动条操作
在HMTL中有些元素是动态加载的,元素根据滚动条的下拉而被加载;通过JS脚本来控制滚动条
设置JS脚本控制滚动条:js = "window.scrollTo(0,1000)",前面的0是水平距离,1000是垂直距离,单位是像素
selenium同步执行js脚本:driver.execute_script(js)
from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") time.sleep(3) js = "window.scrollTo(document.body.scrollWidth,0)" #水平滚动条拉到最右边,document.body.scrollWidth表示实际宽度,也可以写一个足够大的数字
#js = "window.scrollTo(0,document.body.scrollHeight) #垂直滚动到最底部,document.body.scrollHeight表示实际高度
driver.execute_script(js) time.sleep(3) driver.execute_script("window.scrollTo(0,0)") #水平滚动条拉到最左边,第一个数字写0 time.sleep(3) driver.quit()
2.聚焦元素
滚动条滚动到元素位置,js代码,js = "arguments[0].scrollIntoView();"
from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") time.sleep(3) setting = driver.find_element_by_id("s-usersetting-top") #定位右边的设置菜单 driver.execute_script("arguments[0].scrollIntoView();",setting) #执行js脚本滚动到设置的位置 time.sleep(3) driver.quit()
3.frame
在web应用中经常用到表单嵌套页面,frame标签有frameset、frame、iframe三种,frameset与其他元素一样,不会影响到定位;而frame和iframe需要切换进去才能定位到其中的元素。通过switch_to_frame()(也可以写switch_to.frame())方法把当前定位的主体切换到表单内嵌页面中。再要定位frame外面的邮箱,需要再切换到外层
#iframe #网易邮箱 from selenium import webdriver import time driver = webdriver.Chrome() driver.maximize_window() driver.get("https://mail.163.com/") iframe = driver.find_element_by_css_selector("div#loginDiv>iframe") #定位到iframe driver.switch_to_frame(iframe) #切换到iframe email = driver.find_element_by_css_selector("div#account-box>div>input") #定位到邮箱地址输入框 print(email.get_attribute("outerHTML")) # driver.switch_to_default_content() #切换到最外层,也可以写driver.switch_to.default_content() driver.switch_to.parent_frame() #切换到上一层,如果只有一层frame,这两个操作都可以 e = driver.find_element_by_link_text("企业邮箱") #定位外层的企业邮箱链接 print(e.get_attribute("outerHTML")) driver.quit()
4.多窗口切换
在页面中点击每个元素会弹出新的窗口,这时需要切换到新窗口操作
- switch_to.window():在不同窗口切换,也可以写switch_to_window()
- current_window_handle:获得当前的窗口句柄
- window_handles:获取所有的窗口句柄
#切换窗口 from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") time.sleep(3) driver.find_element_by_link_text("hao123").click() #点击hao123页面 handles = driver.window_handles #获取所有的窗口句柄 print(driver.current_window_handle) #打印当前窗口句柄,CDwindow-96A0DC2749E8B6E507D72A73872755B7,每次打印的都不一样 print(driver.title) #打印当前窗口标题,百度一下,你就知道 driver.switch_to_window(handles[1]) #切换窗口 print(driver.title) #打印当前窗口标题,hao123_上网从这里开始 driver.quit()
5.浏览器自带弹窗
webdriver处理js所生成的alert、confirm、prompt,需要使用switch_to_alert()(也可以写switch_to.alert())去定位到弹框,然后使用text/accept/dismiss/send_keys()进行操作
- text:alert/confirm/prompt弹框中的文本
- accept:点击确认按钮
- dismiss:点击取消按钮,有才能操作
- send_keys():输入值,有输入框才能操作
6.自定义弹框
由于alert弹框不美观,很多网站都自定义弹框,webdriver使用js处理自定义弹框,利用html dom style对象,有一个display属性,设置元素如何被显示;js = 'document.getElementById("id属性值").style.display="none";';document文档,指整个页面代码
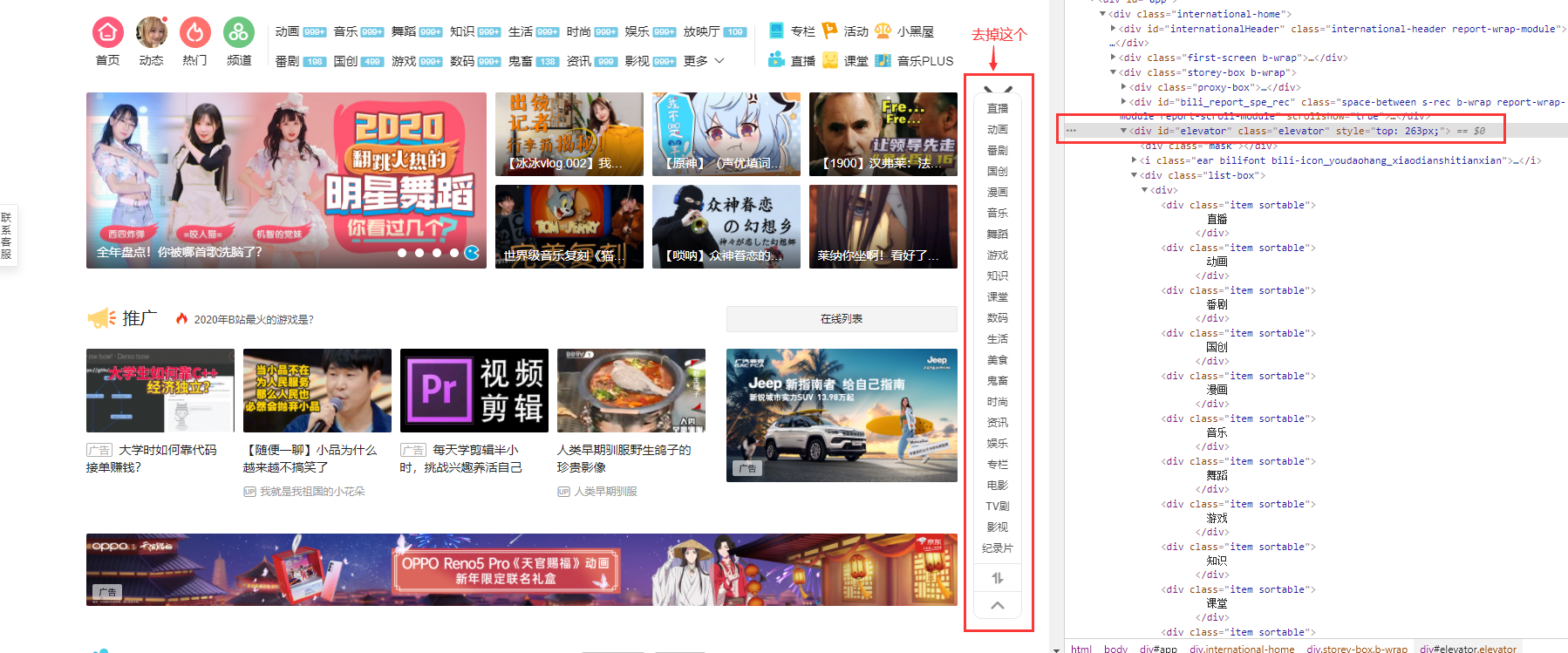
#处理自定义弹框 #哔哩哔哩 from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://www.bilibili.com") driver.maximize_window() time.sleep(3) js = 'document.getElementById("elevator").style.display="none";' #js脚本不显示id为elevator的元素 driver.execute_script(js) #执行js脚本 time.sleep(3) driver.quit()
6.单选框和复选框
单选框radio默认是圆形选框,复选框checkbox默认是方形选框
6.1 radio
先定位选项再点击可以选中
#百度 #单选框 from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains #导入鼠标操作类 import time driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() #最大化窗口 time.sleep(3) setting = driver.find_element_by_id("s-usersetting-top") #定位右上角设置菜单 ActionChains(driver).move_to_element(setting).perform() #鼠标悬停在设置菜单上,显示出子菜单选项 gs = driver.find_element_by_link_text("搜索设置") #定位子菜单上的高级搜索 gs.click() time.sleep(3) s1 = driver.find_element_by_id("s1_1") #定位搜索框显示单选框的显示 # s1.click() #已选中再次点击没有取消选中 print(s1.is_selected()) #打印选项是否被选中;True s2 = driver.find_element_by_id("s1_2") #定位不显示 s2.click() #点击不显示 print(s1.is_selected()) #打印选项是否被选中;False print(s2.is_selected()) #打印选项是否被选中;True time.sleep(3) driver.quit()
6.2 checkbox
复选框,如果未选中点击会选中,如果已经选中再次点击会取消选中,所以点击之前要先判断是否选中;
#博客园随笔编辑页面 #复选框 from selenium import webdriver import time #因为需要登陆,加载了chorme浏览器的用户数据,获取cookie;但是不能开2个浏览器,会报错,提示“Message: invalid argument: user data directory is already in use” options = webdriver.ChromeOptions() options.add_argument("user-data-dir=C:\\Users\\***\\AppData\\Local\\Google\\Chrome\\User Data") driver = webdriver.Chrome(chrome_options=options) driver.get("https://i.cnblogs.com/posts/edit") print(driver.get_cookies()) #可以获取cookies driver.maximize_window() #最大化窗口 time.sleep(3) #滚动到最底部 js = "window.scrollTo(0,10000)" driver.execute_script(js) #定位复选框的上层元素 e = driver.find_element_by_css_selector("[name='高级选项']>div:nth-child(2)>div") #二次定位所有的复选框元素 boxes = e.find_elements_by_css_selector("input[type='checkbox'") #需要勾选的2个选项的id list = ["displayOnHomePage","isPinned"] for box in boxes: #复选框会有默认选项,判断是否已选中,如果已选中,反选取消选中 if box.is_selected(): box.click() #获取元素的id属性,如果是要勾选的,点击勾选 if box.get_attribute("id") in list: box.click() time.sleep(3) driver.quit()
7.富文本操作
富文本是一个iframe,需要切换到frame再操作内嵌元素
8.文件上传
8.1 一般文件上传是<input type=file ...>,先定位到元素,再send_keys(文件地址)上传文件

uploadfile = driver.find_element_by_name("UploadFile") uploadfile.send_key("文件地址") time.sleep(n)
上传文件的注意事项:在上传文件的时候需要对文件的类型、大小等做充分的验证;在执行上传脚本时,加一定的等待时间,sleep
8.2 少数上传文件不是input标签,需要借助autoit工具或者SendKeys第三方库解决
https://www.jianshu.com/p/fba37cc5d5e2
https://blog.csdn.net/hou_angela/article/details/86497395
9.文件下载
文件下载可以通过加载浏览器配置,也可以自行设置下载的配置项,下面介绍的是设置下载的配置项的方法
9.1Firefox文件下载
#Firefox下载文件 from selenium import webdriver import time import os #通过FirefoxProfile()对其参数做设置,这些参数可以通过在Firefox浏览器地址栏输入:about:config进行设置 fp = webdriver.FirefoxProfile() fp.set_preference("browser.download.folderList",2) #0表示下载到桌面,1表示下载到默认下载地址,2表示自定义下载路径 fp.set_preference("browser.downlaod.manager.showWhenStarting",False) #在开始下载时是否显示下载管理器 fp.set_preference("browser.download.dir",os.getcwd()) #指定下载路径,os.getcwd()返回当前目录 fp.set_preference("browser.helperApps.never.saveToDisk","application/octet-stream") #不再弹框询问文件类型,application/octet-stream表示二进制流,不知道文件类型;HTTP content-type常用对照表https://tool.oschina.net/commons driver = webdriver.Firefox(firefox_profile=fp) driver.get("http://chromedriver.storage.googleapis.com/index.html?path=87.0.4280.88/") time.sleep(3) driver.find_element_by_xpath('//a[text()="chromedriver_win32.zip"]').click() time.sleep(5) driver.quit()
9.2 chrome文件下载
#chrome浏览器文件下载 from selenium import webdriver import time options = webdriver.ChromeOptions() prefs = { "profile.default_content_settings.popups":0, #设置0表示禁止弹出弹框 "download.default_directory":"E:\\" #设置文件下载地址 } options.add_experimental_option("prefs",prefs) driver = webdriver.Chrome(chrome_options=options) driver.get("http://chromedriver.storage.googleapis.com/index.html?path=87.0.4280.88/") time.sleep(3) driver.find_element_by_xpath('//a[text()="chromedriver_win32.zip"]').click() time.sleep(5) driver.quit()
10.截图
#截图 from selenium import webdriver import time import os driver = webdriver.Chrome() driver.maximize_window() driver.get("http://www.baidu.com") time1 = time.strftime("%Y_%m_%d_%H_%M_%S",time.localtime()) filename = time1 + ".png" path = os.path.abspath("screenshot") pathname = path + "\\"+filename # driver.save_screenshot(filename) #截图保存在当前目录,文件名为当时时间 # driver.save_screenshot(pathname) #截图保存在screenshot目录,文件名为当前时间 driver.get_screenshot_as_file(pathname) #另一种截图保存方法 driver.quit()
十、浏览器免登陆
现在web应用登陆时,通常需要输入验证码,自动化测试时怎么处理验证码:
- 测试环境让开发去掉验证码
- 设置一个万能验证码
- 验证码识别技术
- 获取cookie免登陆;需要先登陆网站且不能退出,退出cookie会失效
下面介绍通过cookie绕过验证码
1.浏览器加载配置
通过加载浏览器配置可以获取浏览器的cookie信息,绕过登陆
1.1 Firefox
- 获取Firefox的配置文件路径:菜单>帮助>故障排除信息>配置文件夹;profile_directory=配置文件夹
- 加载配置文件
profile = FirefoxProfile(profile_directory)
driver = webdriver.Firefox(profile)
1.2 Chrome
options = webdriver.ChromeOptions() options.add_argument("user-data-dir=C:\\Users\\***\\AppData\\Local\\Google\\Chrome\\User Data") #只能打开一个chrome浏览器不然会报错 driver = webdriver.Chrome(chrome_options=options)
2.通过cookie
driver.get_cookies():获取所有的Cookie,返回列表格式,列表里面套字典
driver.get_cookie(name):获取指定name的Cookie值
driver.add_cookie(dict):添加cookie,必须要有name和value
driver.delete_cookie(name):删除指定name的cookie
driver.delete_all_cookie():删除所有的Cookie
#cookie登录博客园 from selenium import webdriver import time driver = webdriver.Chrome() driver.maximize_window() #最大化屏幕 driver.get("https://www.cnblogs.com") #进入博客园页面 time.sleep(5) #cookies登录博客园 cookies = [{'domain': '.cnblogs.com', 'expiry': 1611398938, 'httpOnly': False, 'name': '_gat_gtag_UA_48445196_1', 'path': '/', 'secure': False, 'value': '1'},
{'domain': 'i.cnblogs.com', 'httpOnly': True, 'name': '.AspNetCore.Session', 'path': '/', 'secure': False, 'value': 'C***'},
{'domain': '.cnblogs.com', 'expiry': 1611485278, 'httpOnly': False, 'name': '_gid', 'path': '/', 'secure': False, 'value': '**'},
{'domain': '.cnblogs.com', 'expiry': 1671607788, 'httpOnly': False, 'name': '_ga_4CQQXWHK3C', 'path': '/', 'secure': False, 'value': 'G**'},
{'domain': '.cnblogs.com', 'expiry': 1674470878, 'httpOnly': False, 'name': '_ga', 'path': '/', 'secure': False, 'value': 'GA**'},
{'domain': '.cnblogs.com', 'expiry': 1634994906, 'httpOnly': False, 'name': '__gads', 'path': '/', 'secure': False, 'value': 'ID**'},
{'domain': '.cnblogs.com', 'expiry': 1619531791, 'httpOnly': False, 'name': 'UM_distinctid', 'path': '/', 'secure': False, 'value': '**'},
{'domain': '.cnblogs.com', 'expiry': 1612672030, 'httpOnly': True, 'name': '.Cnblogs.AspNetCore.Cookies', 'path': '/', 'secure': False, 'value': '**'},
{'domain': '.cnblogs.com', 'expiry': 1632998446, 'httpOnly': False, 'name': 'Hm_lvt_39b794a97f47c65b6b2e4e1741dcba38', 'path': '/', 'secure': False, 'value': '160***'}] for cookie in cookies: driver.add_cookie(cookie) time.sleep(3) driver.refresh() #刷新浏览器,不刷新页面是看不到登陆后的信息的 time.sleep(3) driver.find_element_by_id("user_icon").click() #点击右上方图像进入个人博客主页 time.sleep(5) print(driver.title) #打印现在的页面标题,小测试00的主页 - 博客园 driver.quit()
十一、元素等待
由于现在大多数web应用程序都结合Ajax/JavaScript技术开发,当浏览器进行页面信息加载时,页面中的元素会在不同的时间间隙陆续完成加载;还有网络、电脑配置、服务器反应时间等因素影响,为了保证脚本的稳定性,需要给脚本增加一定的等待时间。
1.强制等待
time.sleep(s):针对Python代码,强制等待;有时控件加载或2个操作之间会sleep,防止网站认为是爬虫
2.隐式等待
driver.wait_implicatly(s):webdriver会在DOM中查找该元素,如果没找到将继续等待,超出设置的等待最大时间后将抛出找不到元素的异常。隐式等待服务于当前的整个测试脚本。
from selenium import webdriver import time driver = webdriver.Chrome() print(time.time()) driver.implicitly_wait(10) #隐式等待 driver.get("https://github.com/") print(time.time()) element = driver.find_element_by_partial_link_text("Sign up") #查找一个存在的元素 print(element.get_attribute("outerHTML")) print(time.time()) try: element1 = driver.find_element_by_tag_name("canvas1") #查找一个不存在的元素 except Exception as e: print(e) print(time.time()) driver.quit()
3.显示等待
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)在设定时间内等待指定元素,超出最长等待时间则抛出错误:
- driver:浏览器驱动
- timeout:最长等待时间,默认单位为秒
- poll_frequency:监测隔间时间,默认为0,5s
- ignored_exceptions:忽略的报错信息
- WebDriverWait有until和until_not方法;until(method,message);until_not(method,message)
#显示等待 from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait driver = webdriver.Chrome() driver.get("http://www.baidu.com") element = WebDriverWait(driver,10).until(lambda x:x.find_element_by_id("kw")) #until参数必须是一个方法,不能直接用driver.find_element;找一个存在的元素,找到返回元素,不存在报错 print(element.get_attribute("outerHTML")) element_is_displayed = WebDriverWait(driver,10).until(lambda x:x.find_element_by_id("kw").is_displayed()) #一个元素是否可见,返回布尔值 print(element_is_displayed) try: element = WebDriverWait(driver,10).until(lambda x:x.find_element_by_id("kk"),"没找到元素") #找一个不存在的元素 print(element.get_attribute("outerHTML")) except Exception as e: print(e) driver.quit()

4.expected_conditiions
expected_conditions是selenium的一个模块(简称EC),其中包含一系列可用于判断的条件;EC返回的是方法,常和WebDriverWait配合使用:
- title_is(title):判断网页title是否是括号内文本,返回布尔值
- title_contains(title):判断网页title是否包含文本,返回布尔值
- url_to_be(url):网页网址是否完全等于指定url,返回布尔值
- url_coantains(url):网页网址是否包含指定内容,返回布尔值
- url_matches(url):网页网址是否匹配指定内容,返回布尔值
- presence_of_element_located(locator):判断一个元素是否存在于页面DOM数中,存在则返回元素本身,不存在则返回False;locator是一个(by,path)元组,表示元素位置
- presence_of_all_elements_located(locator):定位的元素范围内,是否有一个元素存在于页面DOM中,如果是,返回满足条件的所有元素组成的list,否则返回False
- visibility_of_element_located(locator):判断一个元素是否存在与页面DOM数中且可见,可见意为元素的高和宽都大于0,存在则返回元素本身,不存在则返回False
- visibility_of(element):判断element是否可见,是返回元素,不存在返回False
- visibility_of_any_elements_located(locator):判断是否至少有一个元素在页面中可见,是返回列表
- invisibility_of_element_located(locator):判断一个元素是否不可见或者不存在页面DOM中,不存在则返回True,
- element_to_be_clickable(locator):判断一个元素是否可见并可点击,如果可以则返回该元素,否则返回False
- element_to_be_selected(element):判断一个元素是否已选择,是返回True
- text_to_be_present_in_element(locator,text):判断一个元素的文本是否包含text,返回布尔值
- text_to_be_present_in_element_value(locator,text):判断一个元素的属性值中是否包含text,返回布尔值
- frame_to_be_available_and_switch_to_it(locator):判断一个frame是否可以切换,如果可以切换frame并且返回True,否则返回False
- staleness_of(element):等待一个元素从页面DOM中消失,如果元素一直存在返回False,否则返回True
- alert_is_present():判断页面上是否有弹窗,如果存在返回弹框,如果不存在返回False
#WebDriverWait and excepted_conditions from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get("http://www.baidu.com") t1 = EC.title_is("百度一下,你就知道") t2 = EC.title_contains("我不知道") print(t1,"\n",t2) #打印方法 print(t1(driver),"\n",t2(driver)) #打印布尔值 locator = (By.CLASS_NAME,"s_ipt") #使用By定位的写法,需要先导入By,定位方式全大写 locator2 = ("class name","s_ipt") #不需要导入By,用下划线连接的名称变为空格分开 e1 = EC.presence_of_element_located(locator2) #一个页面上存在的元素 print(e1) #打印方法 print(e1(driver)) #打印元素 try: e2 = EC.presence_of_element_located((By.CLASS_NAME,"s_ipt11")) print(e2) print(e2(driver)) except Exception as e: print(e) e3 = WebDriverWait(driver,10).until(EC.presence_of_element_located(("class name","s_ipt"))) print(e3) #打印元素 driver.quit()