


数据库---MySQL(一)
一、介绍
1.数据库
数据库(database)就是存储数据的仓库。为了方便数据的存储和管理,将数据按照特定的规律存储在磁盘上。通过数据库管理系统,有效组织和管理存储在数据库中的数据。
数据库系统和数据库不是一个概念,数据库系统(DBS),比数据库大很多,由数据库、数据库管理系统、应用开发工具构成
数据库管理系统(Database Management System,简称DBMS)用来定义数据、管理和维护数据的软件。它是数据库系统的一个重要组成部分。
2.MySQL
MySQL的特点:
- MySQL 是一个关系型数据库管理系统,所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
- 开源免费
- 跨平台
3.SQL
Structured Query Language 简称SQL,结构化查询语句,数据库管理系统通过SQL语句来管理数据库中的数据。
- DDL(Data Defination Language):数据定义语言,主要用于数据库、表、视图、索引和触发器等。像DROP、CREATE、ALTER等语句
- DML(Data Manipulation Language):主要包括对数据的增删改。INSERT插入数据、UPDATE更新数据、DELETE删除数据
- DQL(Data Query Language):数据检索语句,用来从表中获得数据,确定数据怎样在应用程序中给出。像SELECT查询语句
- DCL(Data Control Language):数据控制语言,主要用于控制用户的访问权限。像GRANT、REVOKE、COMMIT、ROLLBACK等
二、安装
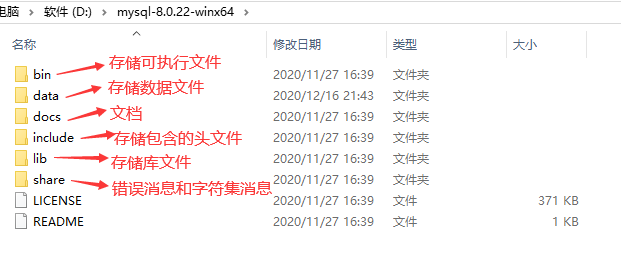
windows安装
下载地址: https://dev.mysql.com/downloads/mysql/,可以下载.zip文件直接解压,也可以下载安装包.msi安装。
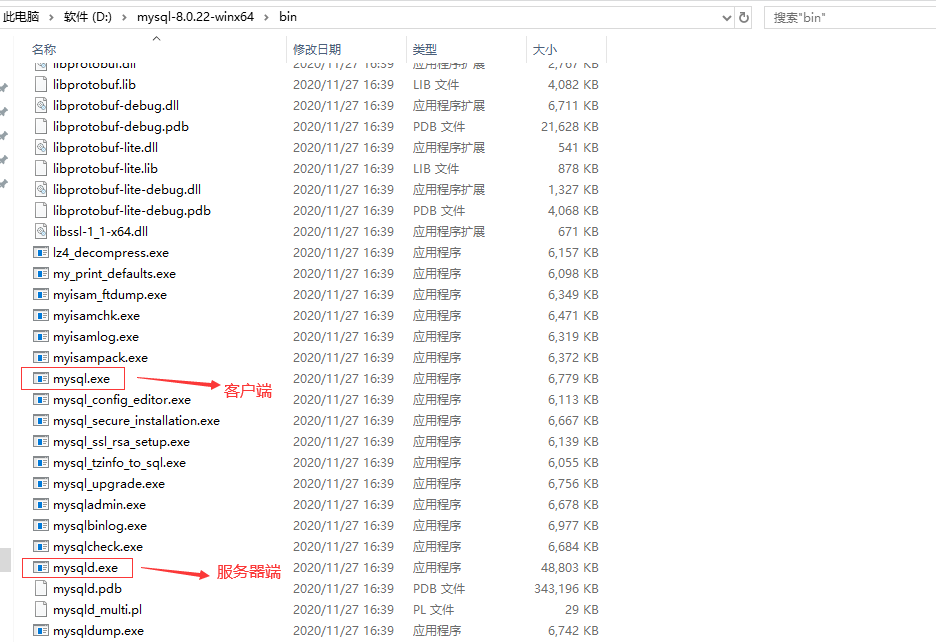
三、使用
--初始化MySQL服务器 mysqld --initialize-insecure --启动mysql服务器 mysqld --登录mysql mysql -h host -p port -D databasename -u username -p
--退出mysql
exit/quit/\q
ctrl+c --退出命令 --安装/删除mysql服务 mysqld --install mysqld --remove --启动/停止mysql服务 net start MySQL net stop NySQL
1.启动mysql服务




问题:

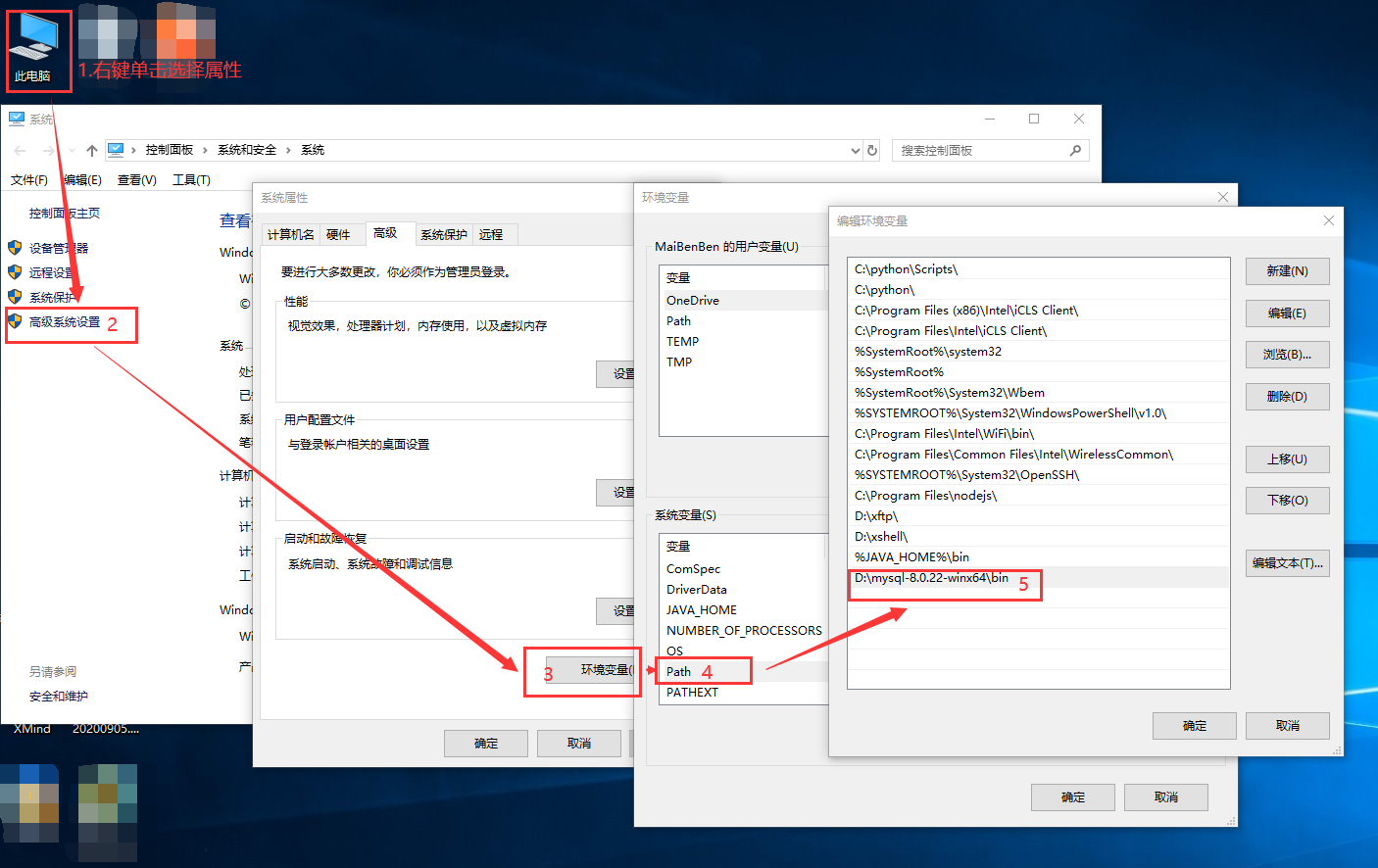
2.加入环境变量
3.设置windows服务
3.1 安装与删除服务

3.2 问题:Install/Remove of the Service Denied!

3.3 安装成功之后可以在服务中看到MySQL服务,点击启动
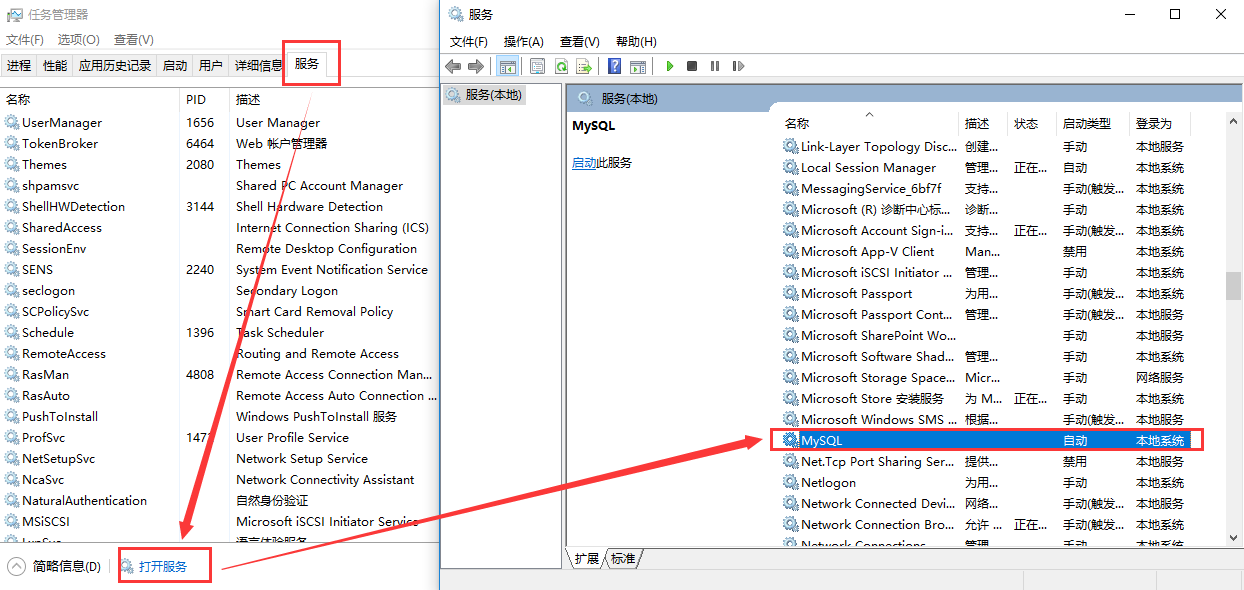
3.4 问题:点击启动服务时,提示 “本地计算机上的MySQL启动后停止,某些服务在未由其他服务或程序使用时将自动停止”;remove之后重新install之后正常

3.5 命令行启动与停止
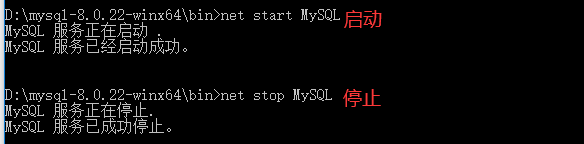
四、命令
1.数据库操作
--显示数据库 show databases; --使用数据库 use database_name; --创建数据库 create database database_name; create database database_name default charset=utf8; --删除数据库 drop database database_name;
1.1 显示数据库

1.2 创建数据库和删除数据库

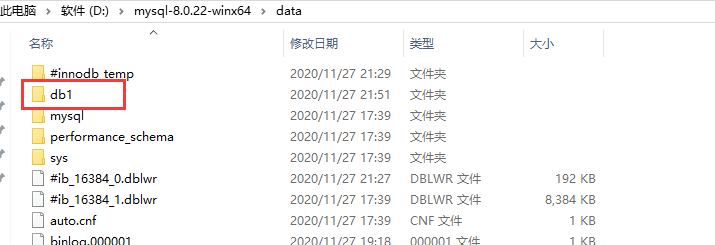
创建数据库之后data目录下会增加了db1目录

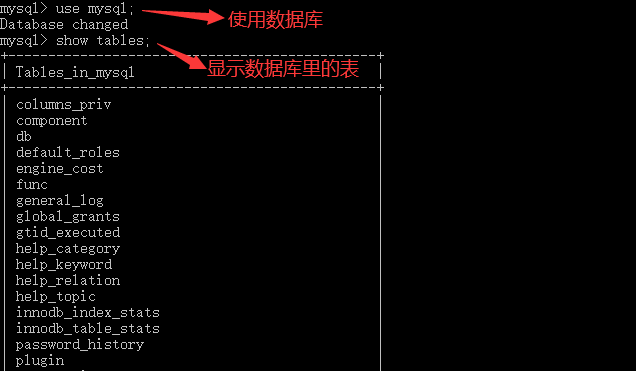
1. 3 使用数据库和显示数据表
2.用户管理
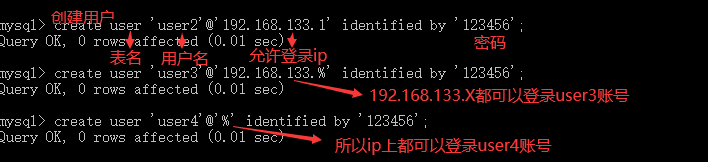
--创建用户 create user 用户名 identified by 密码; --授予用户权限 grant 权限 on database_name.table_name to 用户名; --查询用户权限 show grants for 用户名; --删除用户权限 revoke 权限 on datebase_name.table_name to 用户名; --删除用户 drop user 用户名; --修改账号用户名 rename user 新用户名 to 老用户名; --修改用户名 set password for 用户名=密码; --查询用户表 select * from user;
2.1 创建用户
2.2 用户权限
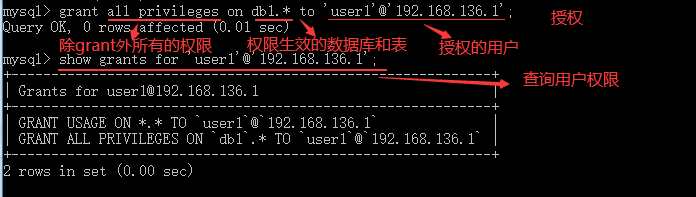

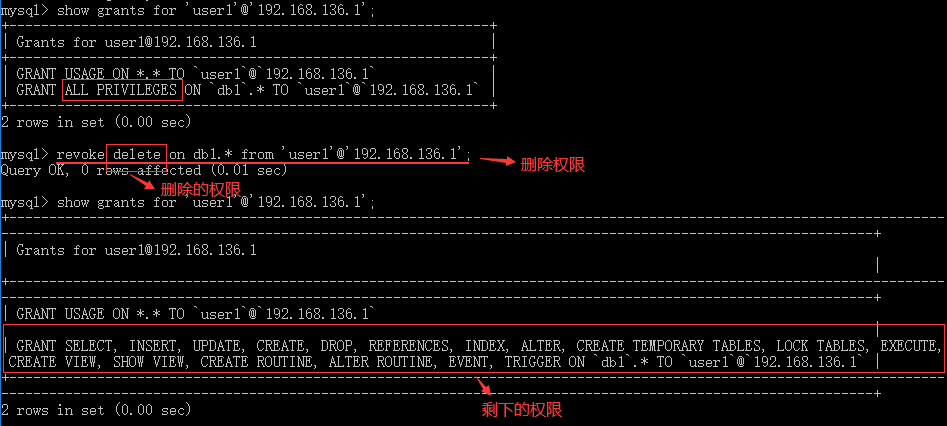
2.3 修改用户账号



3.数据表操作
3.1 创建数据表
--查询数据表;显示该数据库下所有表名称 show tables;
--创建数据表 create table table name ( column_name1 type 是否为空 comment ‘备注语句' auto_increment default 默认值, column_name2 type, ... primary key (column_name1), constraint fk_name foreign key (column_name) references table_name2(column_name), unique unique_name (column_name) )engine=innodb default charset=utf8;
- 是否为空:字段设置为 null 赋值时可以为空 ,not null 不能为空
- default:默认值,不设置默认为null
- auto_increment:定义列为自增的属性,必须和key一起使用。一般用于主键,且只对整数类、整数列有效,数值会自动加1。
- primary key:关键字用于定义列为主键。 表示约束(一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一);可以加速查找
- unique: 唯一索引,可以由多个键组成,约束(可以为空但是不能重复)加速查找
- foreign key:外键;关联两张表,保证数据的一致性和实现一些级联操作
- engine: 设置存储引擎;innodb,表示事务(如果一件事务没执行完被中断,会回滚到事务执行之前);myisam,支持全局索引,存储速度更快
- charset: 设置编码。



3.1.1 数据类型type
整形
| 类型 | 大小 | 范围(有符号) | 范围(无符号,字符类型后加 unsigned) | 用途 | 备注 |
| TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
特别的: MySQL中无布尔值,使用tinyint(1)构造。 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 | |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 | |
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 | |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 | |
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
非准确小数值,数值越长越不准确; |
| DOUBLE | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
非准确小数值,数值越长越不准确; |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 | 准确表示小数,decimal(m,d),m表示数值的总位数(不包括符号),d表示小数后位数 |
字符型
| 类型 | 大小 | 用途 | 备注 |
|---|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
varchar数据类型用于变长的字符串,可以包含最多达255个字符。 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 | |
| TINYTEXT | 0-255 bytes | 短文本字符串 | |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 | |
| TEXT | 0-65 535 bytes | 长文本数据 | |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 | |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 | |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 | |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
时间
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 |
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
其他类型
| 类型 | 说明 |
| enum | 例:enum('red','blue','black'),说明该列的值只能是'red'或'blue'或'black' |
| set | 例:set('a','b','c'),说明该列的值只能由'a','b','c'组成,如’ab','bac' |
3.1.2 设置外键
外键可以一对一,一对多,或者多对多;外键的使用条件:
- 两个表必须是InnoDB表,MyISAM表暂时不支持外键;
- 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显示建立;
- 外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以;
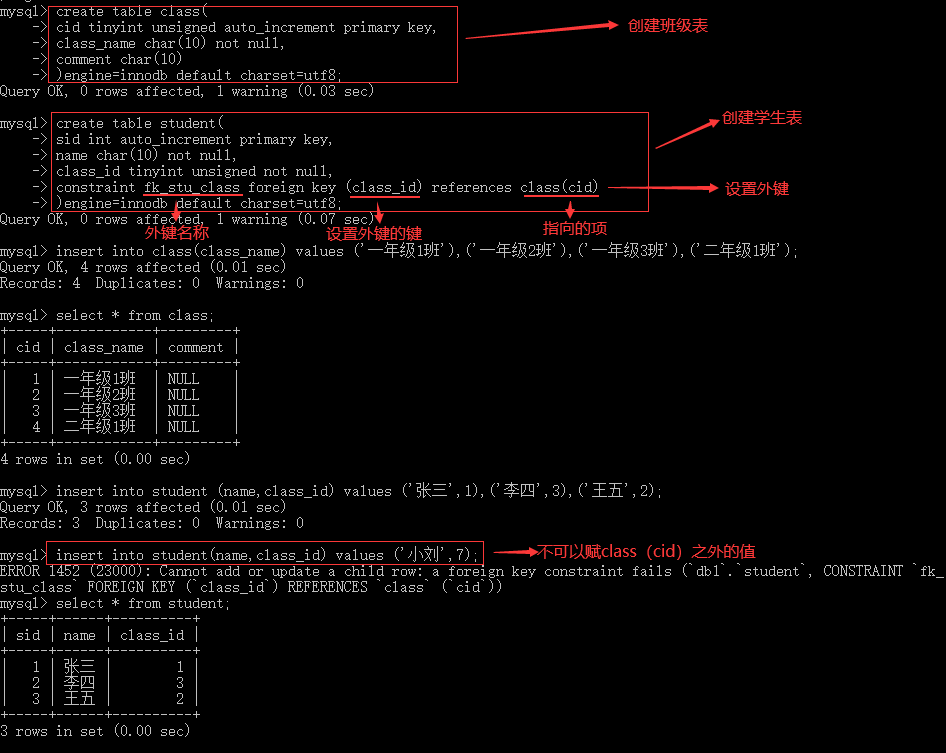

3.1.3 设置主键

3.1.4 设置唯一索引

3.1.5 查看数据表
--查看创建表 show create table table_name; show create table table_name \G; --查看数据表的列 show full columns from table_name; desc table_name;
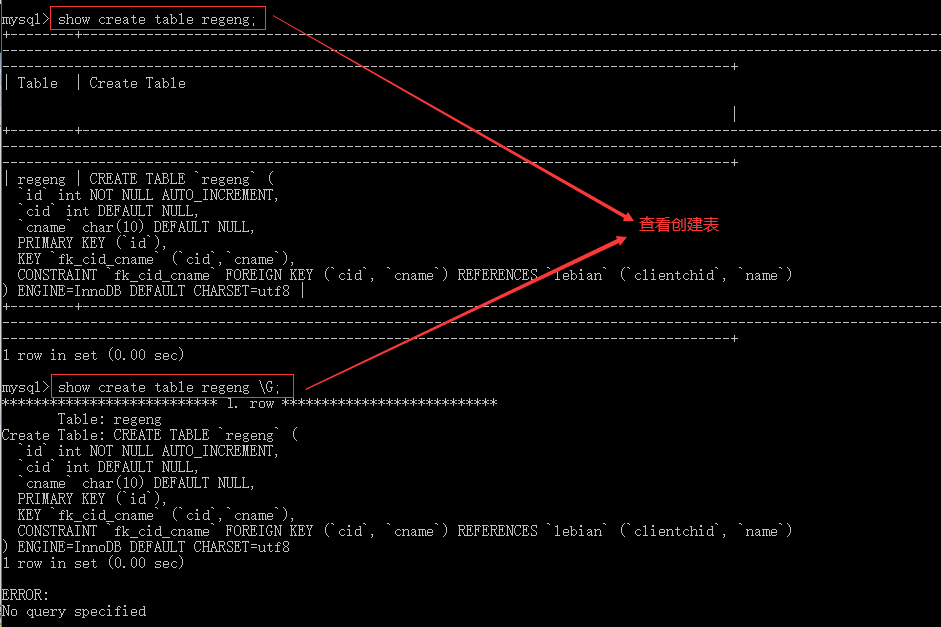


3.1.6 自增的起始和步长



3.2 修改数据表
--删除数据表的列;如果只有一列,删除会报错 alter table table_name drop column_name; --增加数据表的列,默认添加的列在表的最后 alter table table_name add column_name type; --column可以添加的属性与创建表中一样 alter table table_name add column_name1 type,column_name2 type; --一次添加多个列 alter table table_name add column_name first; --添加的数据放在表的第一个 alter table table_name add column_name1 after column_name2; --添加的列放在column_name2列之后 --修改数据表列的属性 alter table table_name modify column_name 属性; --修改数据表的列名 alter table table_name change column_name_old column_name_new 属性; --重命名数据表 alter table table_name_old rename table_name_new; --删除主键 alter table table_name drop primary key; --增加主键 alter table table_name add primary key (column_name); --修改默认值 alter table table_name alter column_name set default 默认值; --删除默认值 alter table table_name alter column_name drop default;
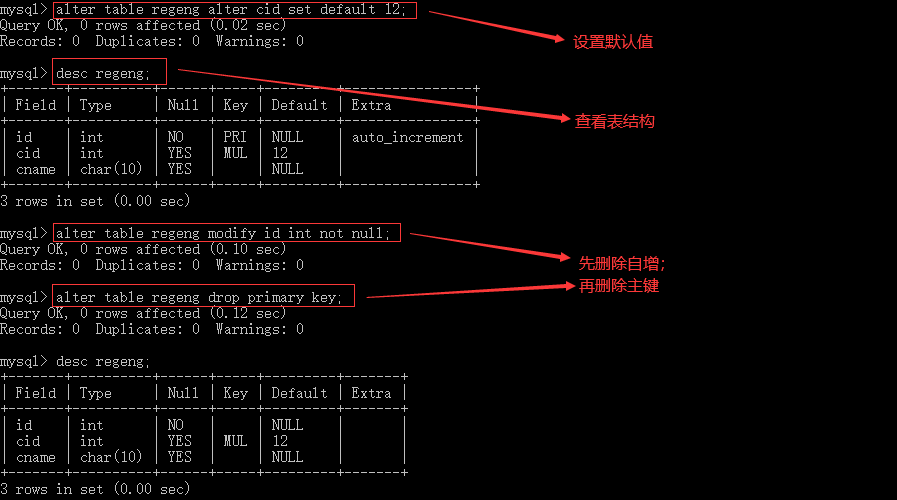
3.3删除表
--删除表 drop table table_name;

4. 数据行操作
4.1 条件从句
4.1.1 where 子句
使用主键来作为 WHERE 子句的条件查询是非常快速的。如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。
| 操作符 | 描述 | 实例 |
| = | 相等 | where id=1 |
| !=,<> | 不等 | where id!=1 |
| <,<=,>,>= | 小于,小于等于,大于,小于等于 | where id > 1 |
| in | 在其中 | where id in (1,2,3); where id in (select nid from t1) |
| not in | 不在其中 | where id not in (1,2,3) |
| between..and.. | 在什么之间 | where id between 1 and 10;闭区间包括1和10 |
| and | 连接2个条件语句,都满足为True | where id=1 and name='Lucy' |
| or | 连接2个条件语句,都不满足为False | where id=1 or name='Lucy' |
| like | 通配符使用;%可替代多个字符,_替代一个字符 | where name like '%cy'; where name like 'Luc_' |
4.1.2 having子句
如果对分组之后的数据再次筛选,使用having;having子句在where子句的后面
4.2 三元运算
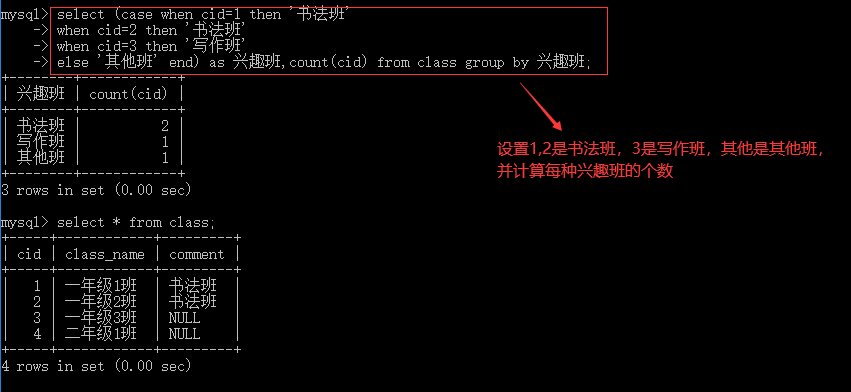
4.2.1 case
--当field=value1时,结果为result1,当field=value2时,结果为result2,否则结果为result3
case field
when value1 then result1
when value2 then result2
...
else result3 end
--当满足赛选条件1时,结果为result1,当满足筛选条件2时,结果为result2,否则结果为result3
case when 筛选条件1 then result1 when 筛选条件2 then result2
... else result3 end
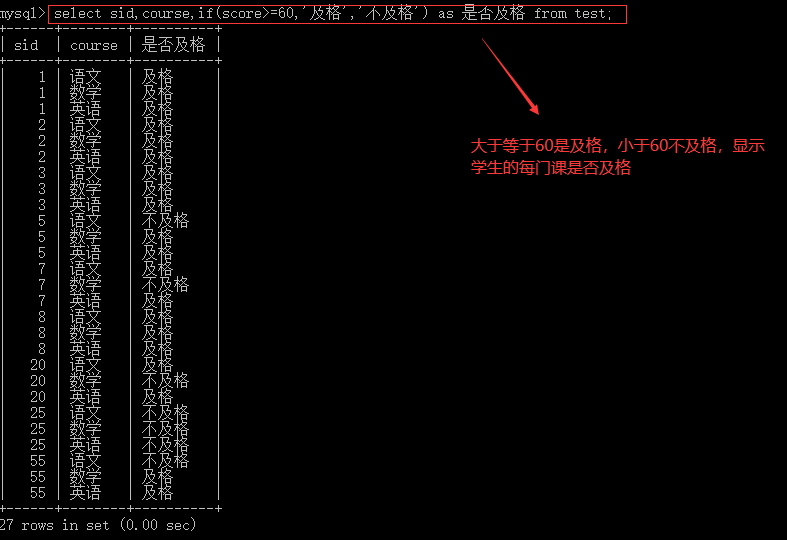
4.2.2 if
--如果条件1为true,则result1,否则result2 if(条件1,result1,result2) --如果field为空则result1,否则result2 if(isnull(field),result1,result2)
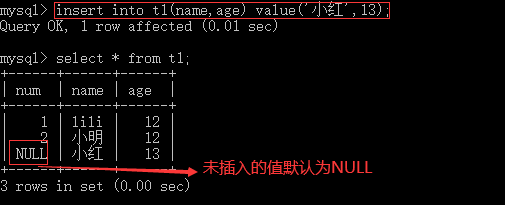
4.3 增
--增加数据 insert into table_name (column_name1,column_name2) values (值1,值2); insert into table_name values (值1,值2,值3); --值必须与column_name一一对应 --一次增加多条数据 insert into table_name (column_name1,column_name2) values (值1,值2),(值3,值4); --复制t2表中id,name数据 insert into table_name1 (column_name1,column_name2) select column_name3,column_name4 from table_name2;



4.4 删
--清空表内数据 delete from table_name; --清空数据后再次插入数据,自增列会接着之前的顺序 truncate table table_name; --清空数据后再次插入数据,自增列会重新开始;效率比delete高 --删除某行数据 delete from table_name where子句; --清空某一列的数据 update table_name set field=null;


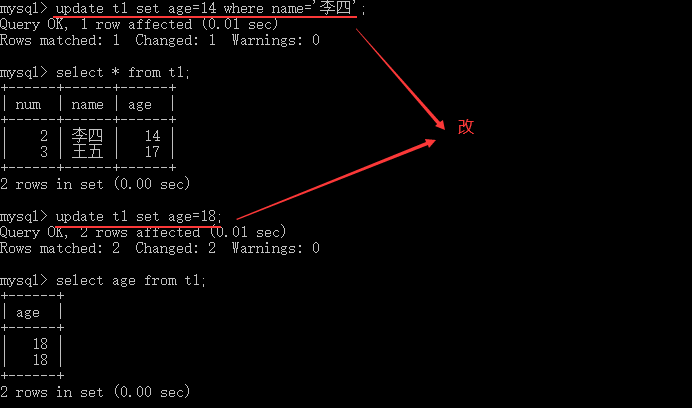
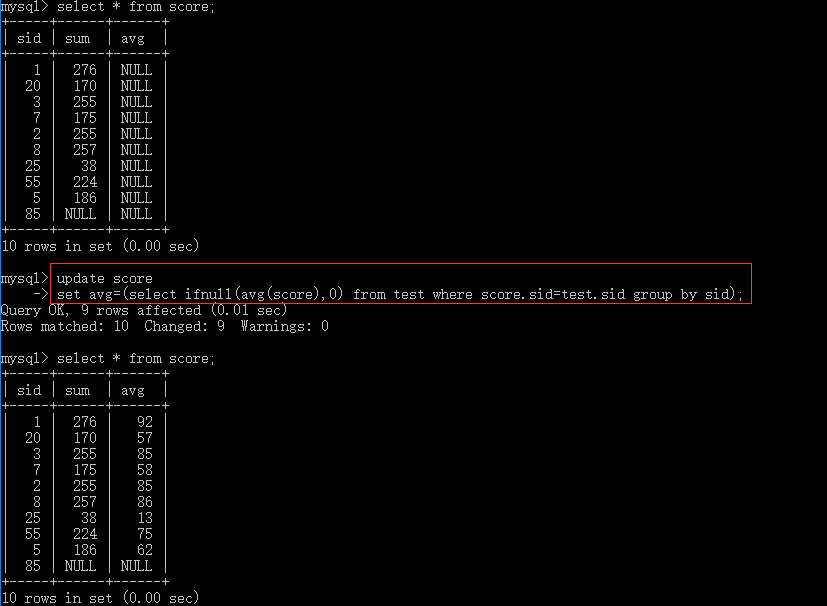
4.5 改
--单表更新 update table_name set filed1=value1,filed2=values2 where子句; --多表联合更新 update table_name1,table_name2 set table_name1.field1=table_name2.field2 where子句; update table_name1 left join table_name2 on 条件子句 set table_name1.field1=table_name2.field2; update table_name set field=查询语句;

4.6 查
--查全部 select * from t1; --条件查询 select id,name form t1 where id=1; --查看前十条 select id,name from t1 limit 10; select id,name form t1 limit 0,10; --查看21-30条; limit 起始条数-1,查看条数 select * from t1 limit 20,10; select * from t1 limit 10 offset 20; --按id从小到大排序;默认从小到大排序 select * from t1 order by id; select * from t1 order by id asc; --按id从大到小排序; select * from t1 order by id desc; --取后10条数据;先倒序排列,再取前10条 select * from t1 order by id desc limit 10; --先按age倒序排序,如果age重复再按照id排列 select * from t1 order by age desc,id asc
4.6.1 分组
--分组查询 select field1,func(field2) from table_name where 筛选条件 group by field1 having 筛选条件;
- 和分组函数一同查询的字段必须是group by后出现的字段
- 聚合函数:count(计数),count(field)如果field中有null不计入,count(*),max(最大值),min(最小值),sum(和),avg(平均值)
- 如果要对聚合函数的结果进行二次筛选必须使用having.
- 分组可以按单个字段也可以按多个字段
- 可以搭配着排序使用
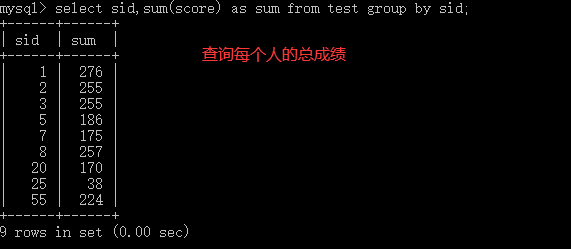
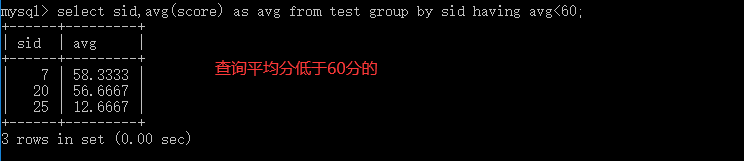



4.6.2 左右连表
连表如果没有筛选条件,会产生(表1的数据条数*表2的数据条数)条数据;
--左右连表 select * from table_name1,table_name2 where 筛选条件;--显示表1和表2共有的部分 select * from table_name1 left join table_name2 on 筛选条件;--表1中的数据全显示,表2中多余的数据不显示,不足显示null select * from table_name1right join table_name2 on 筛选条件; --表2中的数据全显示,表1中多余的数据不显示,不足显示null
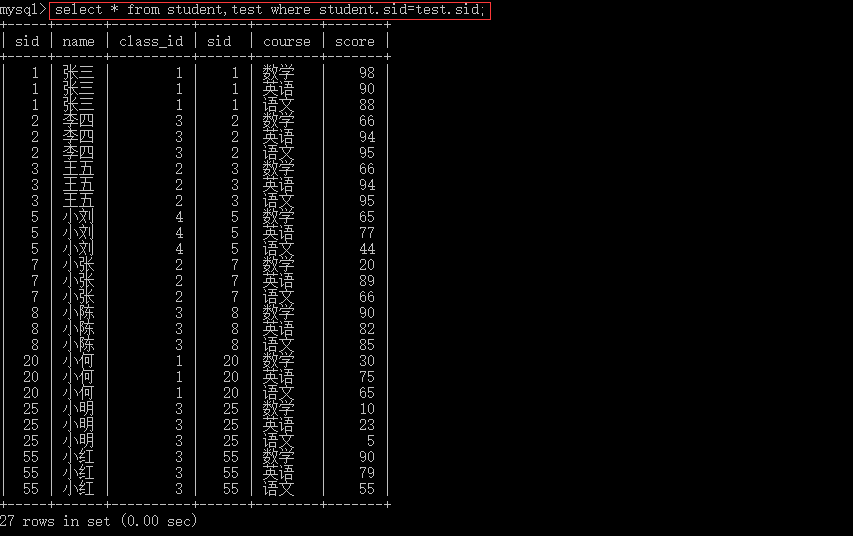
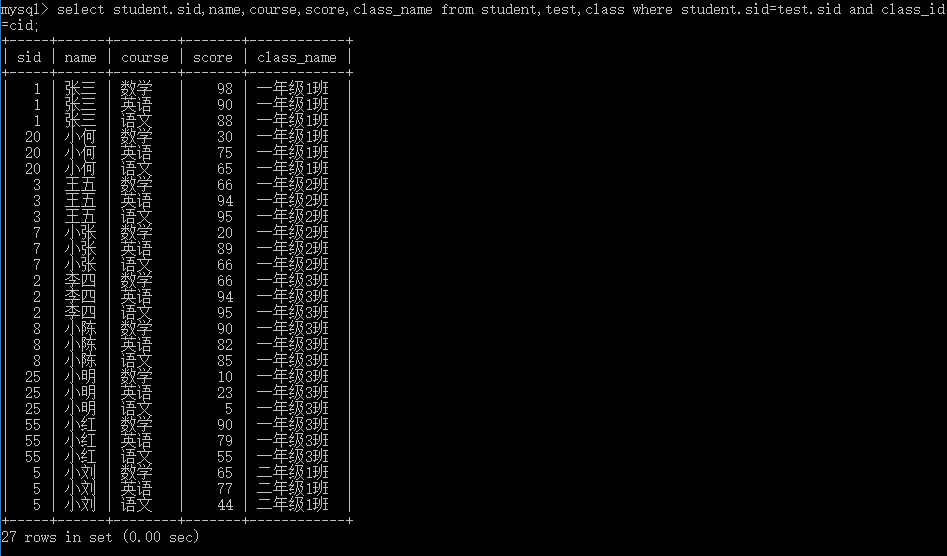
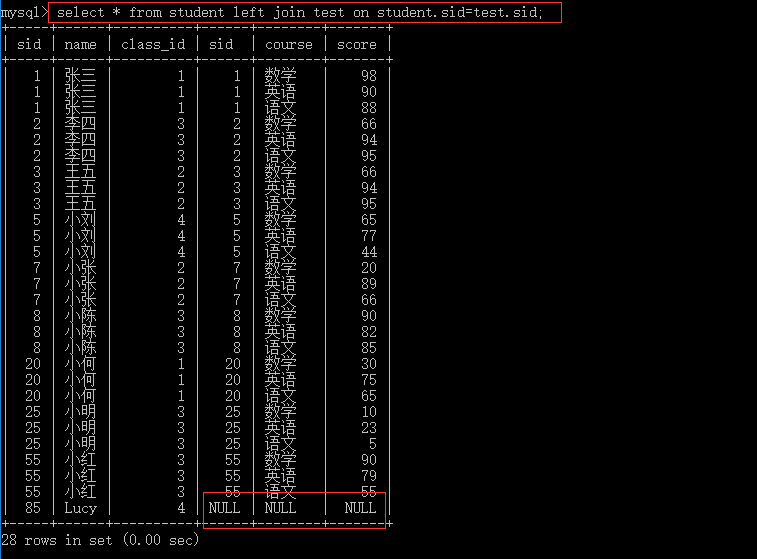
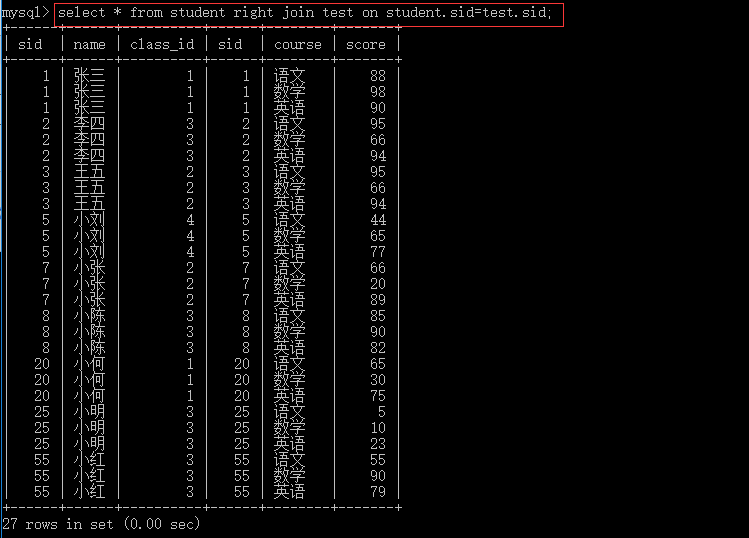
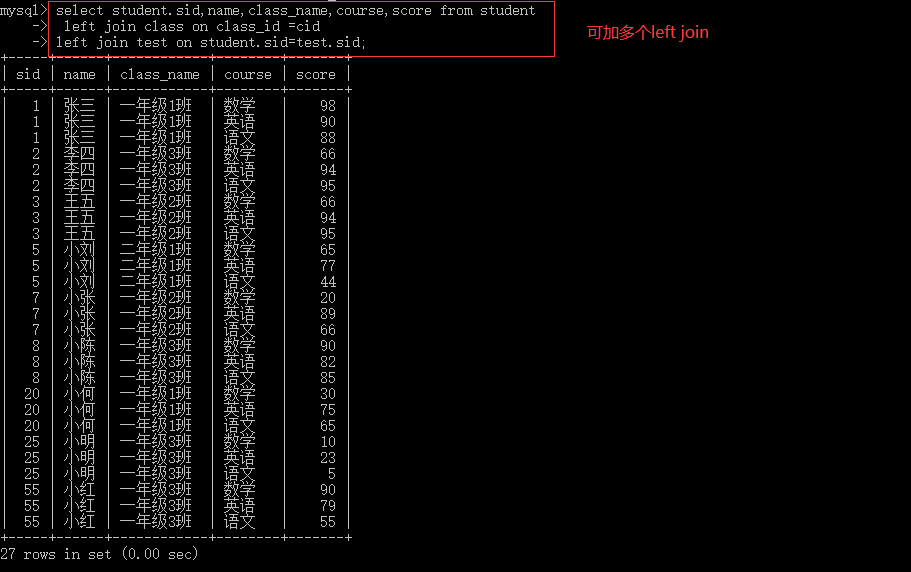
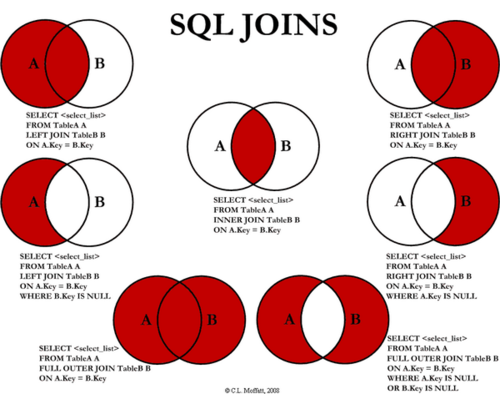
4.6.3 上下连表
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据
--上下连表 select field1,field2 from table_name1 where 筛选条件 union select field3,field4 from table_name1 where 筛选条件; --自动去重 select field1,field2 from table_name1 where 筛选条件 union all select field3,field4 from table_name1 where 筛选条件; --不去重


