python---re模块
一、正则表达式
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,它对所有的语言都通用。
1.常用元字符
| 字符 | 说明 |
| . | 匹配除换行符(\n)外的所有字符;如果DOTALL已指定标志,则它匹配包括换行符在内的任何字符 |
| \w | 匹配数字或字母或下划线,相当于[a-zA-Z0-9_] |
| \W | 匹配任意非数字、字母、下划线、汉字的字符[^a-zA-Z0-9_] |
| \s | 匹配任意的空白符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v] |
| \S | 匹配任意非空白符;等价于[^\f\n\r\t\v] |
| \d | 匹配数字,相当于[0-9] |
| \D | 匹配非数字 ,相当于[^0-9] |
| \n | 匹配换行符 |
| \f | 匹配一个换页 |
| \r | 匹配一个回车 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \b | 匹配字符串的开始或结束 |
| \B | 匹配非字符串的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| a|b | 匹配a或是b |
| () | 匹配括号内的表达式,也表示一个组;()内的字符是and的关系 |
| [...] | 匹配[]内字符组中的字符;[]内的字符是or的关系;例[abc]匹配a或b或c;[a-z]匹配小写字母;[0-9]匹配数字;[a-zA-Z0-9]匹配任意字母数字 |
| [^...] | ^放在[]内,表示非;匹配除了[]内字符组中的所有字符 |
2.常用限定符
| 代码 | 说明 |
| * | 重复0次或是多次,默认贪婪模式(尽可能匹配多的次数);可以匹配0次,match()和search()不会返回None,会返回"" |
| + | 重复1次或是多次,默认贪婪模式 |
| ? | 重复0次或是1次,默认贪婪模式 |
| *?/+?/?? | 非贪婪模式,尽可能匹配少的次数 |
| {n} | 重复n次 |
| {n,} | 重复n次或是更多次,默认贪婪模式 |
| {n,m} | 重复n到m次,包括n次和m次,默认贪婪模式 |
二、re模块
1.re.search(pattern, string, flags=0)
扫描整个string,找到匹配样式的第一个位置,并返回一个相应的匹配对象。如果没有匹配,就返回一个None ;
- pattern:正则表达式
- string:被匹配的字符串
- flags:可选匹配标志;正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志;以下是部分修饰符:
| 修饰符 | 描述 |
| re.I(IGNORECASE) | 是匹配对大小写不敏感 |
| re.S(DOTALL) | 使.可以匹配任意字符,包含\n |
| re.M | 多行匹配,影响^和$ |
| re.X | 允许编写更易于理解的表达式,通过分段和注释 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
实例
import re str = "abacad" r = re.search("a.",str) print(r) #<_sre.SRE_Match object; span=(0, 2), match='ab'>; 返回的匹配对象 print(r.span()) #(0, 2); 返回匹配字符串的位置,左闭右开 print(r.group()) #ab;整个匹配的字符串 print(r.groups()) #();组 r1 = re.search("a.*",str) #贪婪匹配,匹配尽可能多的次数 print(r1) #<_sre.SRE_Match object; span=(0, 6), match='abacad'>; r2 = re.search("a.*?",str) #加?变成非贪婪匹配,匹配尽可能少的次数 print(r2) #<_sre.SRE_Match object; span=(0, 1), match='a'>;
1.1 匹配对象Match
匹配对象总是有一个布尔值 True。如果没有匹配的话 match()和 search() 返回 None 所以你可以简单的用 if 语句来判断是否匹配
match = re.match(pattern,string) if match: process(match)
- Match.group([group1,...]):返回一个或是多个匹配的子组; 如果只有一个参数,就返回一个字符串,如果有多个参数,就返回一个元组; group()/group(0)返回整个匹配的字符串,group(1)表示返回第一个组,group(1,2)返回第一个组和第二个组组成的元组
- Match.groups(deflaut=None):返回一个元组,包括所有匹配的组,default参数用于不参与匹配的情况,默认为None
- Match.groupdict(default=None):返回一个字典,包含所有命名组,key是组名;default参数用于不参与匹配的组合,默认为None
- Match.start([group])/Match.end([group]):返回字符串开始匹配/结束匹配的位置(从0开始,开始是闭区间,结束时开区间);group默认为0,表示整个匹配的字符串;start(1)表示第一个组的开始位置,如果组没有匹配,返回-1
- Match.span([group]):返回一个元组;对于一个匹配对象m,返回(m.start(group),m.end(group));group默认为0,如果group没有在这个匹配中,就返回(-1,-1)
- Match.pos:返回正则引擎开始在字符串搜索第一个匹配的索引位置
- Match.endpos:返回正则引擎在结束搜索第一个匹配的索引位置
- Match.lastindex:返回捕获组的最后一个索引值,如果没有组,返回None
- Match.lastgroup:返回最后一个命名组的名字,如果没有就返回None
- Match.re:返回正则对象
- Match.string:返回被匹配的字符串
import re #如果一个组匹配成功多次,就只返回最后一个匹配 m = re.search(r"(..)+","a1b2c3") print(m) #匹配对象,<_sre.SRE_Match object; span=(0, 6), match='a1b2c3'> print(m.group(0)) #整个匹配的字符串,a1b2c3 print(m.group(1)) #第一个组,c3 print(m[0]) #整个匹配的字符串,a1b2c3 print(m[1]) #第一个组,c3 print(m.groups()) #所有组,('c3',) print(m.start()) #开始位置,0 print(m.start(1)) #第一个组开始位置,4 print(m.span(1)) #第一个组位置,(4, 6) print(m.pos) #正则开始搜索位置,0 print(m.endpos) #正则结束搜素位置,6 print(m.lastindex) #最后一个组的索引,1 print(m.re) #正则对象,re.compile('(..)+') print(m.string) #被匹配的字符串,a1b2c3
2.re.match(pattern,string,flags=0)
从string的开始位置开始匹配正则表达式样式,匹配成功返回一个相应的匹配对象 ,匹配失败,就返回None
import re str = "abacad" r = re.match("a.",str) print(r) #<_sre.SRE_Match object; span=(0, 2), match='ab'>; 返回的匹配对象 print(r.span()) #(0, 2); 返回匹配字符串的位置,左闭右开 print(r.group()) #ab;匹配的对象 r1 = re.match("b",str) #开头不能匹配到b,返回None print(r1) #None
3.re,fullmatch(pattern,string,flags=0)
如果整个string匹配到正则表达式样式,就返回一个相应的匹配对象 。 否则就返回一个None
import re str = "abacad" #fullmatch() r= re.fullmatch("a.",str) print(r) #None r1= re.fullmatch("a.*",str) print(r1) #<_sre.SRE_Match object; span=(0, 6), match='abacad'>
4. re.split(pattern,string,maxsplit=0,flags=0)
用pattern分开string ,返回一个列表; 如果在pattern中捕获到括号,那么所有的组里的文字也会包含在列表里。如果maxsplit非零, 最多进行maxsplit次分隔, 剩下的字符全部返回到列表的最后一个元素。
#re.split,如果字符串的开头或结尾匹配到了,返回的列表的第一个元素或是最后一个元素是空字符串 import re str = "abcdabcdeabcdef" s = re.split("abc",str) print(s) s1 = re.split("a(bc)",str) print(s1)

5. re.findall(pattern,string,flags=0)
从左到右在string中找到所有匹配正则表达式的子串,并返回一个列表,没有匹配返回空列表。如果样式里存在一到多个组,就返回一个组合列表;就是一个元组的列表(如果样式里有超过一个组合的话)。空匹配也会包含在结果里。
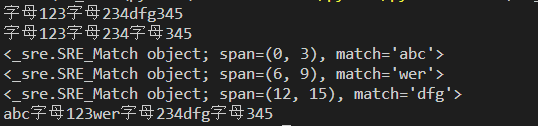
#findall,如果正则表达式里面没有组,返回的是整个正则匹配的字符串; #如果正则里面有组,则返回匹配组的字符串;如果正则里有多个组,则用元组包裹 import re str = "abc123wer234dfg345" r = re.findall(r"\D\d+",str) print(r) r1 = re.findall(r"(\D)\d+",str) print(r1) r2 = re.findall(r"(\D)(\d)\d+",str) print(r2)

6. re.sub(pattern,repl,string,count=0,flags=0)
用repl替换pattern匹配的字符串(匹配一个替换一个),返回替换后的字符串,如果没有匹配返回原字符串
repl:可以是字符串也可以是函数;如果是字符串,其中的反斜杠转义序列会被处理,例如\n会被转移成换行符,\1会用样式中的匹配到的第一组子串来替换;如果是函数,参数会调用pattern的match对象
count:模式匹配后替换的最大次数;默认是0,全部替换
import re #repl是字符串 str = "abc123wer234dfg345" s = re.sub("[a-z]+","字母",str,2) print(s) s1 = re.sub("([a-z]{2})[a-z]","字母",str) #会替换整个正则匹配的字符串,而不是括号内的子串 print(s1) #repl是函数 def f(a): print(a) return a.group()+"字母" s2 = re.sub("[a-z]+",f,str) print(s2)
7. re.escape(string) :对字符串内的特殊字符串进行转义
import re e = re.escape("http://www.baidu.com") print(e) #http\:\/\/www\.baidu\.com
8. re.compile(pattern [,flags])
编译正则表达式,生成一个正则表达式(pattern)对象;如果一个正则表达式会多次匹配,使用这种方式
import re str = "abc123wer234dfg345" pattern = re.compile(r"\D(\d)\d+") print(pattern) #match方法 m = pattern.match(str) print(m) #None #search方法 s = pattern.search(str) print(s) #<_sre.SRE_Match object; span=(2, 6), match='c123'> #findall方法 f = pattern.findall(str) print(f) #['1', '2', '3'] #sub方法,把匹配的字符串替换成第一个组 s1 = pattern.sub(r"\1",str) print(s1) #ab1we2df3 print(pattern.groups) #1,pattern对象的组的对象 print(pattern.pattern) #\D(\d)\d+,打印写的正则表达式
三、其他正则表达式
1.分组
| (...) | 分组匹配,从左到右,每匹配一个分组,索引+1 |
| \number | 例\1匹配第一个组,这个特殊序列只能匹配前面99个组合,如果数字的开头是0或是三位数,会代表八进制数 |
| \g<number> | 例\g<1>匹配第一个组,不能直接用于正则表达式中,可以用于sub中repl |
| (?P<name>...) | 命名组合 |
| (?P=name) | 匹配上面的命名组合;虽然在括号内,但是不是一个组 |
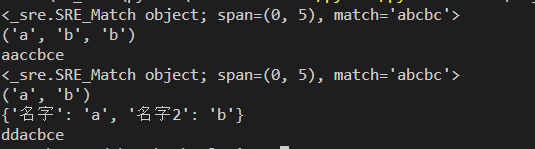
import re str = "abcbce" r = re.search(r"(a)(b)\w(\2)\w",str) #\2表示第二个组b print(r) print(r.groups()) # r1 = re.search(r"(a)(b)\w(\g<2>)\w",str) #此种方式会报错sre_constants.error: bad escape \g at position 9 # print(r1) r1 = re.sub(r"(a)(b)","a\g<1>c",str) print(r1) r2= re.search(r"(?P<名字>a)(?P<名字2>b)\w(?P=名字2)\w",str) print(r2) print(r2.groups()) print(r2.groupdict()) r3= re.sub(r"(?P<名字>a)(?P<名字2>b)","dd\g<名字>",str) print(r3)
2.特殊构造
| (?:...) | ()里面有?:表示不是分组 |
| (?aiLmsux) | 字符对正则表达式设置以下标记 re.A (只匹配ASCII字符), re.I (忽略大小写), re.L (语言依赖), re.M (多行模式), re.S (点dot匹配全部字符), re.U (Unicode匹配), and re.X (冗长模式) |
| (?#...) | 注释,里面的内容会被忽略 |
| (?=...) | 表示匹配...的表达式,对后进行匹配 |
| (?!...) | 表示不匹配...的表达式,对后进行匹配 |
| (?(id/name)yes-pattern|no-pattern) | 如果id/name表示的组匹配成功,则使用yes-pattern匹配,否则使用no-pattern匹配 |
import re #(?:...)表示()里面的不是组 r = re.search(r"(?:a)bc","abcd") print(r) #<_sre.SRE_Match object; span=(0, 3), match='abc'> print(r.groups()) #() #(?=...)表示匹配...的表达式;对后面进行匹配 pattern = re.compile(r"\w(?=\d)") r1 = pattern.findall("abc123efg456") print(r1) #['c', '1', '2', 'g', '4', '5'] #(?<=...)表示匹配...的表达式,对前进行匹配 r2 = re.findall(r"(?<=\d)\w","abc132efg456") print(r2) #['3', '2', 'e', '5', '6'] #(?!...)表示不匹配...表达式,对后进行匹配 r4 = re.findall(r"\w(?!\d)","abc123efg456") print(r4) #['a', 'b', '3', 'e', 'f', '6'] #(?<!...)表示不匹配...表达式,对前进行匹配 r5 = re.findall(r"(?<!\d)\w","abc132efg456") print(r5) #['a', 'b', 'c', '1', 'f', 'g', '4'] #(?(id/name)yes-pattern|no-pattern) 如果id/name表示的组匹配,就yes-pattern;不匹配就no-pattern pattern = re.compile(r"(a)\w(?(1)\d|\w)") r6 = pattern.search("abca12345") print(r6) #<_sre.SRE_Match object; span=(3, 6), match='a12'> r7 = pattern.search("abcdefg") print(r7) #None #(?i) #忽略大小写 r8 = re.findall(r"(?i)abc","abcAbcABC") print(r8) #['abc', 'Abc', 'ABC']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号