
Python接口(一)---requests
一、介绍
requests库是用python编写的,基于urllib,采用Apache2 License开源协议封装的HTTP库。
二、requests安装
pip install requests
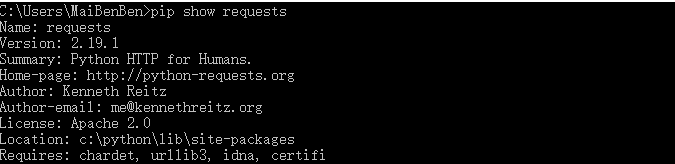
pip show requests来查看requests的信息
三、发送请求
HTTP的请求方法GET(查),POST(增),PUT(改),DELETE(删),HEAD,OPTIONS等
1.发送一个get请求
1.1以请求我的博客地址为例
import requests r = requests.get("https://www.cnblogs.com/he-202007") print(r.status_code) #获取返回的状态码 print(r.text) #获取返回的文本

1.2.发送有参数的请求,以博客园搜索我的博客名为例
import requests
param = {"w":"小测试00"} r = requests.get("https://zzk.cnblogs.com/s/blogpost",params = param) print(r.status_code) print(r.text)

2.发送一个POST请求
POST请求根据发送的实体内容的格式不同(content-type),使用不同的参数
2.1.以博客园中关注他人博客为例,content-type:application/x-www-form-urlencoded; charset=UTF-8,使用data
2.2.Content-Type:application/json使用json
在python中,dict和json字符串虽然长得一样,但是数据格式序列化还是有一定区别;
如果需要传递的主体信息是json格式,就是用json,如果使用data可以导入json,将dict转换成json data = json.dumps(dict)
2.3.发送一个文件
博客园上传头像为例,content-type:multipart/form-data,使用files
import requests url = "https://upload.cnblogs.com/avatar/upload" header = {"cookie": "***" }
image = {"file": ("pic.png",open(r"E:\pic.png","rb"),"image/png")} #文件名,open打开的文件的二进制流,Content-Type对应的文件类型;可以传递多个文件
#image = [("file", ("pic.png",open(r"E:\pic.png","rb"),"image/png"))] #列表元组类型;可以传递多个文件
r = requests.post(url, headers = header, files = image) #files参数是可以接受很多种形式的数据,最基本的2种形式为字典类型和元祖列表类型
print(r.status_code)
print(r.text)
3.发送一个PUT请求
以修改博客园收藏的文章的摘要为例
import requests url = "https://wz.cnblogs.com/api/wz" header = { "cookie":"***" } payload = { "wzLinkId":6332142, "url":"https://www.cnblogs.com/edisonchou/p/my_experiences_on_digital_transformation_part2.html", "title":"我在传统行业做数字化转型(2)技术篇 - EdisonZhou - 博客园", "tags":"测试", "summary":"22222" } r = requests.put(url,headers= header, json = payload) print(r.status_code) print(r.json())
4.发送一个DELETE请求
以博客园取消收藏的文章为例
import requests
url = "https://wz.cnblogs.com/api/wz/6332142" header = {"cookie" : "***"} r = requests.delete(url, headers = header) print(r.status_code) print(r.text)
5.发送一个HEAD请求
以获取下载百度图片的信息为例
import requests url = "https://imgstat.baidu.com/9.gif?_dev=pc&samplekey=&interval=4.57&page=detail&sid=863cbd748f1bc733121967646c913f96a04ed04a&word=%E5%A3%81%E7%BA%B8&cs=1588620919,359805583&_=1605595039967" r= requests.head(url) print(r.status_code) print(r.headers)
6.发送一个options请求
以博客园上传图片前的option请求为例
import requests url = "https://upload.cnblogs.com/avatar/upload" header = { "Access-Control-Request-Headers": "x-requested-with,x-xsrf-token", "Access-Control-Request-Method": "POST", "Host": "upload.cnblogs.com", "Origin": "https://account.cnblogs.com", "Referer": "https://account.cnblogs.com/settings/account/avatar", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-site" } r = requests.options(url, headers = header) print(r.status_code) #打印204
print(r.raise_for_status()) #打印None print(r.headers)
四、session
requests中的session对象能够跨http请求保持某些参数,即让同一个session对象发送的请求头携带某个指定的参数。当然,最常见的应用是它可以让cookie保持在后续的一串请求中
1.以登陆乐变后台后获取首页信息为例
import requests url = "http://www.loveota.com/login.php" payload = { "email": "aaa", "password": "bbb" } session = requests.session() r = session.post(url, data = payload) print(r.status_code) print(r.text) url1 = "http://www.loveota.com/sdkwelcome.php" r1 = session.get(url1) #获取首页信息,不用再手动加入cookies print(r1.status_code) print(r1.text) session.quit() #结束会话
2.session手动设置cookies
以乐变后台请求首页,再请求热更管理页面为例
import requests url = "http://www.loveota.com/sdkwelcome.php" session = requests.session() #session中2种方法设置cookies #第一种 # cookie = { # "PHPSESSID": "***", # "Hm_lvt_584f2dd935563d257a0c3a34b25a4afc": "1603352944", # "Hm_lvt_0c13eb8745c1855d05fba71ab214e4f8": "1603271638,1605598017", # "Hm_lpvt_0c13eb8745c1855d05fba71ab214e4f8": "1605690548", # "Hm_lpvt_584f2dd935563d257a0c3a34b25a4afc": "1605690550" # } # session.cookies.update(cookie) #第二种 session.cookies.set("PHPSESSID", "***") session.cookies.set("Hm_lvt_584f2dd935563d257a0c3a34b25a4afc", "1603352944") session.cookies.set("Hm_lvt_0c13eb8745c1855d05fba71ab214e4f8", "1603271638,1605598017") session.cookies.set("Hm_lpvt_0c13eb8745c1855d05fba71ab214e4f8", "1605690548") session.cookies.set("Hm_lpvt_584f2dd935563d257a0c3a34b25a4afc", "1605690550") r = session.get(url) print(r.status_code) print(r.text) print(r.request.headers) #请求另一个需要登陆的界面 url1 = "http://www.loveota.com/sdkchannelinfo.php" r1 = session.get(url1) print(r1.status_code) print(r1.text)
3.session设置headers
import requests url = "http://httpbin.org" session = requests.session() #跨请求参数 session.headers.update({"test1":"111"}) #非跨请求参数 r = session.get(url, headers = {"test2":"222"}) print(r.request.headers) r1 = r = session.get(url) print(r.request.headers)

五、获取reaponse结果信息
1.获取状态码
- r.status_code 返回状态码
- r.raise_for_status() #如果状态码不是2XX,会返回一个错误,否则什么都不显示
import requests url = "https://www.cnblogs.com" r = requests.get(url) print(r.status_code) #打印200 print(r.raise_for_status()) #打印None
返回405
import requests url = "https://upload.cnblogs.com/avatar/upload" r = requests.options(url) print(r.status_code) print(r.raise_for_status())
打印的结果

2.获取内容
- r.text #以文本形式解析响应内容,自动根据encoding解码
- r.raw #返回响应原始信息
- r.content #以字节码形式解析响应内容
- r.json() #以json字符串形式解析响应内容,可通过键名获取对应值
以下载百度logo图片为例,使用r.content
import requests url = "https://www.baidu.com/img/bd_logo1.png" r = requests.get(url) with open (r"E:\baidulogo.png","wb") as f : #写入图片 f.write(r.content)
3.获取编码格式
- r.encoding #根据header获取编码信息,如果响应中没有根据请求信息中获取,默认为ISO-8859-1;可以用来设置响应编码
- r.apparent_encoding #根据响应实体信息的内容推断
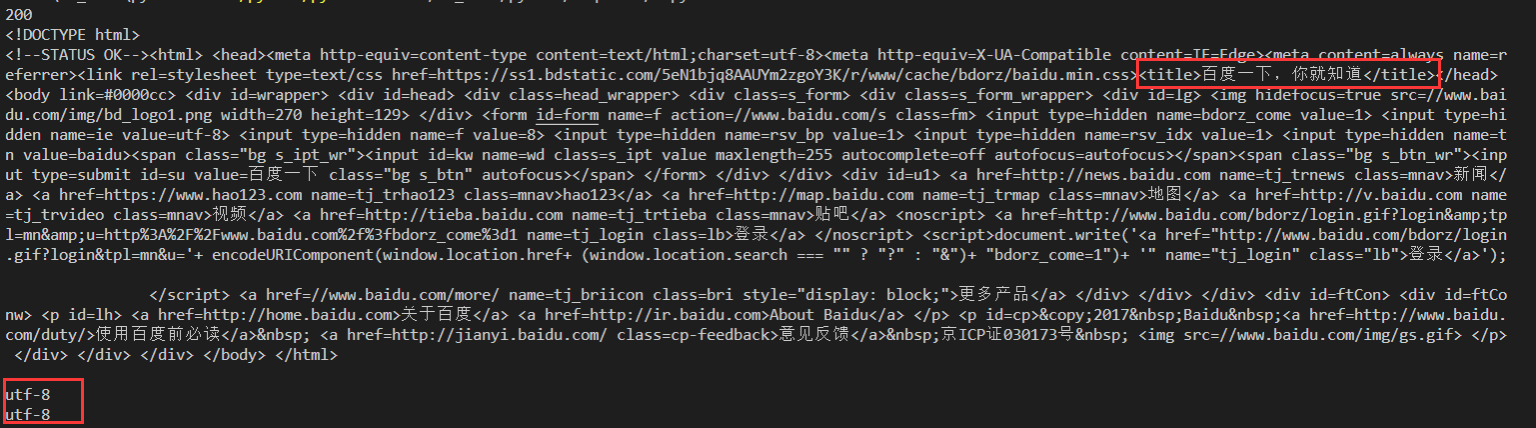
以请求百度首页为例,r.text直接解析中文会乱码,需要设置编码格式

设置编码格式
import requests url = "https://www.baidu.com" r = requests.get(url) print(r.status_code) r.encoding = "utf-8" #设置响应编码 print(r.text) print(r.encoding) print(r.apparent_encoding)
打印结果
4.获取其他内容
- r.url #获取请求url
- r.headers #获取响应首部信息
- r.cookies #获取响应的cookie信息,返回的是一个字典对象,可以通过键名获取对应值
以请求百度首页为例,打印Cookie信息
import requests url = "https://www.baidu.com" r = requests.get(url) print(r.status_code) r.encoding = "utf-8" #设置响应编码 print(r.text) print(r.headers) print(r.cookies) #打印<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]> print(r.cookies["BDORZ"]) #打印27315
设置cookies,字典格式
import requests url = "http://www.loveota.com/sdkwelcome.php" cookie = { "PHPSESSID": "***", "Hm_lvt_584f2dd935563d257a0c3a34b25a4afc": "1603352944", "Hm_lvt_0c13eb8745c1855d05fba71ab214e4f8": "1603271638,1605598017", "Hm_lpvt_0c13eb8745c1855d05fba71ab214e4f8": "1605690548", "Hm_lpvt_584f2dd935563d257a0c3a34b25a4afc": "1605690550" } r = requests.get(url,cookies = cookie) print(r.status_code) print(r.text) print(r.request.headers) #获取请求头信息
5.获取请求的内容
- r.request.headers #获取请求首部信息
六、其他参数
1.verify = False
打开Fiddler之后再使用requests发送HTTPS请求,会报错,提示Caused by SSLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)'),),设置verify = False
以请求百度首页为例
import requests url = "https://www.baidu.com" r = requests.get(url, verify = False) print(r.status_code)
会提示warning,但是请求成功

2.allow_redirects=False #禁止重定向
以请求百度首页为例
import requests url = "http://www.baidu.com" #必须加上headers,不然直接返回200 header = { "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36" } r = requests.get(url, headers = header, allow_redirects=False) print(r.status_code) #打印302(临时重定向) print(r.headers["location"]) #打印https://www.baidu.com/;重定向的地址
