
运营商手机视频流量包业务日志ETL及统计分析
自己做过的项目在这里做一个记录,否则就感觉不是自己的了.一是因为过去时间已经很长了,二是因为当时做得有点粗糙,最后还不了了之了.
话不多说,先大致介绍一下项目背景.以前各大手机视频 App 一般都有运营商的流量包套餐.当用户产生这样的业务行为时,运营商便获取了一系列的用户行为日志.

这条日志是一条获取视频用户手机号码的日志.日志的类型很多,当时做的主要工作是对这个类型的日志做一系列的抽取,清洗,过滤,转换及转存工作.最后,对实时的日志以10分钟为一个时间窗口做简要的统计分析.
要认识这样的项目,最重要的是要厘清整个数据的流向.
首先,原始业务日志无论是实时的还是历史的都保存在服务器日志目录内的 log 文件中,我们使用 Apache Flume 这个工具将原始数据抽取出来.创建一个 Flume Agent ,配置 tail source ,memory channel 以及 kafka sink ,将原始数据先导入我们的大数据集群环境中.把数据首先弄到大数据环境中,这是所有大数据数据处理的开端.一般来说,kafka 集群是大数据环境的门面,所有的集群外部数据一般都是先导入到kafka中.
这个过程中有一个问题,运营商的服务器在运营商的机房内网,跟我们的 hdp 集群环境网络不是互通的.所以我们用了一台机器做网络中转,这台机器分别跟 服务器 及我们的 hdp 集群环境网络相通.
所以总共配置了3个Flume 的 Agent , 第一个为服务器采集端的 agent: tail log文件 source , memory channel , avro sink 到中转机器
第二个为中转机器的agent : avro source ,memory channel,avro sink 到集群环境中的一台机器
第三个为集群环境的某台机器的agent : avro source, memory channel ,kafka sink 到 kafka集群的brokers.
这个流程调试了一段时间,比较纠结,整个流程运行了一段时间后会偶尔挂掉,然后整个数据的传输就断了.
第一个原因是我自己的原因,对 linux 系统还不是很熟练.我ssh到hdp集群上的机器上,run 第三个 flume agent 的时候没有意识到要让进程在后台可靠的运行.这样,当ssh断了的时候,这个agent的运行也会跟着停止.第三个agent挂掉了,前面的两个agent会由于memory channel满了也依次挂掉.所以为了避免ssh的问题,需要在run agent命令的时候,要注意使用 nohup 及 & 标识 .这样 ssh 断掉之后,agent也能继续运行.
第二个原因是沟通的问题.采集端 agent 和中转端 agent 是由业务方的开发人员管理的.我负责管理hdp集群中的这个agent.整个流程3个agent , 3个source 和 3个sink.中间某一段不通畅就会导致agent的挂掉,挂掉某个agent的话,整个传输流程就断了.当时出现问题的时候,多次沟通都没有沟通清楚,反反复复做了很多无用功,其实原因就摆在那里.主要是网络的问题,因为第一个agent是运营商的专用网,并且还是北京异地的机房,它到中转服务器的sink网路不稳定,导致sink没有发出去.sink停止了的话,memory channel容量逐渐变满,导致source 没法正常工作,最终这个agent挂掉了.
最后的表现是每个agent都会抛出一个错误,停止运行.由于沟通的问题,一直没有找到引发错误的源头agent.
还有一个潜在的性能问题.中转的 agent 没有做 load balance .由于采集端的数据量非常大,而且后期针对不同的日志类型,开了好几个不同的agent.数据一下子全部集中到了中转机器的这个agent上,它的memory channel 是很容易跑满的.
不过这个项目的实际情况取决于网络状况,整个流程中,第一个agent的sink 到第二个agent的source是主要瓶颈(取决于网络状况),当这个瓶颈的问题解决了之后,第二个agent的性能就成了主要瓶颈.这个时候就需要构建flume sink的负载均衡了(详见官网:http://flume.apache.org/FlumeUserGuide.html#load-balancing-sink-processor).
现在日志数据已经成功弄到hdp集群环境中了,可以开始下一步了.不过,在正式开始下一步之前,还要提一点,那就是kafka. 上面最终是将日志数据导入到kafka的某个topic中,.对于kafka的topic,要做的是设定好topic的partiions 和 replication-factor. 这个项目用的数值分别是6和2 ,不过这是拍脑袋确定,没有细致研究.主要原因是由于 kafka 的性能实在是太优越了,kafka这里的数据流程基本上不可能成为瓶颈.(kafka很强大,以后也会越来越重要,值得细致研究)
当数据采集到 kafka 集群,也即hdp集群环境中之后,就可以使用大数据的集群环境及相关技术生态对数据进行进一步的处理了. 由于处理数据的起点是kafka,所以全部采用的是流式处理的方式,也即 data pipline,从 kafka 中读取记录,进行逐条的处理. 这里,就要跟大家介绍一个非常非常优秀的开源数据处理及分发系统 ,Apache Nifi .因为后续的大部分工作是使用nifi完成的.
Apache Nifi 是由美国NSA 捐给Apache基金会,最早是NSA内部使用的一个数据处理工具.nifi能够保证数据的可靠性,nifi也能够保证数据的即时性,nifi逐条处理数据的速度非常快.最厉害的是,niifi提供了一个非常简单直观的基于web的用户使用界面.nifi官网上的一句话准确概况了nifi的特点: Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic . 这个system mediation logic 说得非常到位,能够使用nifi画出非常复杂的数据流动逻辑.没错, 是画出来的.
下面这张图是nifi用户界面里面画出来的, 它不仅仅是流程图, 实际上它就是整个处理过程.右键点击start,日志数据的etl就开始了,非常强大.
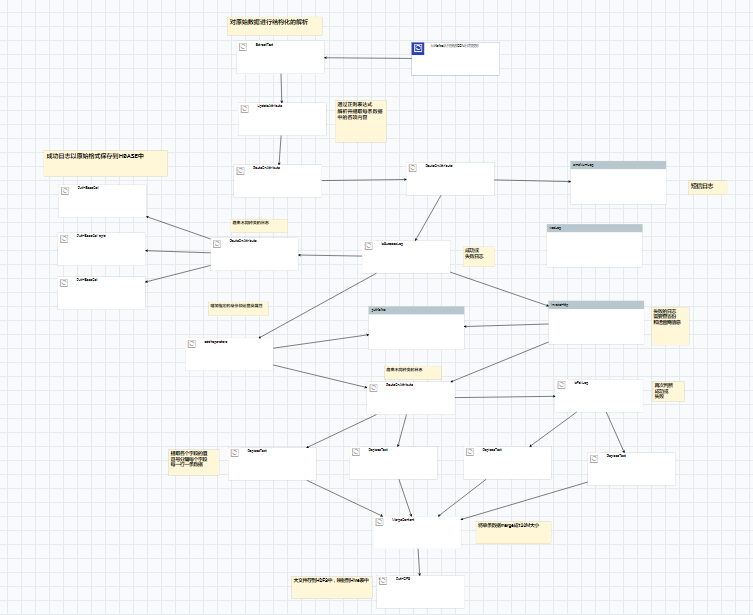
上面每一个方块代表对记录的处理过程,每一个箭头代表记录的流向.日志记录就是一条一条的在这个有向无环图里面流动,从起点开始,经过一个个的处理器经过处理,一直流到目的地. 看起来这个图看起来比较复杂,但实际上做的事情,无外乎就是对日志数据的抽取,过滤,路由,转换,更新,分发这几个事.
图画得这么多,主要是由于业务的需要.
其一,日志文件的格式不统一,即使是同类型的 log 文件.格式也会有细微的差异.这也是不可能统一的.因为日志文件的时间跨度大,由不同的开发人员,按照不同的业务人员需求和当时的约定和口径来开发的.有时候,同样的字段,会有不同格式的值,甚至还要基于记录某个字段的值去做判断.客观上,日志文件的格式是不统一的,甚至有时候不规范.这个时候,就需要非常灵活的处理流程了.nifi的易用性及扩展性就体现在这里了,针对不同的日志文件格式,只需要更改这个流程图就行.加几个处理器,连几个箭头.全部都是在 nifi 的这个界面上通过拖拽完成的.
其二,业务需求的变动性.对于用户行为的日志文件,对于同一份日志记录,同时会有各种不同的业务需求.要做即席查询,要做实时聚合,要做批量查询.要备份表记录.还要触发特定业务处理.所以整个流程图肯定会随着业务需求的增多越来越复杂.能够让流程图随着业务需求的变动而跟着变动本身就是一个非常厉害的事了,无论来了怎样的业务需求,我只需要连箭头,增加新的处理流程,也就是 data flow 就可以了.
接下来,详细看数据的流向.起点是从 kafka 集群中读取日志数据,批量读进来若干条日志记录之后,使用nifi的处理器逐条对日志记录进行处理.让记录在这个图中流动起来.
首先做验证,然后过滤格式错误记录,然后路由不同的日志类型. nifi能做到这些的关键在于它的 flowfile 这个概念. 每一条数据记录进入到nifi中就叫flowfile. 每一个flowfile 由两部分组成,一个是content, 文件内容. 一个是 attributes ,文件属性. 在 nifi 中, 我们可以对文件属性进行增删改查等操作,甚至我们可以使用 nifi 提供的DSL,特定领域语言 对 attributes 进行编程. 这样的设定使得可以对数据记录进行任何想要的逻辑处理. 所以,一般是先把日志记录的内容转换到 flow file 的属性值当中去,然后进行后续的不同处理. 如下图:
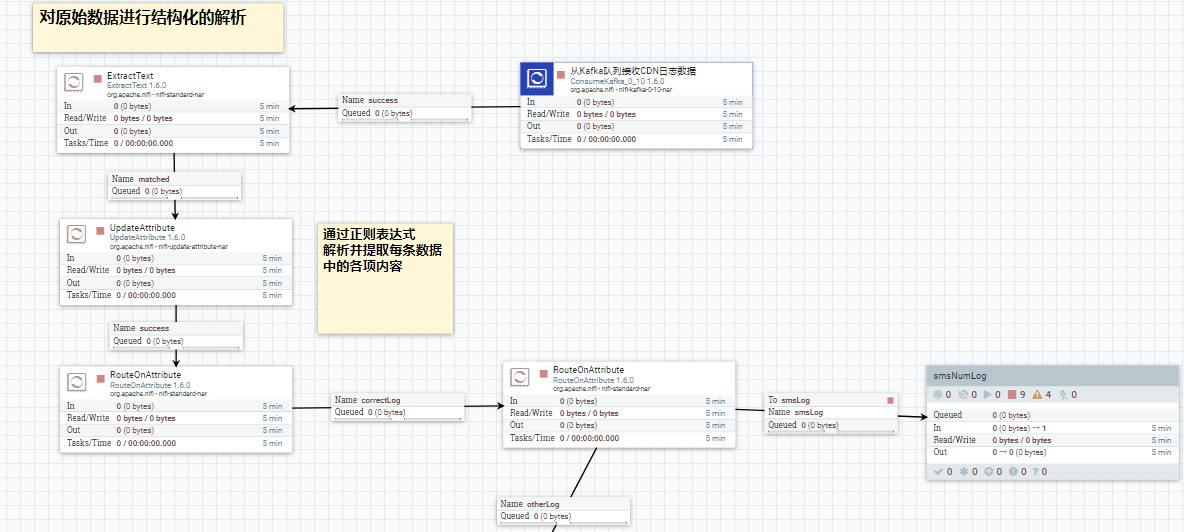
接着继续判断,对于通过网络获取手机号码成功的日志,将原始的日志记录保存到 hbase 中,之后供业务方做即席查询. 如下图:
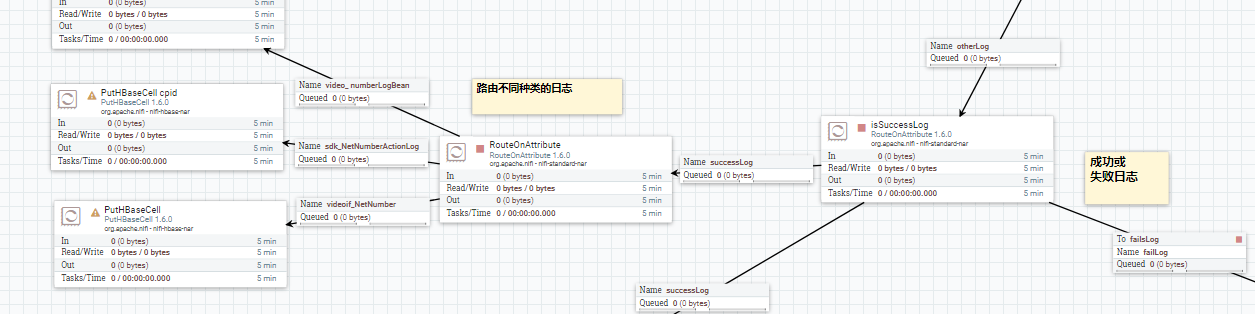
对于获取手机号码失败的日志,手动去查用户的地址和所属运营商信息.这里是强业务相关的,因为属于其他运营商,所以是获取不到号码的.这里的处理真正体现了nifi的强大和灵活.
因为对于失败的日志,实际上是缺少必备字段的.缺少了字段, 这在日志文件批量处理中是多么坑爹的事情.然而使用 nifi 却能很轻松的解决这个问题.直接拿这条记录的用户ip 去调 一个内部的服务化查询接口,把字段查出来.并把值赋给flow file 相应的attribute. 把这样的日志记录变成正常的日志记录后,再汇入到处理的主流程当中,接着流动下去.
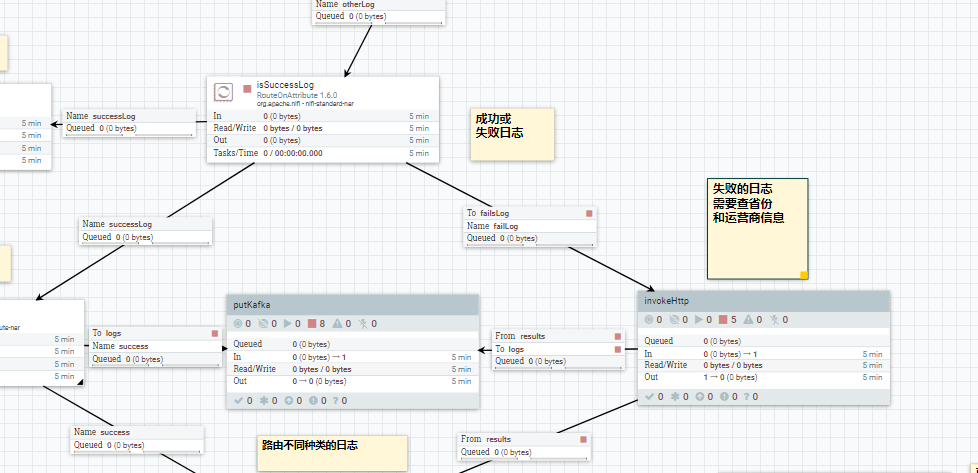
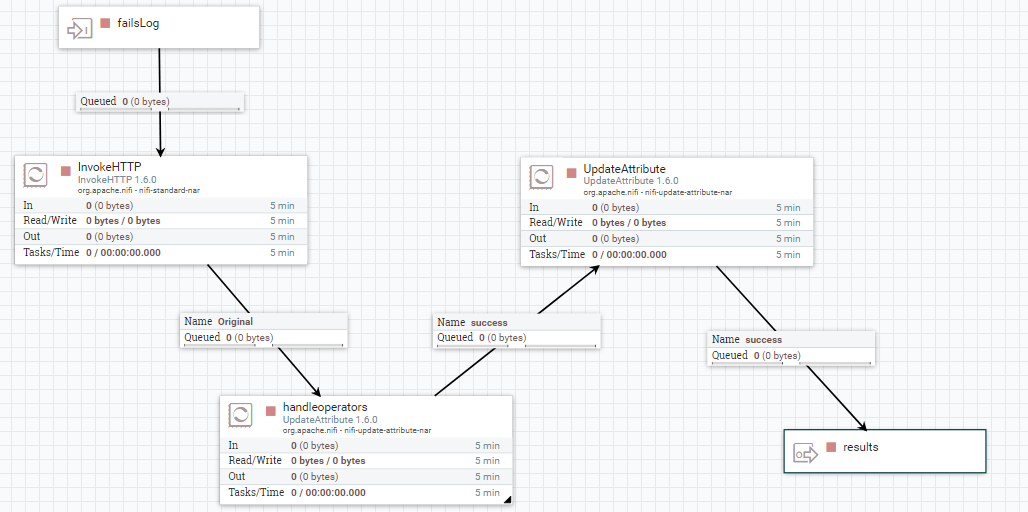
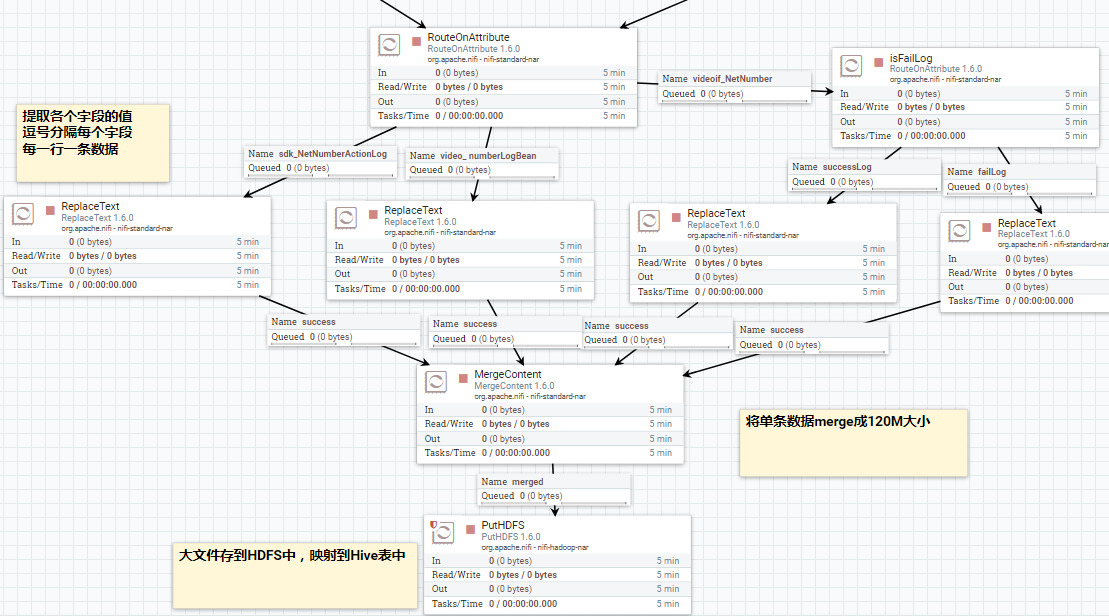
接下的处理流程主要就是分发及转存了.对于同一条日志记录,一份数据要提取字段,将之转成 hive表结构对应的 csv 格式 ,保存到 hdfs 中, 也就是将所有处理好的数据落地到hdp集群环境中去.这是数据清洗后一大终点,也是结果.之后可以拿来直接做其他处理了,比如做批量查询,供其他工具使用(比如 kylin 等),也可以用来做模型训练.因为这里就算是干净的数据了.
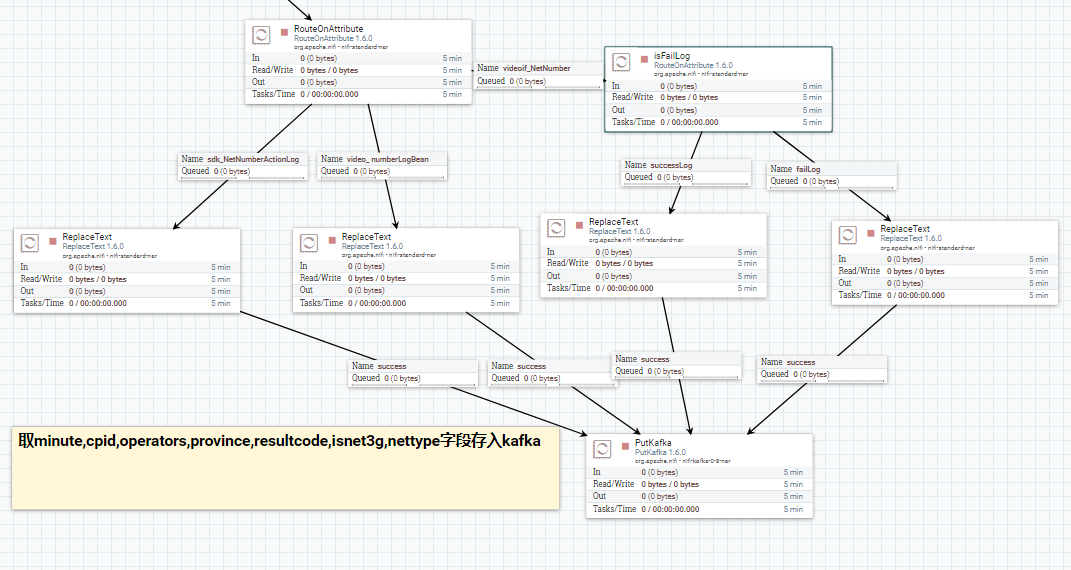
另一份数据(假定历史数据都已经处理完成,现在都是实时的数据)要提取业务需要的字段,导入到kafka的topic 中. 供业务需要的即时统计分析使用.
至此,整个 nifi 的数据处理流程都走完了. 归功了 nifi 的强大 ,数据从起点到终点,虽然处理流程多,但流向非常清晰.用 nifi 拖拽几下,一套特定业务日志的处理系统就完成了. 右键点击 start ,系统就跑起来,你可以在界面看到数据的流动,可以监控,可以暂停,可以调试某段,可以查看中间结果.这些都是可以在界面上完成的. 用很简单的使用方式,去做很复杂的事情,最牛逼的工具莫过于此了.当然, nifi 也有很多高级的用法. 甚至可以 搭一个 nifi 的集群 ,来处理更加海量的数据,这里就不细说了.
当然,nifi中一个很长的数据处理流程是需要花时间观察,调试及验证的.从一个处理器到另一个处理器是否通畅.数据是否阻塞在了流程图中的某一段等问题.需要调试单个处理器的并发量及run schedule等信息.以及处理器之间的缓存队列容量和大小等信息.这些需要耐心的调试,就像一个流动的人群一样,慢慢疏导.
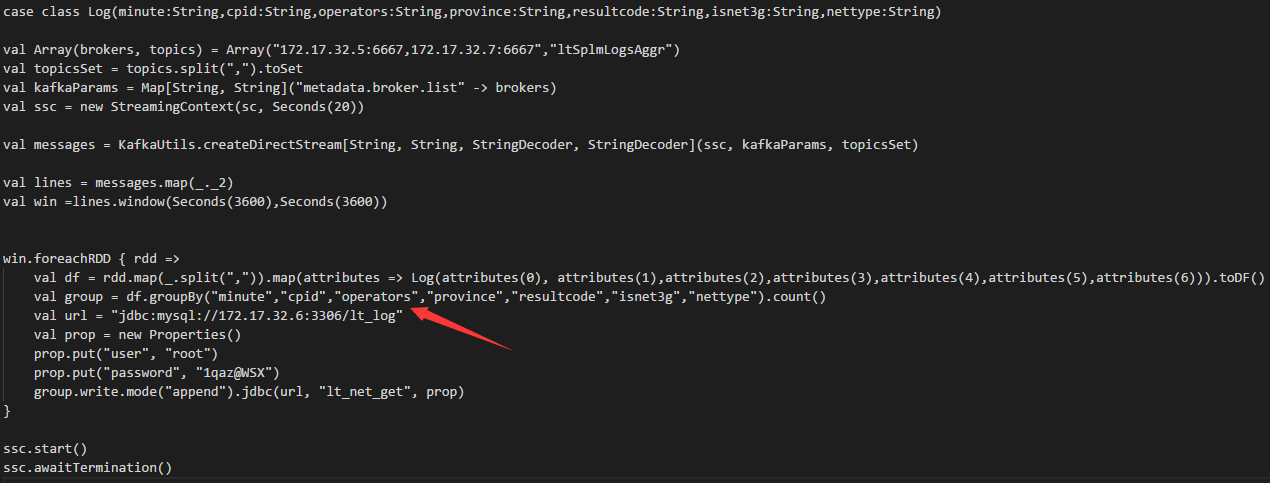
最后,附上实时数据统计的代码,这是这个项目写的唯一代码了,使用的是 spark 技术栈 ,spark streaming 和 spark sql . 关键是这个group by 函数.把聚合后的数据保存mysql 里面,供业务应用查询.这里后来把时间窗口改为了一小时,因为当时聚合后的数据量也还蛮大,2天存了35万条到mysql里面,这样的量放mysql 里面不太合适.
可能一开始的方案就不正确,后来也没继续跟进了.
以上,就是这个项目的一个完整记录,做得有点粗糙,最后也没有继续跟进.很多细节没有考虑到 ,比如由于网络的问题,在整个流程中,是否会有数据的丢失?当由于某种原因导致流程中断,是否会有数据重复.最后的结果,怎样去校验数据的完整性.这些问题理论上是聚焦于各个组件,比如sqoop, kafka ,nifi的机制上的,但实际跑起来之后,会有什么样的问题.当时并没有过细的研究.
所以,如果本文中,有什么不当的,需要补充以及错误的地方,欢迎指正,共同学习,一起进步.欢迎一起探讨关于nifi的使用,最近在码的是一个基于nifi的数据交换平台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号