hadoop----4.hadoopHA高可用搭建
搭建HA高可用
1.HA的文件参数(在master节点上配置文件)
①:配置hadoop-env.sh文件
修改配置:
exportJAVA_HOME=/opt/java
②:配置core-site.xml文件
添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp/</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>3000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
③:配置hdfs-site.xml文件
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/tmp/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/tmp/hdfs/dn</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/tmp/hdfs/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
④:配置mapreduce-site.xml文件
添加:
<configuration>
<!--使用yarn的计算框架--!>
<property>
<name>mapreduce.framework.name </name>
<value>yarn</value>
</property>
</configuration>
⑤:配置yarn-site.xml文件
添加:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
⑥:配置masters和slaves
masters指定两个主机(master*slave1l)namenode信息
vim /opt/hadoop/etc/hadoop/masters
添加:
master
salve1
vim /opt/hadoop/etc/hadoop/slaves
添加:
master
slave1
salve2
⑦:创建hadoop的数据目录
mkdir -p /data/hadoop/tmp/hdfs/jn
mkdir -p /data/hadoop/tmp/hdfs/dn
mkdir -p /data/hadoop/tmp/hdfs/dn
mkdir /data/hadoop/dfs/journal
⑧:修改所属用户权限
sudo chown -R cwl02:cwl02 /opt/hadoop
sudo chown -R cwl02:cwl02 /data/
⑨:将hadoop文件分发至slave1,slave2两个节点
scp -r /opt/hadoop @slave1:/opt/
scp -r /opt/hadoop @slave2:/opt/
10.修改其两个节点的文件的权限
slave1:
sudo chown -R cwl02:cwl02 /opt/
slave2:
sudo chown -R cwl02:cwl02 /opt/
2.启动服务
①:启动zKserver.sh服务(三个节点都运行一次,每次启动优先启动因为此服务连接其他连个节点)
启动服务:
zkServer.sh start



查看状态:
zkServer.sh status



②:启动journalnode
在master上输入:
hadoop-daemons.sh start journalnode

③:格式ZKFC
输入:
hdfs zkfc -formatZK
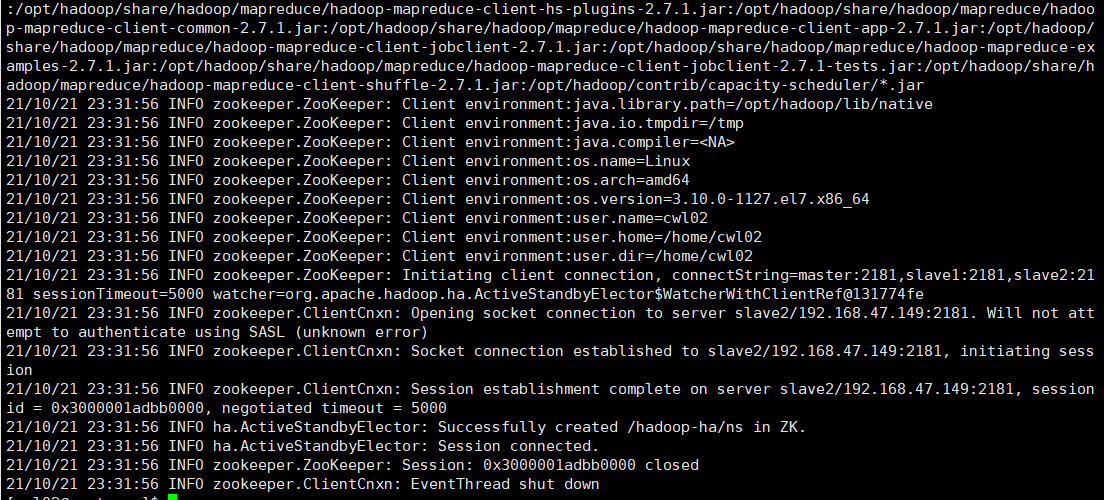
④:在master节点上格式化namenode并启动namenode[active]
输入:
hadoop namenode –format
hadoop-daemon.sh start namenode
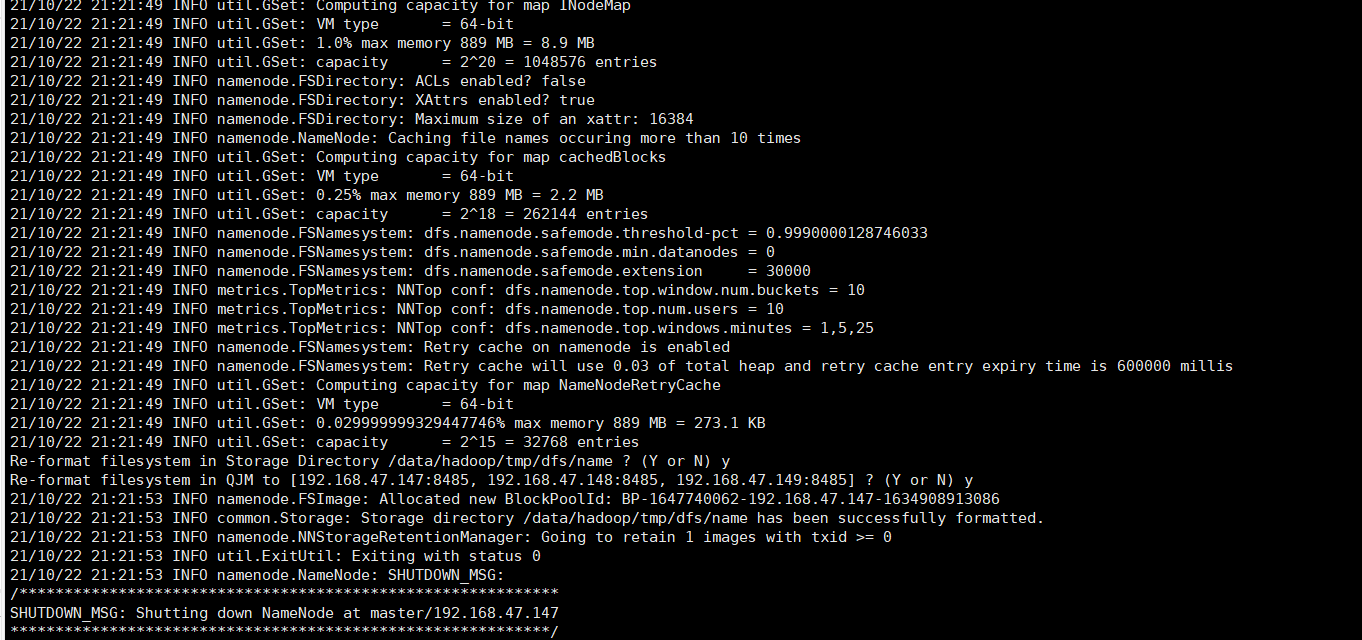
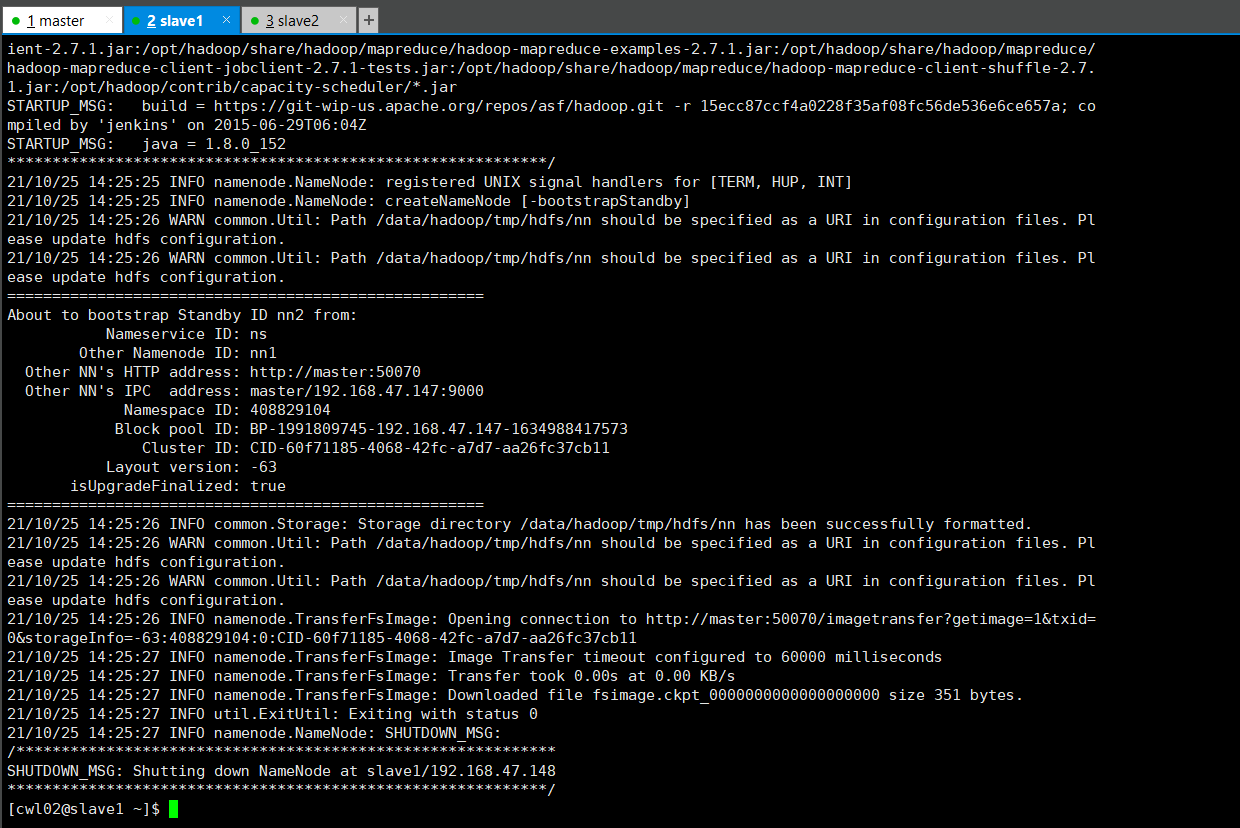
⑤:在slave1节点,同步元数据,并启动namenode[standby]
执行以下命令:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
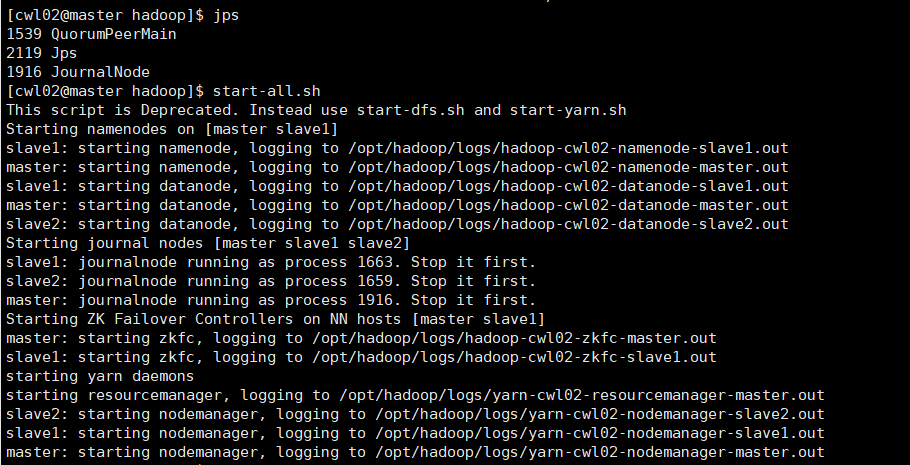
启动其他集群服务
在master上输入:
start-all.sh
⑥:查看服务启动情况和状态
查看namenode状态(本人当前master为active)
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

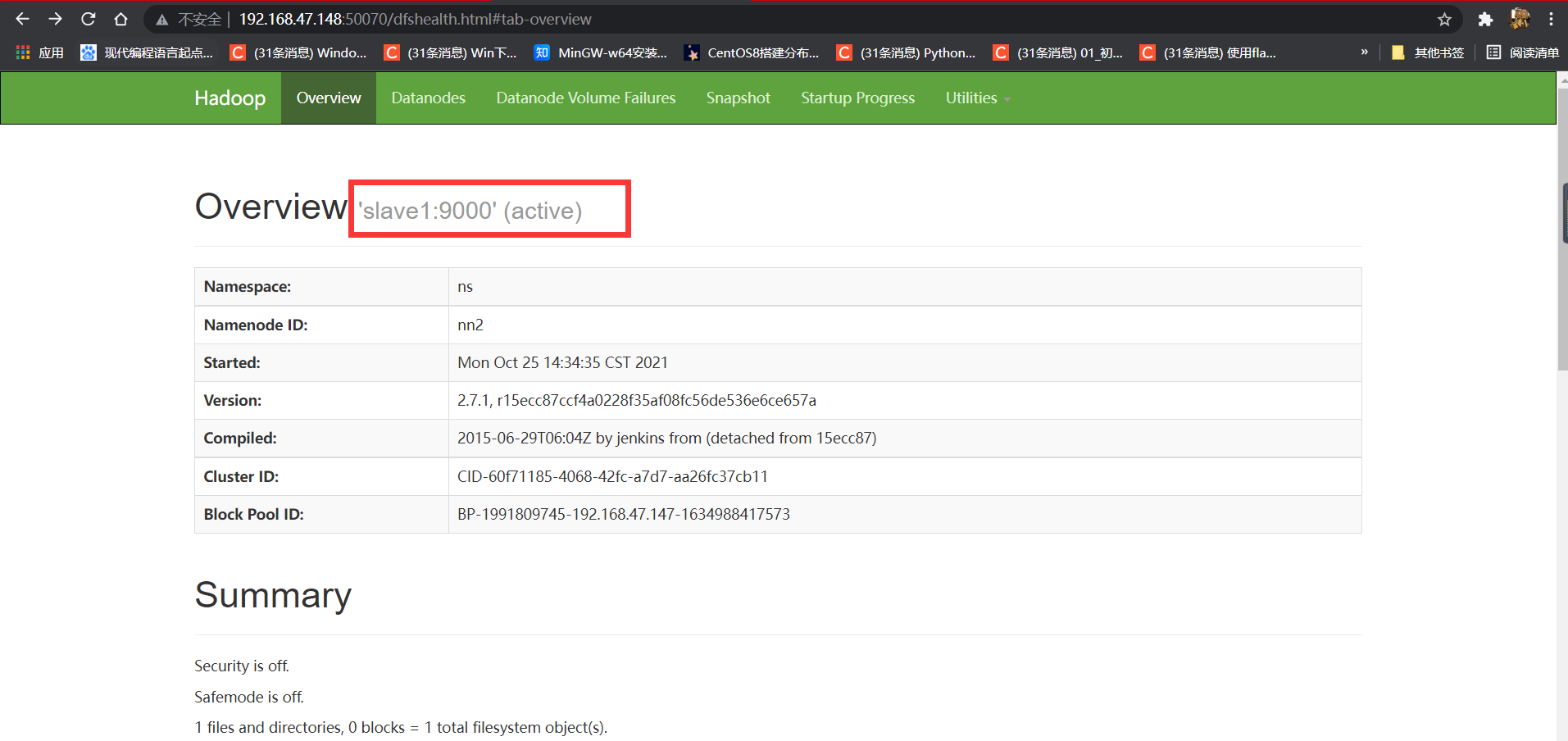
⑦:查看active节点:
打开浏览器输入50070端口查看
输入:
192.168.47.147(此处为自己的ip):50070
查看:
slave1为active
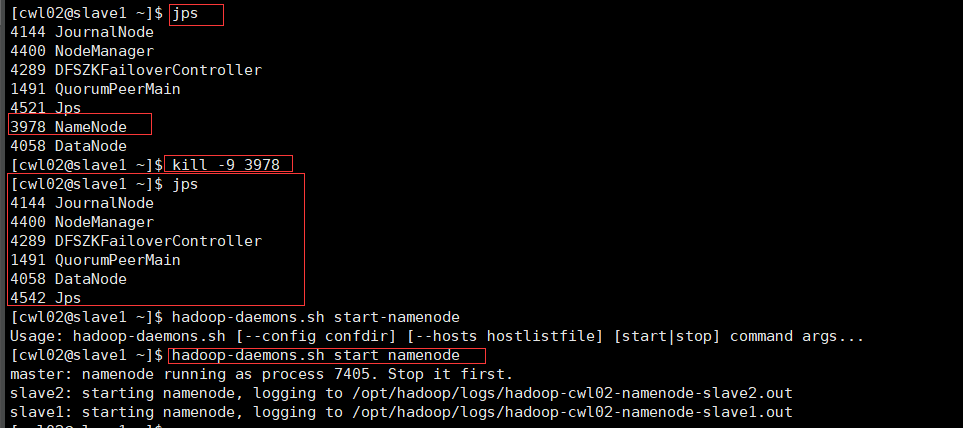
⑧:检查节点
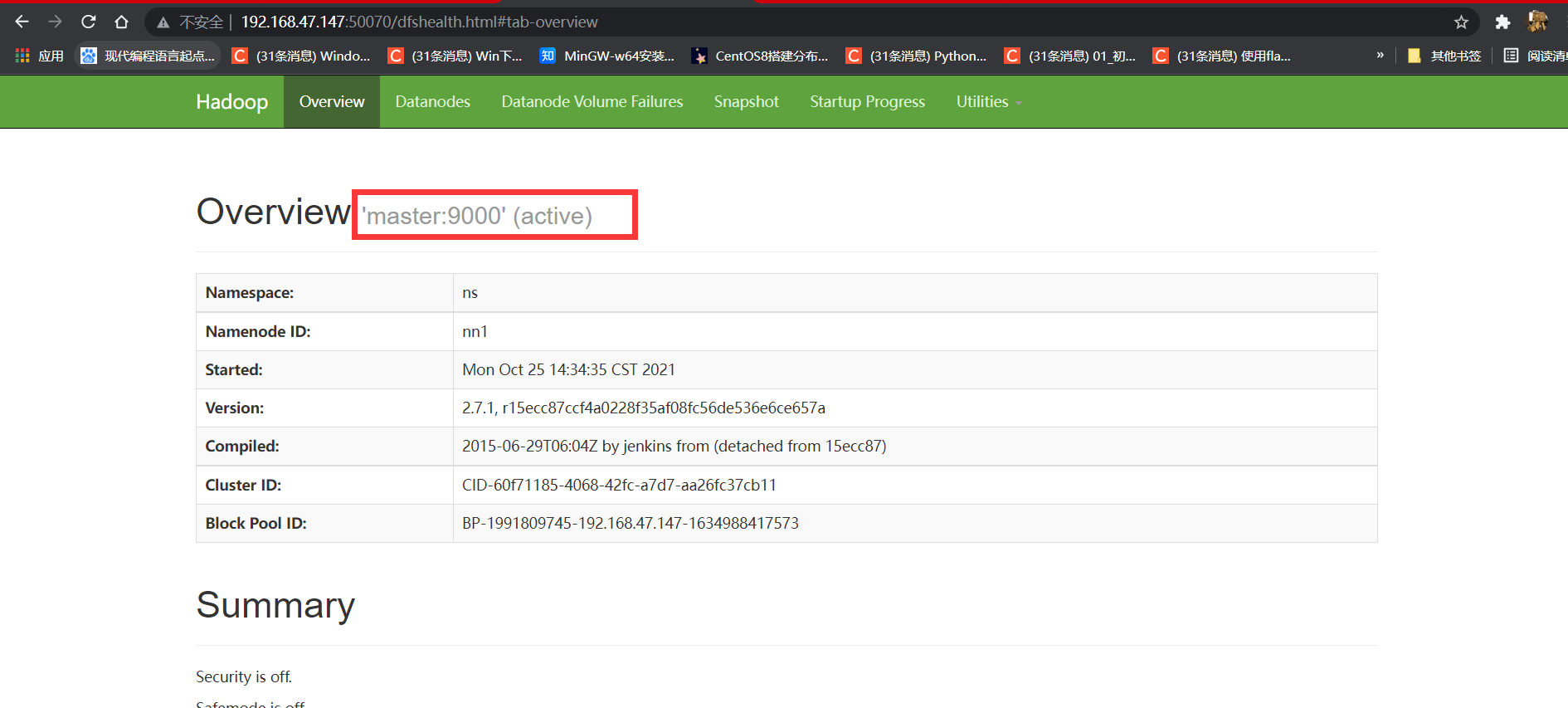
kill掉slave1的namenode,slave1的50070端口就会断开需要重启slave1的namenode(并查看master的50070端口是否为active)
jps查看端口(服务前面的数字就是端口号)
输入:
kill -9 端口号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号