HDFS----配置优化
hdfs的配置优化
1.优化 dfs.replication 文件副本数
①:HDFS 文件副本数设置为 3;修改文件。
进入 /opt/hadoop/etc/hadoop 目录下修改hdfs-site.xml 文件
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
修改 mapreduce-site.xml 文件
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 配置web端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>500000</value>
</property>
②:上传文件,并统计所需要的时间
通过 time 命令量测出来该指令执行时所消耗的时间会因为具体的集群性能不同可能会存在差异,但是在相同的条件基础上得到的数据还是有参考价值的。通过浏览器可以查看到上传之后的文件会有 3 个副本,分别存放在 master、slave1、slave2 上。
查看 master 和 slave1 名称节点的状态,若 master 节点状态为 active,则输入网址master:50070(本次启动网址) 点击 utilities 查看各个文件详情,否则网址为 slave1:50070
输入:hdfs dfs -mkdir /input1 集群上创建目录文件夹
创建文件:touch 文件 ; mkdir 文件夹;写入内容:echo > "内容" ***.txt
输入:time hadoop fs -put 664.txt /input1 上传写好的文件

查看 50070:

③:运行mapreduce官方实例
进入 /opt/hadoop/share/hadoop/mapreduce/ 目录下
输入 hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input1 /output1
运行结束后
查看19888:jobhistory

2.设置 dfs.datanode.data.dir 磁盘
①:设置两个data目录
删除原hdfs上的input1 iiput2 与output1 output2文件
hdfs dfs -rm -r -f /input1 /input2 /output1 /output2
新建input1 和input2
hdfs dfs -mkdir /input1 /input2
修改hdfs-site.xml文件:
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/tmp/hdfs/dn,/home/hadoop/data/dfs/data</value>
</property>
这里设置两个目录,分别为:
hadoop 安装目录下:/usr/local/src/hadoop/tmp/hdfs/dn
home 目录下:/home/hadoop/data/dfs/data
由于 home 目录下不存在上面所示文件夹,因此需要在 home 用户目录下创建文件夹: mkdir -p /home/hadoop/data/dfs/data
②:上传文件查看储存情况
输入:hadoop fs -put /opt/664.txt /input1
重启集群
查看50070:
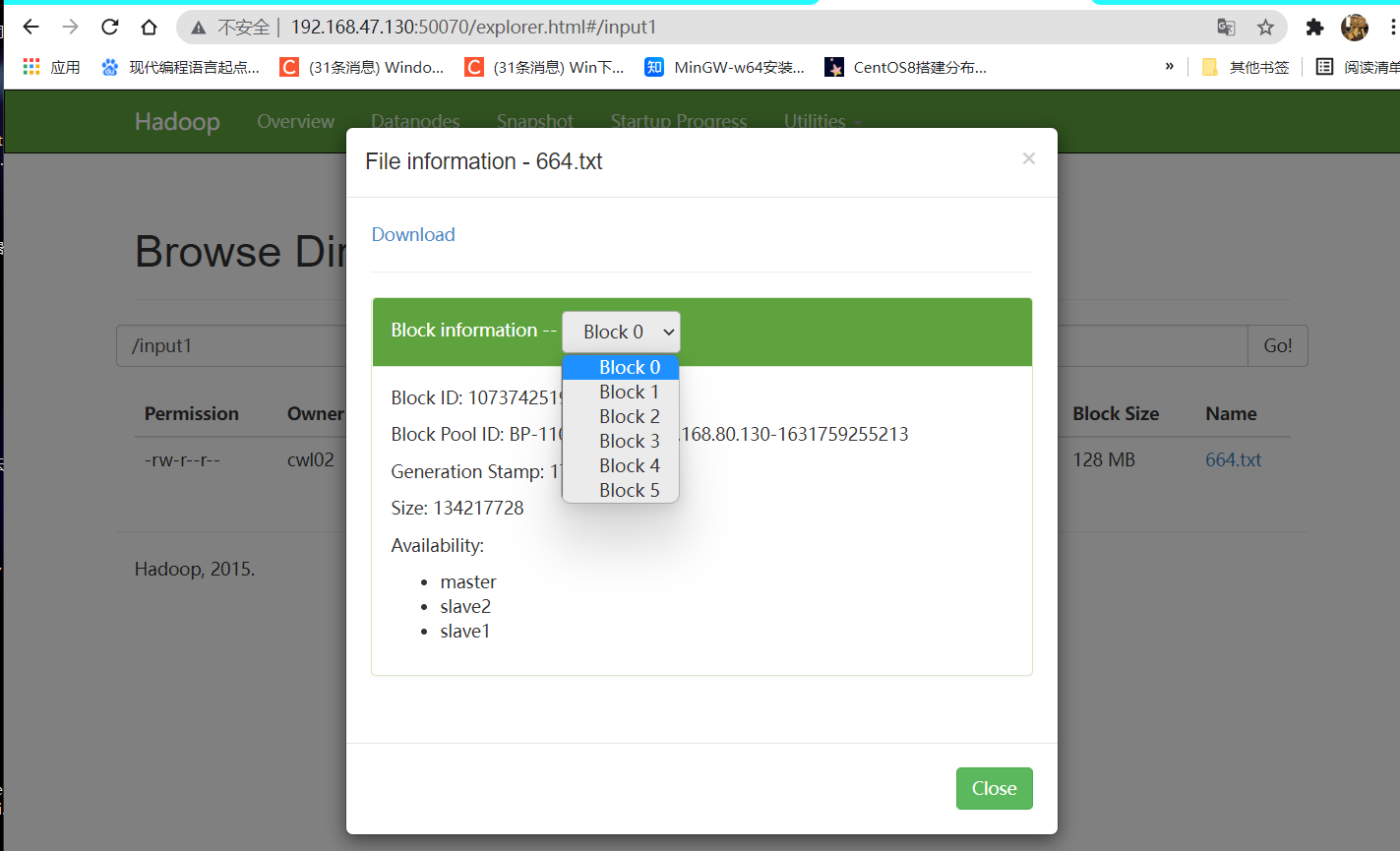
③:查看数据块存储情况
输入:hdfs fsck /input1/664.txt -files -blocks -locations
输出:

The filesystem under path '/input1/664.txt' is HEALTHY
④:查看数据块在两个data目录中的存储情况(存储分布随机)
切换至/opt/hadoop/tmp/hdfs/dn目录下查看

切换至/home/hadoop/data/dfs/data目录下查看

3.设置mapred.local.dir优化IO读写能力
①:设置临时缓存目录
配置:mapred-site.xml文件

②:创建目录
mkdir -p /home/hadoop/data/mapred/local/
启动hadoop(重启hadoop)
删除output1 output2
hdfs dfs -rm -r -f /output1 /output2
③:运行测试的数据
输入:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input1/664.txt /output1
查看(8088):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号