

伙伴系统算法(ZZ)
讲了这么多了,很多人肯定会一头雾水,前边提到的都是些数据结构或者是些概念性的东西,真正对动态页面的管理机制在哪里?换句话说,如何将每个节点,每个区中的页框分配给进程?要理清这个思路,我们首先必须学习一种算法 —— 伙伴系统算法。
内核要分配一组连续的页框,必须建立一种健壮、高效的分配策略。为此,必须解决著名的外部碎片(external fragmentation)问题。频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页框。由此带来的问题是,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就可能无法满足。
Linux 采用伙伴系统(buddy system)算法来解决外碎片问题。把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1, 2, 4, 8, 16, 32, 64, 128, 256,512和1024 个连续的页框。对1024 个页框的最大请求对应着4MB 大小的连续RAM块。每个块的第一个页框的物理地址是该块大小的整数倍。例如,大小为16 个页框的块,其起始地址是16 × 212(212 = 4096,这是一个常规页的大小)的倍数。
我们通过一个简单的例子来说明该算法的工作原理。
假设要请求一个256 个页框的块(即1MB)。算法先在256 个页框的链表中检查是否有一个空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是,在512 个页框的链表中找一个空闲块。如果存在这样的块,内核就把256 的页框分成两等份,一半用作满足请求,另一半插入到256 个页框的链表中。如果在512 个页框的块链表中也没找到空闲块,就继续找更大的块 —— 1024个页框的块。如果这样的块存在,内核把1024个页框块的256 个页框用作请求,然后从剩余的768 个页框中拿512个插入到512个页框的链表中,再把最后的256个插入到256个页框的链表中。如果1024个页框的链表还是空的,算法就放弃并发出错信号。
以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为b的一对空闲伙伴块合并为一个大小为2b的单独块。满足以下条件的两个块称为伙伴:
• 两个块具有相同的大小,记作b。
• 它们的物理地址是连续的。
• 第一块的第一个页框的物理地址是2×b×212的倍数。
该算法是迭代的,如果它成功合并所释放的块,它会试图合并2b 的块,以再次试图形成更大的块。
看晕了吧?如果实在理解不了就自己拿笔画一画,这个算法的原理还是比较简单的,下面我们来看看Linux具体是怎么实现的:
1 数据结构
Linux 2.6 为每个管理区使用不同的伙伴系统。因此,在80x86 结构中,有三种伙伴系统:第一种处理适合ISA DMA 的页框,第二种处理“常规”页框,第三种处理高端内存页框。每个伙伴系统使用的主要数据结构如下:
(1)前面介绍过的mem_map数组。实际上,每个管理区都关系到mem_map元素的子集。子集中的第一个元素和元素的个数分别由管理区描述符的zone_mem_map和size字段指定。
(2)包含有11个元素、元素类型为free_area的一个数组,每个元素对应一种块大小。该数组存放在管理区描述符zone_t的free_area字段中。
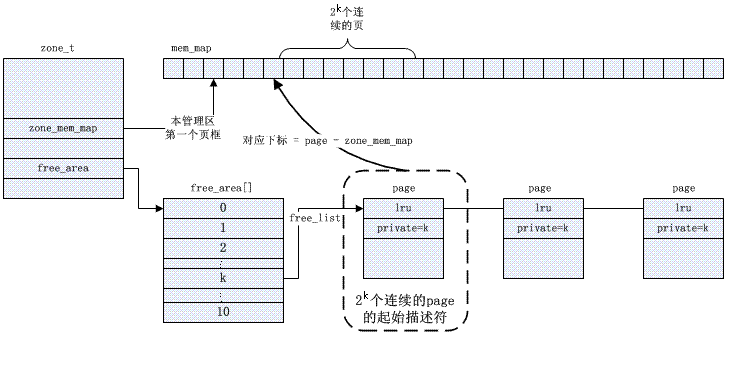 如图,我们考虑管理区描述符中free_area数组的第k个元素,它标识所有大小为2k的空闲块。这个元素的free_list字段是双向循环链表的头,这个双向循环链表集中了大小为2k页的空闲块对应的页描述符。更精确地说,该链表包含每个空闲页框块(大小为2k)的起始页框的页描述符;指向链表中相邻元素的指针存放在页描述符page的lru字段中。
如图,我们考虑管理区描述符中free_area数组的第k个元素,它标识所有大小为2k的空闲块。这个元素的free_list字段是双向循环链表的头,这个双向循环链表集中了大小为2k页的空闲块对应的页描述符。更精确地说,该链表包含每个空闲页框块(大小为2k)的起始页框的页描述符;指向链表中相邻元素的指针存放在页描述符page的lru字段中。
除了链表头外,free_area数组的第k个元素同样包含字段nr_free,它指定了大小为2k页的空闲块的个数。当然,如果没有大小为2k 的空闲页框块,则nr_free等于0且free_list为空(free_list的两个指针next和prev都指向它自己的free_list字段)。
最后,一个2k的空闲页块的第一个页的描述符的private字段存放了块的order,也就是数字k。正是由于这个字段,当页块被释放时,内核可以确定这个块的伙伴是否也空闲。如果是的话,它可以把两个块结合成大小为2k+1页的单一块。
2 块分配
内核使用__rmqueue()函数来在管理区中找到一个空闲块。该函数需要两个参数:管理区描述符的地址zone和order,order表示请求的空闲页块大小的对数值(0 表示一个单页块,1 表示一个两页块,2表示四个页块)。如果页框被成功分配,__rmqueue()函数就返回第一个被分配页框的页描述符。否则,函数返回NULL。
在__rmqueue()函数中,从所请求order的链表开始,它扫描每个可用块链表进行循环搜索,如果需要搜索更大的order,就继续搜索:
struct free_area *area;
unsigned int current_order;
for (current_order=order; current_order<11; ++current_order) {
area = zone->free_area + current_order;
if (!list_empty(&area->free_list))
goto block_found;
}
return NULL;
如果直到循环结束还没有找到合适的空闲块,那么__rmqueue()就返回NULL。否则,找到了一个合适的空闲块,在这种情况下,从链表中删除它的第一个页框描述符,并减少管理区描述符中的free_pages的值:
block_found:
page = list_entry(area->free_list.next, struct page, lru);
list_del(&page->lru);
ClearPagePrivate(page);
page->private = 0;
area->nr_free--;
zone->free_pages -= 1UL << order;
如果从curr_order链表中找到的块大于请求的order,就执行一个while循环。这几行代码蕴含的原理如下:当为了满足2h 个页框的请求而有必要使用2k个页框的块时(h < k),程序就分配前面的2h 个页框,而把后面2k - 2h 个页框循环再分配给free_area链表中下标在h到k之间的元素:
size = 1 << curr_order;
while (curr_order > order) {
area--;
curr_order--;
size >>= 1;
buddy = page + size;
/* insert buddy as first element in the list */
list_add(&buddy->lru, &area->free_list);
area->nr_free++;
buddy->private = curr_order;
SetPagePrivate(buddy);
}
return page;
因为__rmqueue()函数已经找到了合适的空闲块,所以它返回所分配的第一个页框对应的页描述符的地址page。
3 块释放
__free_pages_bulk()函数按照伙伴系统的策略释放页框。它使用3个基本输入参数:
page:被释放块中所包含的第一个页框描述符的地址。
zone:管理区描述符的地址。
order:块大小的对数。
__free_pages_bulk()首先声明和初始化一些局部变量:
struct page * base = zone->zone_mem_map;
unsigned long buddy_idx, page_idx = page - base;
struct page * buddy, * coalesced;
int order_size = 1 << order;
page_idx局部变量包含块中第一个页框的下标,这是相对于管理区中的第一个页框而言的。order_size 局部变量用于增加管理区中空闲页框的计数器:
zone->free_pages += order_size;
现在函数开始执行循环,最多循环 (10-order) 次,每次都尽量把一个块和它的伙伴进行合并。函数以最小的块开始,然后向上移动到顶部:
while (order < 10) {
buddy_idx = page_idx ^ (1 << order);
buddy = base + buddy_idx;
if (!page_is_buddy(buddy, order))
break;
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
ClearPagePrivate(buddy);
buddy->private = 0;
page_idx &= buddy_idx; /* 合并 */
order++;
}
这个循环我看了半天没有看懂,后来举个例子,再画个图才渐渐明白。比如,我们这里order是4,那么order_size的值为24,也就是16,表明要释放16个连续的page。page_idx为这个连续16个page的老大的mem_map数组的下标。进入循环后,函数首先寻找该块的伙伴,即mem_map数组中page_idx-16或page_idx+16的下标buddy_idx,进一步说明一下,就是为了在下标为16的free_area中找到一个空闲的块,并且这个块与page所带的那个拥有16个page的块相邻。
尤其要注意:buddy_idx = page_idx ^ (1 << order)这行代码。这行代码很巧妙,短小精干。因为order一来就等于4,所以循环从4开始的,即第一个循环为buddy_idx = page_idx ^ (1<<4),即buddy_idx = page_idx ^ 10000。如果page_idx第5位为1,比如是20号页框(10100),那么在异或以后,buddy_idx为4号页框(00100)。如果page_idx第5位为0,比如是第40号页框(101000),那么在异或以后,buddy_idx为56号页框(111000)。
为什么要做这么一个运算呢?想想我们的目的是什么。__free_pages_bulk是将以其参数page为首的2^order个页面找到一个伙伴,并与其合并。在mem_map数组中,这个伙伴的老大要么是在这个page的前2^order,要么就是后2^order。如果单单是加或者减,那么就会忽略前面的或者后面的伙伴。大家不妨对照上图好好的琢磨一下。至于为啥不既加又减呢,我估计Linux的开发者们没这么做是因为性能的问题吧,各个资料上也说了这里主要是尽量合并而已,我们就不去管他了。
找到伙伴以后,把该伙伴的老大page的地址赋给buddy:
buddy = base + buddy_idx;
现在函数调用page_is_buddy()来检查buddy是否是真正的值得信赖的伙伴,也就是大小为order_size的空闲页框块的第一个页。
int page_is_buddy(struct page *page, int order)
{
if (PagePrivate(buddy) && page->private == order &&
!PageReserved(buddy) && page_count(page) ==0)
return 1;
return 0;
}
正如所见,要想成为伙伴,必须满足以下四个条件:
(1)buddy的第一个页必须为空闲(_count字段等于-1);
(2)它必须属于动态内存(PG_reserved 位清零);
(3)它的private 字段必须有意义(PG_private 位置位);
(4)它的private字段必须存放将要被释放的块的order。
如果所有这些条件都符合,就说明有新的伙伴存在啦,那么伙伴块就要跟我page结合,先必须得脱离原来的free_list,执行page_idx &= buddy_idx合并(注意,这行代码与前边的buddy_idx = page_idx ^ (1 << order)是紧密结合的),并再执行一次循环以寻找两倍大小的伙伴块。
如果page_is_buddy()中至少有一个条件没有被满足,则该函数跳出循环,因为获得的空闲块不能再和其他空闲块合并。函数将它插入适当的链表并以块大小的order 更新第一个页框的private 字段。
coalesced = base + page_idx;
coalesced->private = order;
SetPagePrivate(coalesced);
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/yunsongice/archive/2010/01/22/5225155.aspx


