数据的列式与行式存储以及大数据的存储格式
一、数据的列式与行式存储
1、列式存储是相对于传统关系型数据库的行式存储来说的。两者的区别就是如何组织表;从下图可知,行式存储是将数据的一条记录(多列组成)存储起来的,但是列式存储是将数据的一条记录的各列分开进行存储。
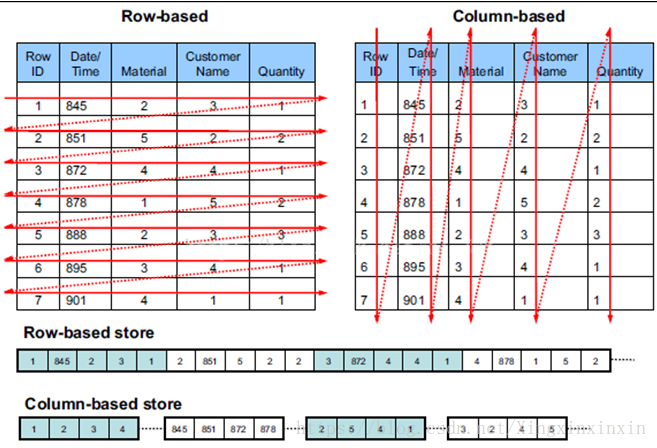
2、区别
(1)数据写入区别
1)行存储的写入是一次完成。可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在磁盘片上移动和定位花费的时间,故行存储在写入上占有很大的优势。
3)对于数据修改,其实也是数据写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
(2)数据读取的区别
1)数据读取时,行存储是将一行数据完全读出,若只需其中几列数据的话,就会存在冗余列,出于缩短处理时间的考虑,消除冗余列的过程是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3)两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
4)列式存储数据类型一致,数据特征相似,可以高效压缩。行式存储压缩效果比较差。
行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,犹为重要。
二、OLTP 与OLTP
1、OLTP和OLAP的区别
(1)OLAP主要涉及到HIVE,HBASE,OLTP主要涉及到Mysql,Oracle
(2)基本含义不同
a、OLTP是传统关系型数据库的应用,涉及到基本的事务处理和记录的增、删、改、查,比如在银行存取一笔款,就是一个事务交易。
b、OLAP是联机分析处理,是数据仓库的核心部心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统。
(3)实时性要求不同
a、OLTP实时性要求高,OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
b、OLAP的实时性要求不是很高,很多应用顶多是每天更新一下数据。
(4)数据量不同
a、OLTP数据量不是很大,一般只读/写数十条记录,处理简单的事务。
b、OLAP数据量大,因为OLAP支持的是动态查询
(5)用户和系统的面向性不同:OLTP是面向顾客的,用于事务和查询处理。OLAP是面向市场的,用于数据分析。
三、大数据框架的存储格式
1、Hadoop的存储格式
面向行:同一行的数据存储在一起,即连续存储。SequenceFile,MapFile,Avro Datafile。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。
面向列:整个文件被切割为若干列数据,每一列数据一起存储。Parquet , RCFile,ORCFile。面向列的格式使得读取数据时,可以跳过不需要的列,适用于处理一行中部分列数据。但是这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。同时不适合流式写入,因为一旦写入失败,当前文件无法恢复,而面向行的数据在写入失败时可以重新同步到最后一个同步点。
(1)面向行的存储格式
1)SequenceFile按照是否压缩可以分为以下部分
a、不压缩:按照记录长度、Key长度、Value程度、Key值、Value值依次存储。长度是指字节数。采用指定的Serialization进行序列化。
b、Record压缩:只有value被压缩,压缩的codec保存在Header中。
c、Block压缩:多条记录被压缩在一起,可以利用记录之间的相似性,更节省空间。Block前后都加入了同步标识。
2)MapFile是SequenceFile的变种,在SequenceFile中加入索引并排序后就是MapFile。索引作为一个单独的文件存储,一般每个128个记录存储一个索引。索引可以被载入内存,用于快速查找。存放数据的文件根据Key定义的顺序排列。 MapFile的记录必须按照顺序写入,否则抛出IOException。MapFile变种SetFile,ArrayFile.
(2)面向列的存储格式
1)RCFile:是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能,但是不支持模式演进。 RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
2)ORCFile:提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。数据按行分块 每块按照列存储 ,压缩快,查询快.
3)Parquet:能够很好的压缩,有很好的查询性能,支持有限的模式演进。但是写速度通常比较慢。这中文件格式主要是用在Cloudera Impala上面的。
注意:hive主要涉及到TextFile,RCFile,ORCFile,Parquet这四种格式.
四、大数据的压缩格式
1、压缩的优缺点
(1)优点:减少磁盘存储空间,降低IO(其中包括网络IO和磁盘IO),加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
(2)缺点:由于使用数据时需要先解压,就会加重CPU的负荷
2、压缩格式:gzip,lzo,snappy,bzip2,压缩比即压缩率,是文件压缩后的大小与压缩前的大小之比
(1)Gzip压缩格式
1)优点:压缩比在四种压缩方式中较高,hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样,大部分linux系统自带gzip命令,使用方便。
2)缺点:不支持split
(2)lzo压缩格式
1)优点:压缩速率仅次于gzip,解压速率是最快的;支持split,是hadoop中最流行的压缩格式;需要在linux系统下自行安装lzop命令,使用方便。
2)缺点:压缩比要比gzip低;hadoop本身比支持,需要安装;lzo虽然支持split,但是需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要制定inputformat为lzo格式)
(3)snappy
1)优点:压缩速度最快,在应用中处理snappy格式的文件就和直接处理文本一样
2)缺点:不支持split,hadoop本身不支持,需要安装,linux系统下没有对应的命令
(4)bzip2
1)优点:支持split;压缩比最高比gzip都高;hadoop本身支持;在应用中处理snappy格式的文件就和直接处理文本一样;在linux系统下自带bzip2命令,使用方便
2)缺点:压缩解压速率慢,不支持native
每一种压缩方式都有他的优缺点,讲求压缩效率,压缩比就会低,占用的网络io和磁盘io就多,讲求压缩比,对cpu的损耗就比较大,同时压缩和解压的耗时就比较多,对于支持split的(lzo和bzip)可以实现并行处理。
3、实例:为什么map端用snappy压缩格式;而reduce用gzip或者bzip2的压缩格式呢?为什么每个reduce端压缩后的数据不要超过一个block的大小呢?
考虑MR每次都要落地到磁盘,Map压缩主要是增加mr运行的效率,我们就需要找压缩效率最高的压缩格式,snappy的压缩时间最快;Reduce压缩就是输出文件压缩 ,故考虑占用磁盘空间的大小;选择高压缩比gzip或者bzip2;而考虑到会用reduce结果做二次运算;
4、压缩与解压的时机
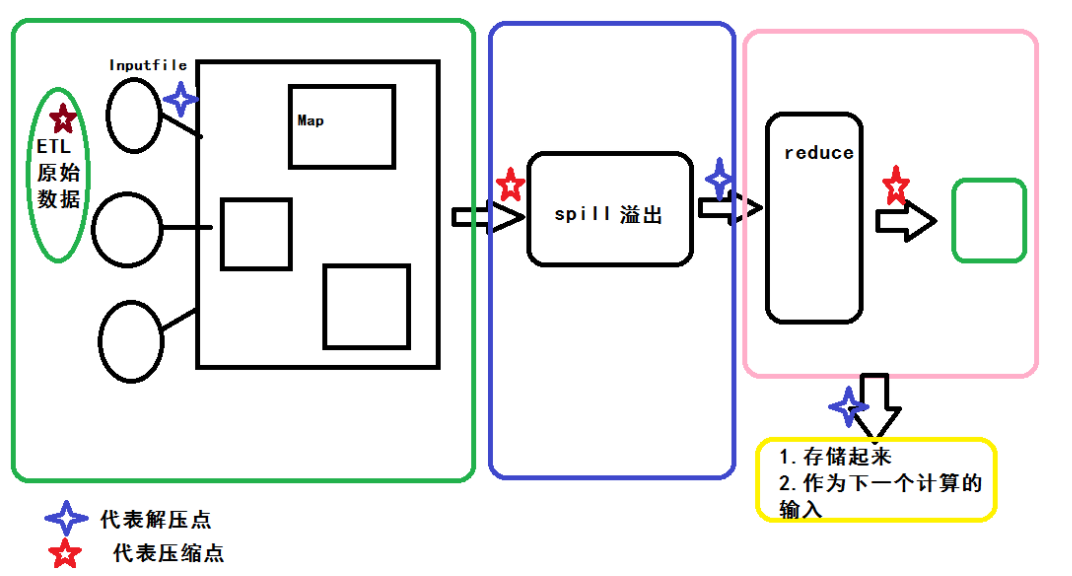
5、如何使用压缩
(1)hive使用压缩
1)set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec //设置压缩格式
2)set hive.exec.compress.intermediate=ture //开启中间压缩
3)set mapred.output.compression.type=BLOCK //块压缩
4)set hive.exec.compress.output=true;
(2)spark使用压缩
配置executor端的压缩
1)配置Spark读写压缩格式相关的类库和jar,具体配置如下:
spark.executor.extraLibraryPath=/usr/lib/native/
spark.executor.extraClassPath=/usr/lib/hadoop/lib/hadoop-lzo.jar
2)代码中配置:
val textFile = sc.textFile(args(0), 1)
textFile.saveAsTextFile(args(1), classOf[LzopCodec])
配置Driver端的压缩
--driver-class-path /usr/lib/hadoop/lib/hadoop-lzo.jar
--driver-library-path /usr/lib/native
在使用Spark SQL的时候,配置Executor和Driver与压缩相关的属性就可以正常读取Hive目录下的压缩文件。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号