
jmeter+influxdb+grafana 进行压测
一、准备工作
- 安装jdk8,配置java环境变量
- 下载解压Jmeter,Apache官网最新版本为5.4.1。这里给大家提供一个我们目前在用的Jmeter5.1.1的包,直接下载解压即可📎apache-jmeter-5.1.1.zip,Jmeter本身由纯JAVA语言编写,支持跨平台使用,windows/Mac均可使用(Jmeter历史版本下载链接:http://archive.apache.org/dist/jmeter/binaries/)
- 待压测接口URL、请求方式、请求头、请求参数、是否需要参数化
二、在Jmeter图形化界面创建脚本
1、打开Jmeter图形化界面
下载好压缩包后,将压缩包解压,打开解压后的文件夹,在bin目录下双击jmeter.bat(windows)/jmeter(mac)即可打开Jmeter图形化界面,如下图:
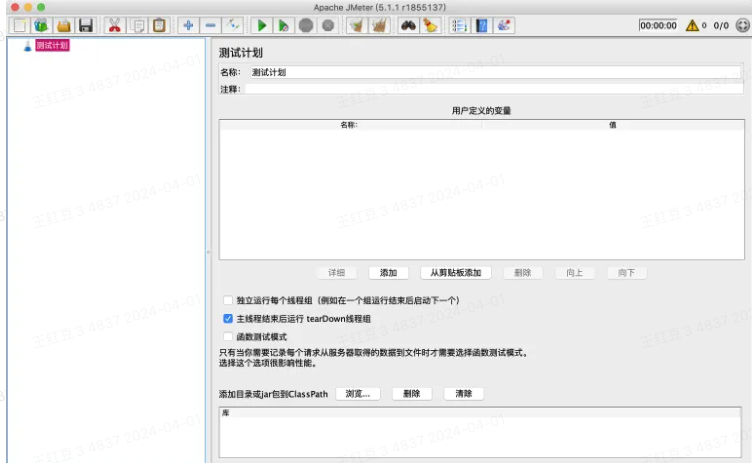
Jmerter本身即支持中文语言界面,切换语言配置见下图操作路径
2、添加线程组
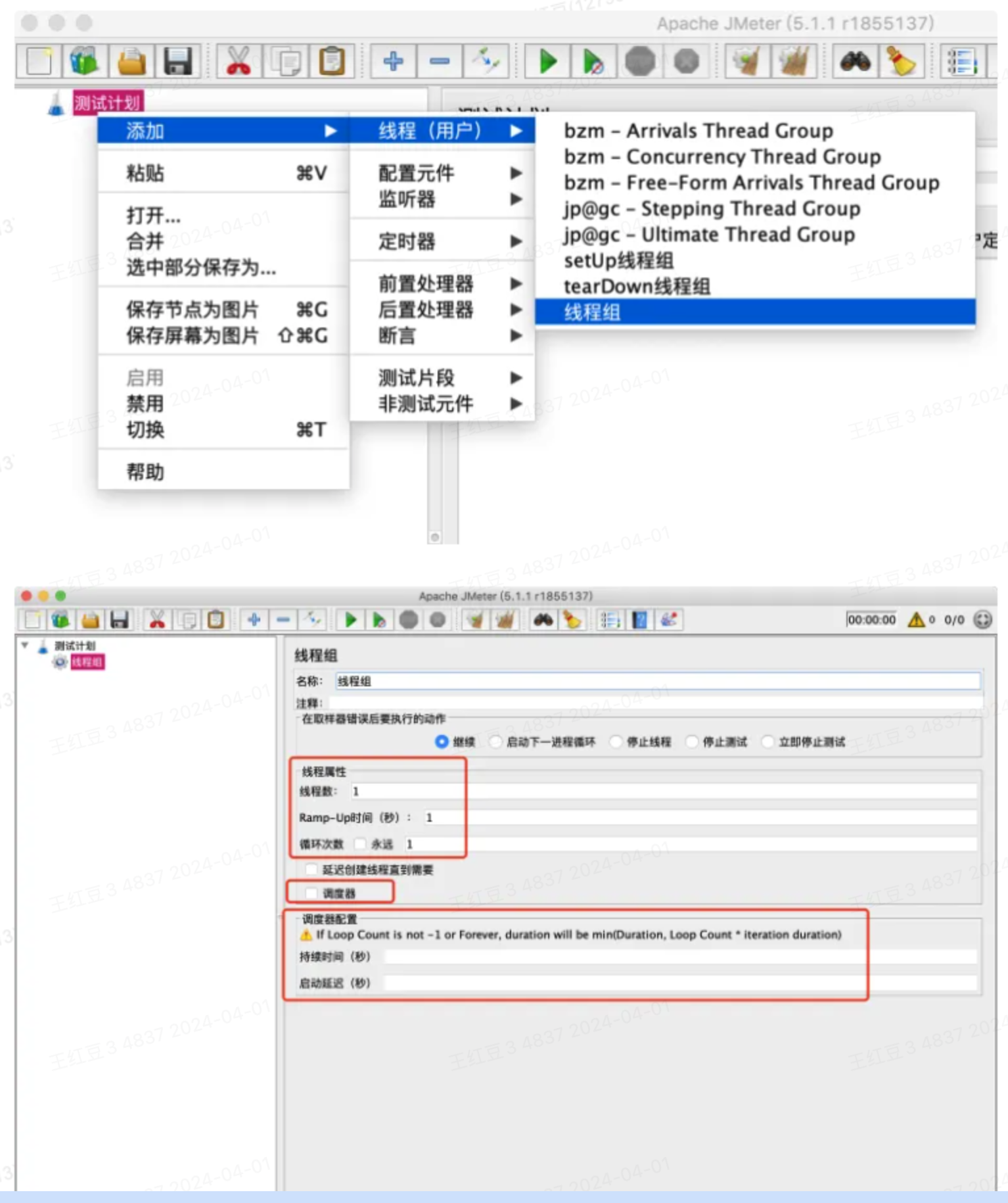
线程数:虚拟用户数,一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。Ramp-Up Period(秒):设置的虚拟用户数需要多长时间全部启动。如果线程数为10 ,Ramp-Up Period为100,那么就是100秒钟内启动10个线程。每一个线程都会在上一个线程启动10秒钟后才开始运行;设置为0则表示同时启动。
循环次数:每个线程发送请求的次数,如果线程数为20 ,循环次数为100 ,那么每个线程发送100次请求。总请求数为20*100=2000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
调度器:勾选后启用调度器,持续时间(秒)和启动延迟(秒)才生效;不勾选则不生效。
持续时间(秒):脚本运行的总时长。
启动延迟(秒):延迟多长时间开始执行脚本。
⚠️ 合理使用调度器配置和线程属性配置,Jmeter会在达到任一条件后停止运行脚本。如:线程数1、循环次数10、持续时间10s,在此条件下运行脚本时,若在10s内Jmeter调用10次请求完成,那么Jmeter将停止继续运行脚本;同样的,如果在调用完10次请求之前,时间已经达到10s,那么Jmeter也会停止运行脚本,结束测试。
3、添加HTTP请求取样器
⚠️ 取样器必须添加在线程组下,因此要右键线程组来添加HTTP请求取样器
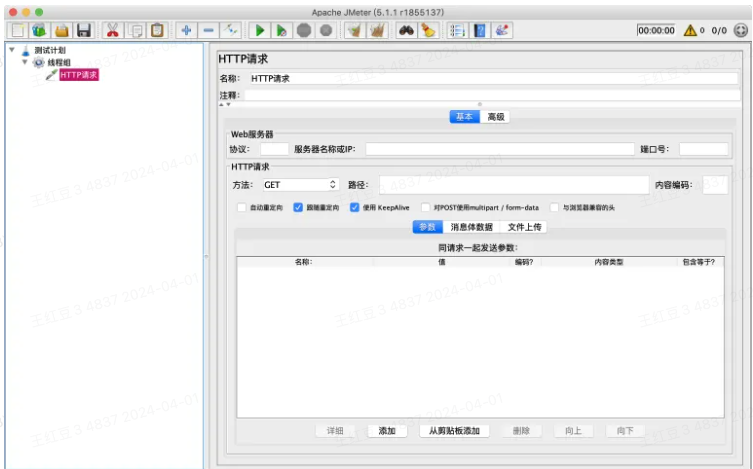
HTTP请求取样器中,对应填入接口的请求协议、域名/IP+端口号、请求方法、请求路径、参数即可。
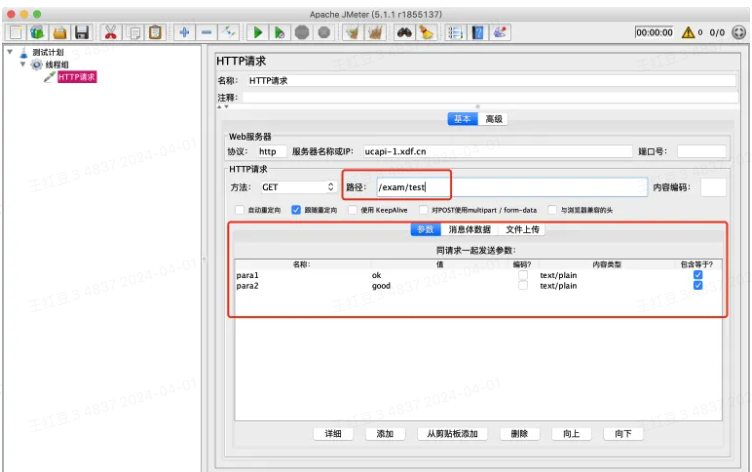
⚠️ GET请求可直接讲参数拼在路径中,如:/exam/test?para1=ok¶2=good;也可将接口URL填在路径中,参数放在下方参数栏中,如下图:
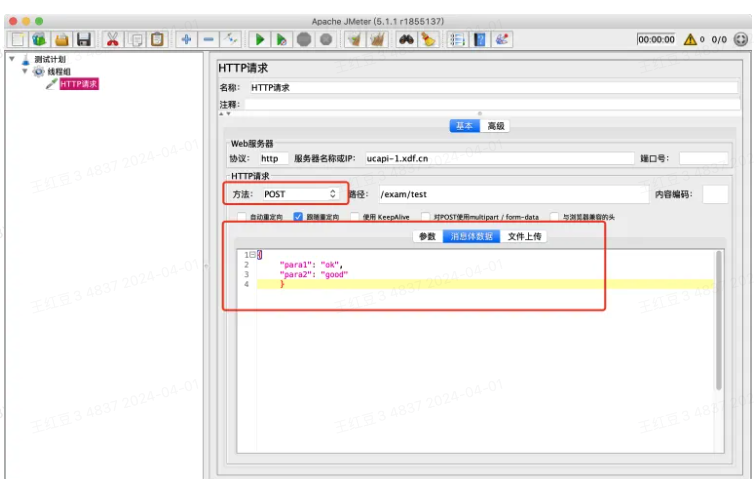
⚠️ POST请求通常情况都放在消息体中传递,将入参写入“消息体数据”即可,如下图:
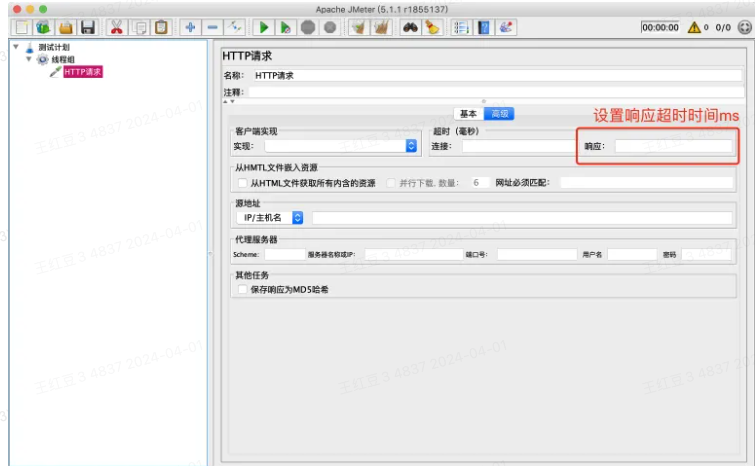
⚠️ 设置请求响应超时时间(常用):在HTTP请求取样器界面,切换至“高级”,即可配置响应超时时间,如下图
4、添加HTTP信息头管理器
HTTP信息头管理器:配置HTTP请求的请求头信息,可在所有组件下添加,对应的作用域也有所不同。
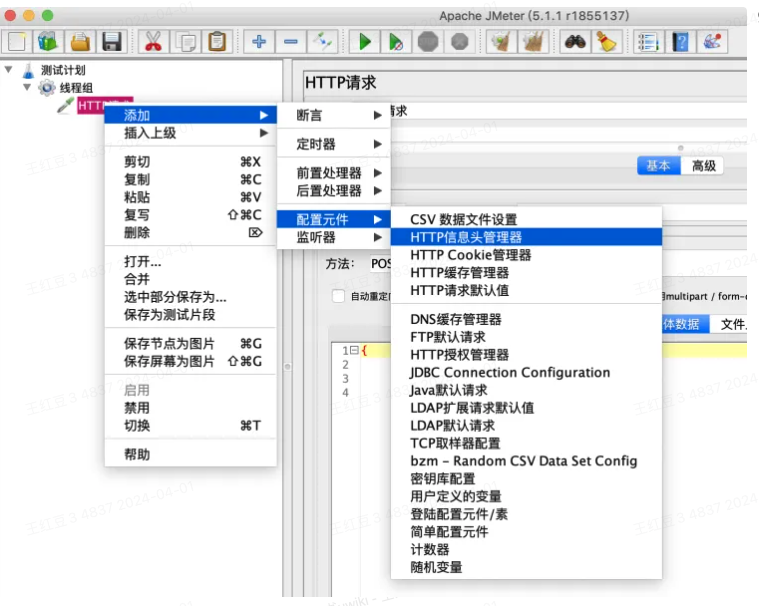
通常情况下,必须配置的请求头信息为 Content-Type: application/json (根据实际请求的请求头填写值)
常见请求头配置项:roleType,accessToken,email等,视具体接口请求头配置项确定
5、添加HTTP Cookie管理器
HTTP Cookie管理器:配置HTTP请求的cookie信息,常见如token
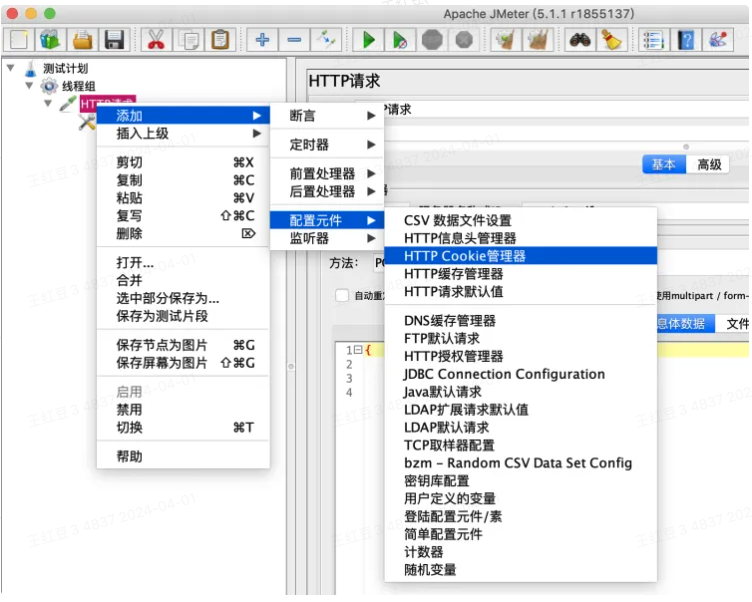
⚠️ 配置token时,注意“域”的值与HTTP请求域名一致
6、添加监听器:察看结果树、聚合报告

察看结果树和聚合报告监听器,主要用来在Jmeter图形界面调试脚本使用。
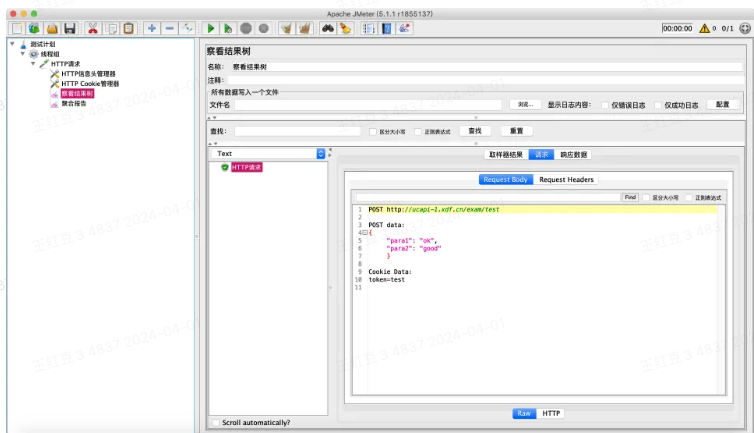
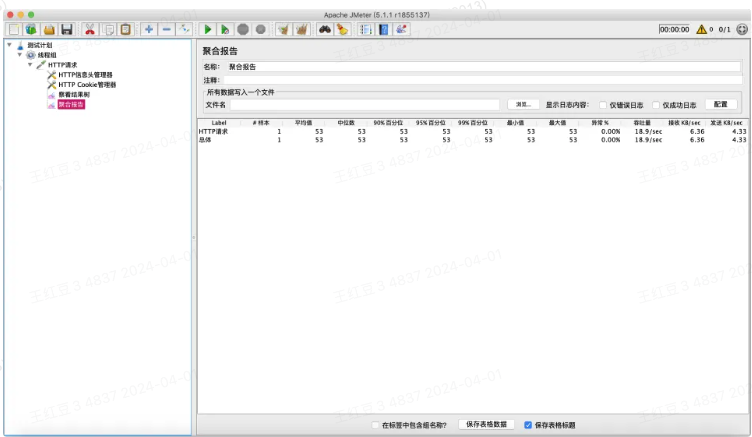
接下来只需要调整好请求的各项参数,在察看结果树中确定请求正常,则一个单接口的压测脚本已基本完成。
三、进阶用法
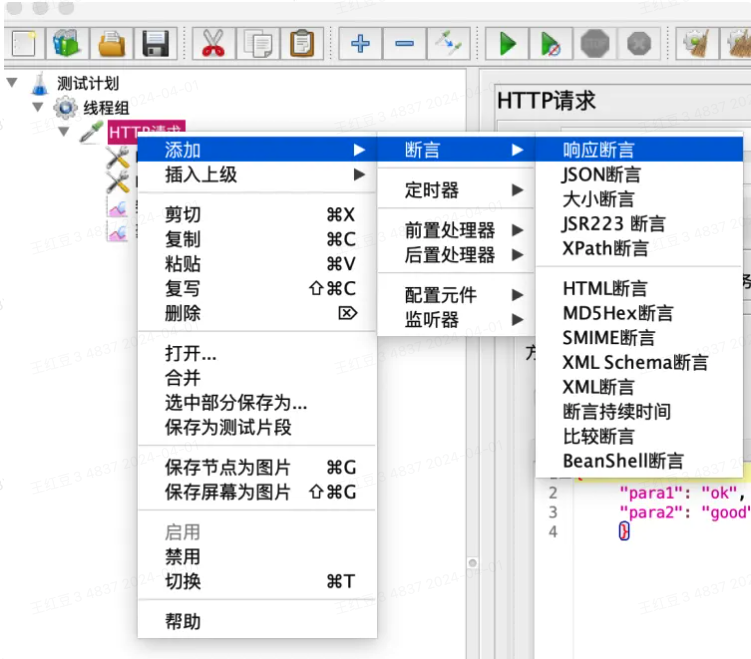
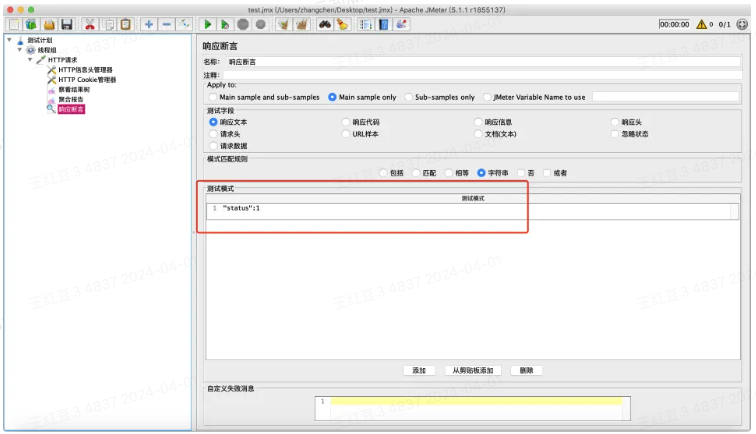
1、添加断言
2、参数化
添加CSV数据文件设置配置元件
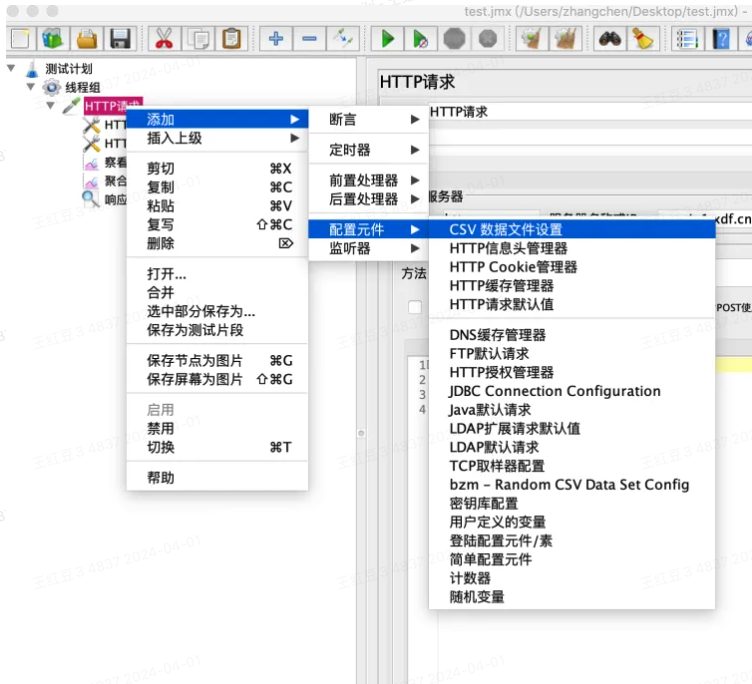

其中重点关注以上几项:
文件名:要读取的参数化文件,如果该参数化文件和脚本文件保存在同一个目录下,此处可直接填写参数化文件名称
变量名称:为从参数化文件中读取出来的数据命名,如有多个参数化字段,变量名用英文逗号隔开,如:email,subject,edu
忽略首行:Fasle不忽略首行,即从参数化文件中的第一行开始取值;True忽略首行,即从参数化文件中的第二行开始取值。这个是因为如果参数化文件中参数过多,为了区别字段,参数化文件中第一行会保留字段名。
分隔符:用来分隔参数的符号,如果使用csv文件,通常都是用英文逗号","来分隔,需要根据不同参数化文件来修改分隔符,支持转译符号,如\t为制表符,\n为换行符。
线程共享模式:当前配置元件的作用域,一般情况下不用修改。
参数化文件的数据读取形式:每次请求按行读取数据,即一次请求取一行参数化文件中的参数,根据设置的分隔符来区分不同参数化字段。
参数化变量引用:如上图中,仅参数化了一个字段,且变量名称为email,那么可以用${email}的方式来引用该变量,如下图,且该变量也可在请求头、cookie、请求域名、请求路径等多个地方引用
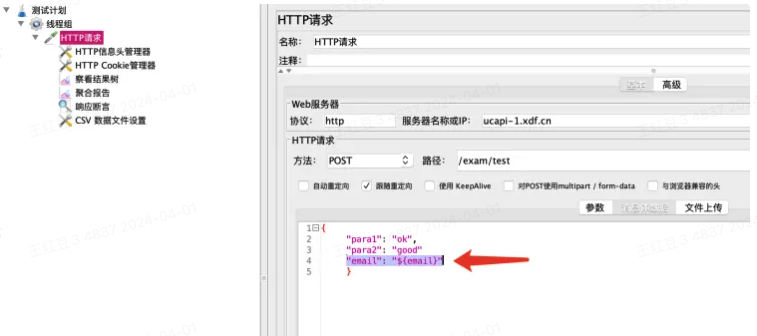
参数化文件格式:常用的为.csv和.txt类型文件。通常情况下,多个字段需要参数化,我们要求一个字段给一列,且用英文逗号分隔开,注意如果字段间有对应关系的话,每一行的字段值需对应正确。
3、接口关联
常用于场景压测,下游接口依赖上游接口的返回值做入参的情况。
常用组件:后置处理器-JSON提取器,后置处理器-正则表达式提取器
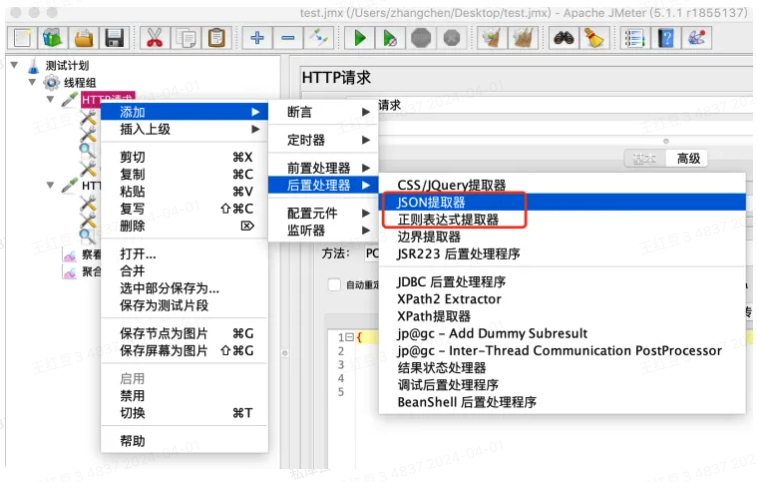
以JSON提取器举例:
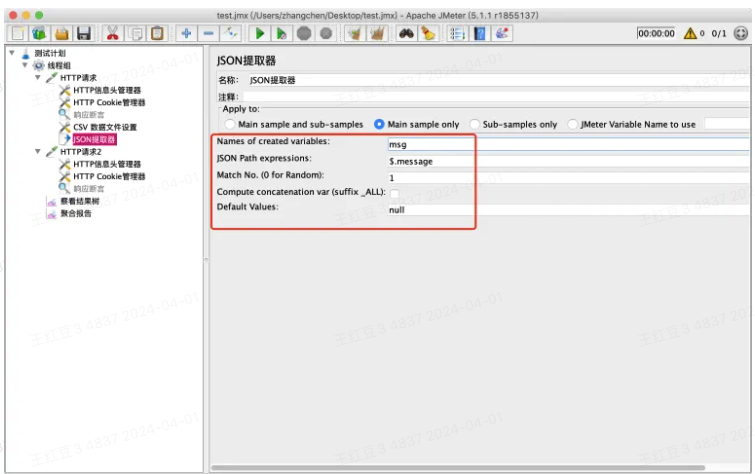
Names of created variables:保存的变量名,后面使用${}引用,可以提取多个变量,变量名中间用英文分号分隔,最后一个变量后面不需要符号
JSONPath expressions:json path表达式,若提取的是多个变量,则需要多个json表达式,json表达式中间用英文分号分隔,最后一个表达式后面不需要符号,json表达式中可能涉及到索引,索引从0开始取值,*表示通配
eg:$.result.data.tasks[*].woCode;$.result.data.tasks[*].boxQty;$.result.data.tasks[0].taskId
Match No.(0 for Random):匹配第几个,0表示随机;n取第几个匹配值;-1匹配所有。若只要获取到匹配的第一个值,则填写1
Compute concatenation var(suffix_ALL):如果匹配到多个结果,将使用’ , '分隔符将它们连接起来,命名为“变量名_ALL”
taskId_ALL=396671,396651,396681,396661,396611,396641,396621,396601,396631
Default Values:找不到时给变量一个默认值
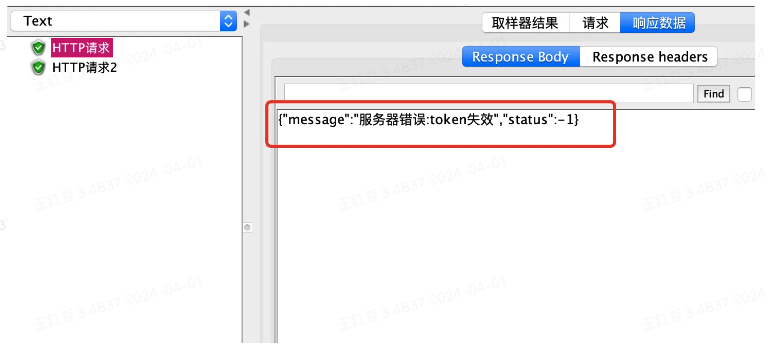
如上图所示,我将从第一个接口的返回值中提取message字段,给第二个接口做入参使用,首先看下第一个接口的返回值如下图,故json path表达式为:$.message,变量名msg,取第1个值,默认值为null
所以在第二个接口中,入参引用如下图:
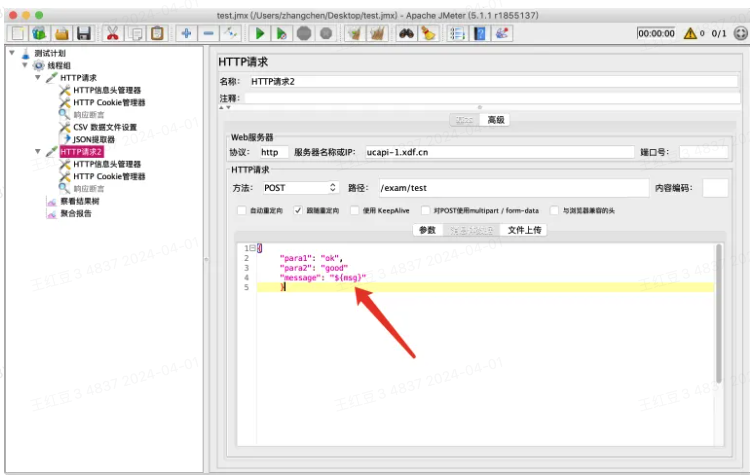
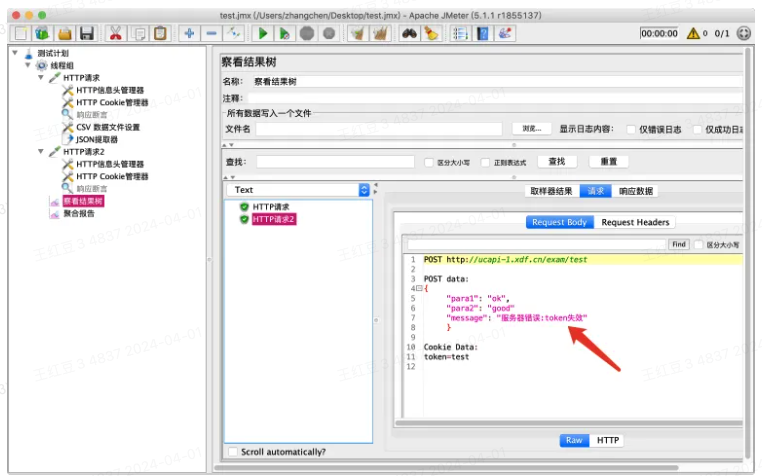
运行后在察看结果树中查看请求参数,引用成功。
4、后端监听器(暂停使用,待重新搭建监控)
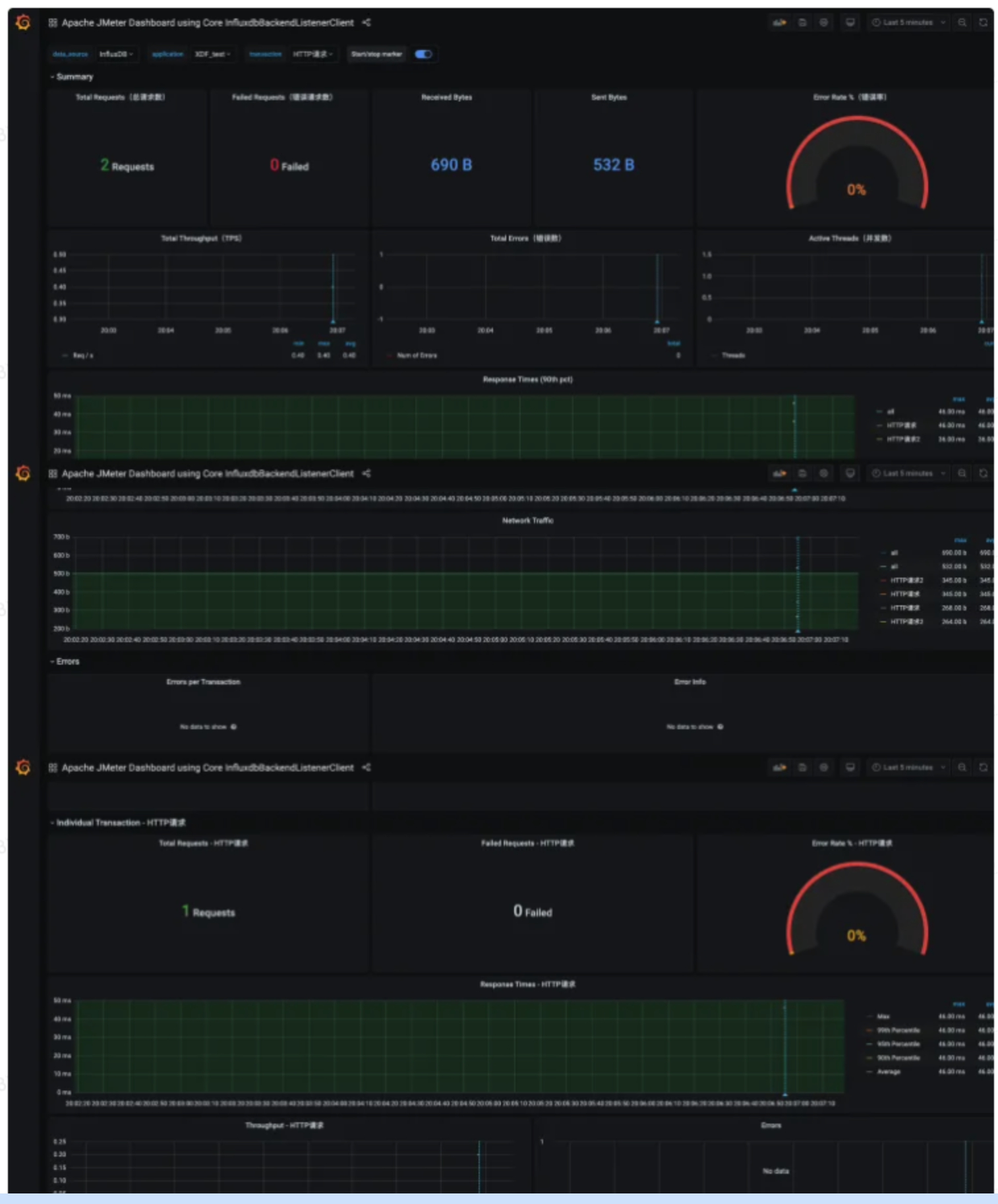
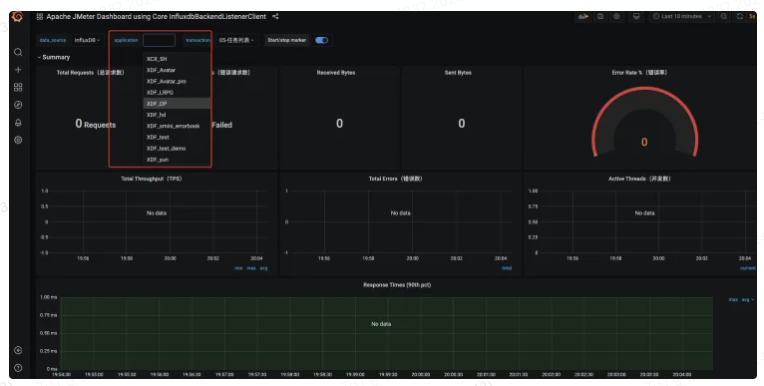
在正式执行压测脚本时,我们会使用非GUI模式运行压测脚本,此时我们需要有一个可视化的监控压测过程的图形化工具:grafana+influxdb,
Jmeter自带的“后端监听器”支持将压测过程中的数据写入influxdb中,grafana从influxdb中读取数据,展示在页面上。
首先添加后端监听器:
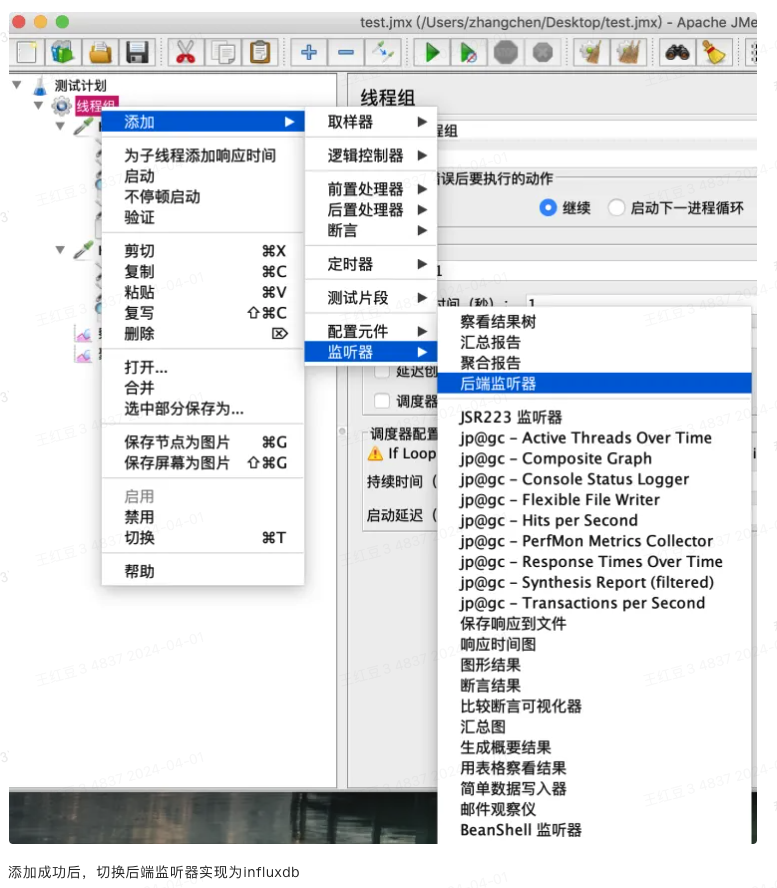

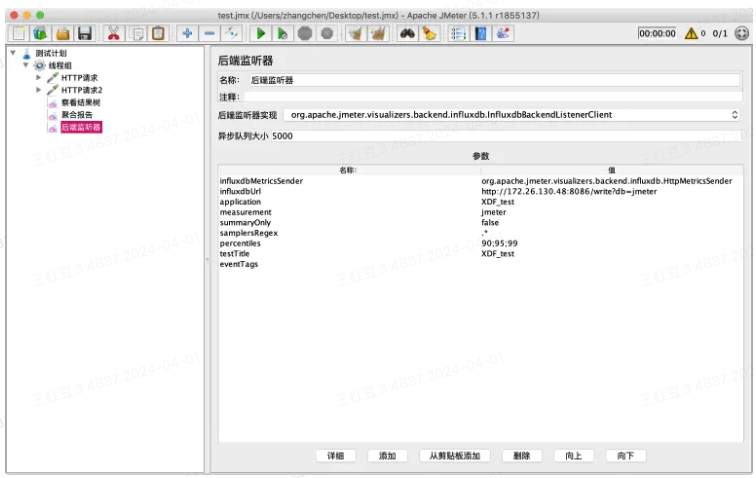
然后按照下图进行配置即可,之后再运行Jmeter,即可在grafana界面实时查看到相关压测数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号