

目录
一 概要
在了解Python的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list,set,dict comprehension)众多概念参杂在一起,难免让初学者一头雾水,我将用一篇文章试图将这些概念以及它们之间的关系捋清楚
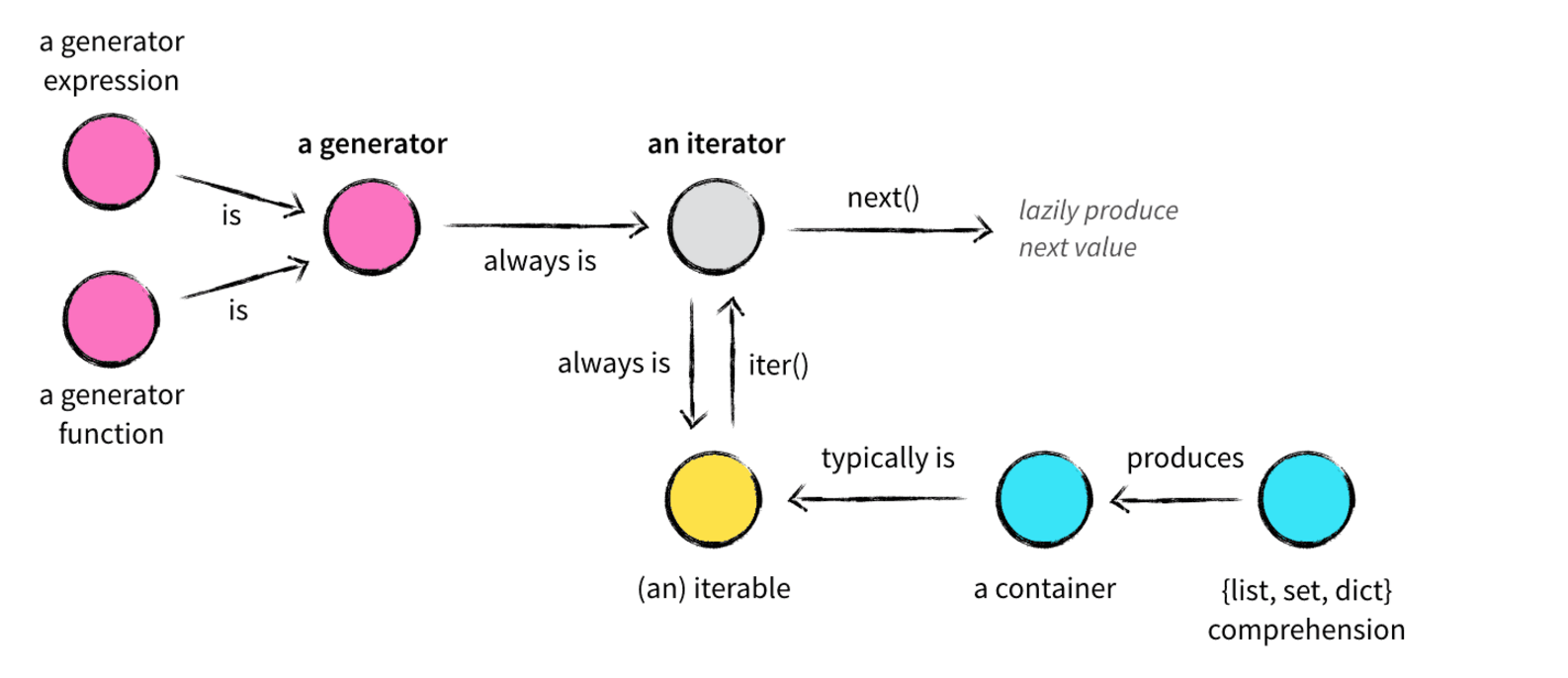
二 容器(container)
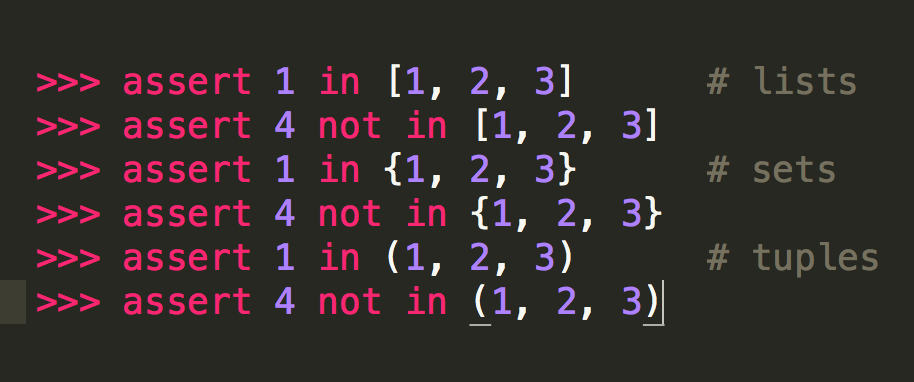
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用 in , not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特列并不是所有的元素都放在内存)在Python中,常见的容器对象有:
- list, deque, ....
- set, frozensets, ....
- dict, defaultdict, OrderedDict, Counter, ....
- tuple, namedtuple, …
- str
容器比较容易理解,因为你就可以把它看作是一个盒子、一栋房子、一个柜子,里面可以塞任何东西。从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器,比如 list,set,tuples都是容器对象:
尽管绝大多数容器都提供了某种方式来获取其中的每一个元素,但这并不是容器本身提供的能力,而是 可迭代对象 赋予了容器这种能力,当然并不是所有的容器都是可迭代的。
三 可迭代对象(iterable)
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
刚才说过,很多容器都是可迭代对象,此外还有更多的对象同样也是可迭代对象,比如处于打开状态的files,sockets等等。但凡是可以返回一个 迭代器 的对象都可称之为可迭代对象,听起来可能有点困惑,没关系,可迭代对象与迭代器有一个非常重要的区别。先看一个例子:

这里 x 是一个可迭代对象,可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型,list是可迭代对象,dict是可迭代对象,set也是可迭代对象。 y 和 z 是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。迭代器有一种具体的迭代器类型,比如 list_iterator , set_iterator 。可迭代对象实现了 __iter__ 和 __next__ 方法(python2中是 next 方法,python3是 __next__ 方法),这两个方法对应内置函数 iter() 和 next() 。 __iter__ 方法返回可迭代对象本身,这使得他既是一个可迭代对象同时也是一个迭代器。
四 迭代器(iterator)
那么什么迭代器呢?它是一个带状态的对象,他能在你调用 next() 方法的时候返回容器中的下一个值,任何实现了 __next__() (python2中实现 next() )方法的对象都是迭代器,至于它是如何实现的这并不重要。
现在我们就以斐波那契数列()为例,学习为何创建以及如何创建一个迭代器:
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...


def fab(max):
n, a, b = 0, 0, 1
while n < max:
print b
a, b = b, a + b
n = n + 1
直接在函数fab(max)中用print打印会导致函数的可复用性变差,因为fab返回None。其他函数无法获得fab函数返回的数列。
def fab(max):
L = []
n, a, b = 0, 0, 1
while n < max:
L.append(b)
a, b = b, a + b
n = n + 1
return L
代码2满足了可复用性的需求,但是占用了内存空间,最好不要。
对比for i in range(1000): pass和for i in xrange(1000): pass,前一个返回1000个元素的列表,而后一个在每次迭代中返回一个元素,因此可以使用迭代器来解决复用可占空间的问题
class Fab(object):
def __init__(self, max):
self.max = max
self.n, self.a, self.b = 0, 0, 1
def __iter__(self):
return self
def next(self):
if self.n < self.max:
r = self.b
self.a, self.b = self.b, self.a + self.b
self.n = self.n + 1
return r
raise StopIteration()
'''
>>> for key in Fabs(5):
print key
1
1
2
3
5
'''
Fabs 类通过 next() 不断返回数列的下一个数,内存占用始终为常数
Fib既是一个可迭代对象(因为它实现了 __iter__ 方法),又是一个迭代器(因为实现了 __next__ 方法)。实例变量 self .a 和 self.b 用户维护迭代器内部的状态。每次调用 next() 方法的时候做两件事:
- 为下一次调用 next() 方法修改状态
- 为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
五 for i in (iterable)的内部实现
在大多数情况下,我们不会一次次调用next方法去取值,而是通过 for i in (iterable),

![]()
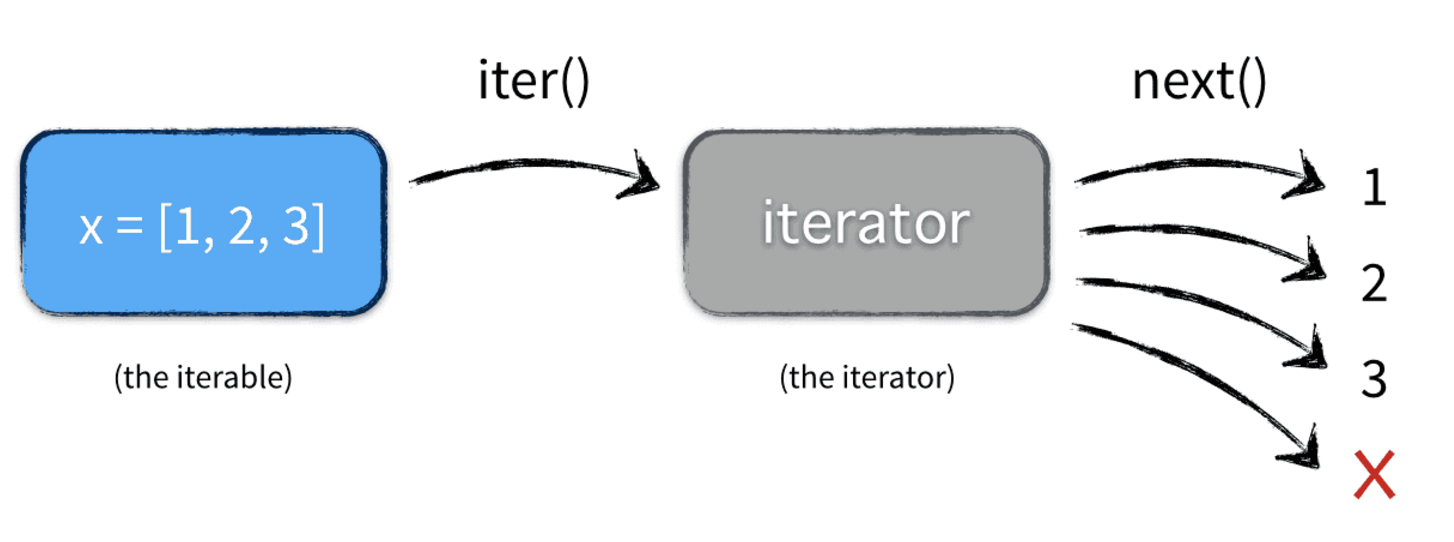
注意:in后面的对象如果是一个迭代器,内部因为有iter方法才可以进行操作,所以,迭代器协议里面有iter和next两个方法,否则for语句无法应用。
注意:
|
1
2
|
for i in range(10): print i :定时垃圾回收机制:没有引用指向这个对象,则被回收 |
六 生成器(generator)
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。代码3远没有代码1简洁,生成器(yield)既可以保持代码1的简洁性,又可以保持代码3的效果。它不需要再像上面的类一样写 __iter__() 和 __next__() 方法了,只需要一个 yiled 关键字。 生成器有如下特征是它一定也是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。用生成器来实现斐波那契数列的例子是:
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
>>> for n in fab(5):
print n
1
1
2
3
5
fib 就是一个普通的python函数,它特需的地方在于函数体中没有 return 关键字,函数的返回值是一个生成器对象。当执行 f=fib(5) 返回的是一个生成器对象,此时函数体中的代码并不会执行,只有显示或隐示地调用next的时候才会真正执行里面的代码。
yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。
也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程:
>>> f = fab(3)
>>> f.__next__()
1
>>> f.__next__()
1
>>> f.__next__()
2
>>> f.__next__()
Traceback (most recent call last):
File "<pyshell#62>", line 1, in <module>
f.next()
StopIteration
需要明确的就是生成器也是iterator迭代器,因为它遵循了迭代器协议.
两种创建方式
包含yield的函数
生成器函数跟普通函数只有一点不一样,就是把 return 换成yield,其中yield是一个语法糖,内部实现了迭代器协议,同时保持状态可以挂起。如下:
return:
在一个生成器中,如果没有return,则默认执行到函数完毕;如果遇到return,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代.
def f():
yield 5
print("ooo")
return
yield 6
print("ppp")
# if str(tem)=='None':
# print("ok")
f=f()
# print(f.__next__())
# print(f.__next__())
for i in f:
print(i)
'''
return即迭代结束
for不报错的原因是内部处理了迭代结束的这种情况
'''
注意:![]()

文件读取
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。
My:生成器对象就是一种特殊的迭代器对象,满足迭代器协议,可以调用next;对生成器对象for 循环时,调用iter方法返回了生成器对象,然后再不断next迭代,而iter和next都是在yield内部实现的。
练习1:使用文件读取,找出文件中最长的行的?
max(len(x.strip()) for x in open('/hello/abc','r'))
练习2:
def add(s, x):
return s + x
def gen():
for i in range(4):
yield i
base = gen()
for n in [1, 10]:
base = (add(i, n) for i in base)
print list(base)
'''
核心语句就是:
for n in [1, 10]:
base = (add(i, n) for i in base)
在执行list(base)的时候,开始检索,然后生成器开始运算了。关键是,这个循环次数是2,也就是说,有两次生成器表达
式的过程。必须牢牢把握住这一点。
生成器返回去开始运算,n = 10而不是1没问题吧,这个在上面提到的文章中已经提到了,就是add(i, n)绑定的是n这个
变量,而不是它当时的数值。
然后首先是第一次生成器表达式的执行过程:base = (10 + 0, 10 + 1, 10 + 2, 10 +3),这是第一次循环的结
果(形象表示,其实已经计算出来了(10,11,12,3)),然后第二次,
base = (10 + 10, 11 + 10, 12 + 10, 13 + 10) ,终于得到结果了[20, 21, 22, 23].
'''
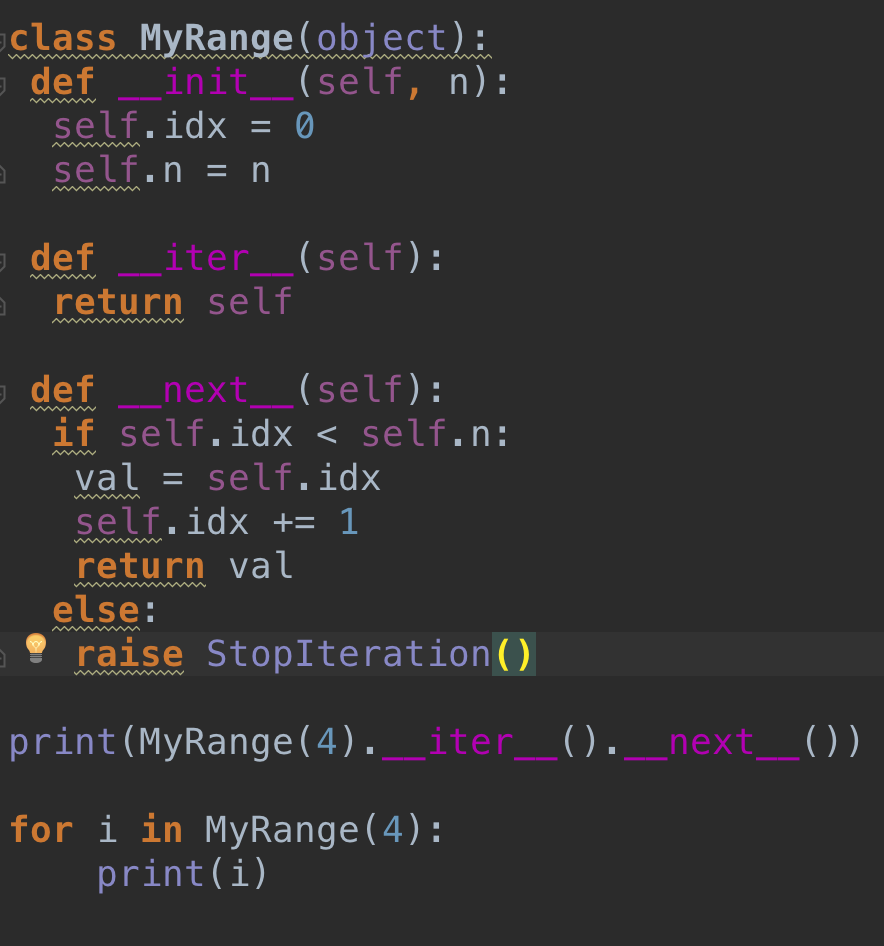
练习3:自定义range
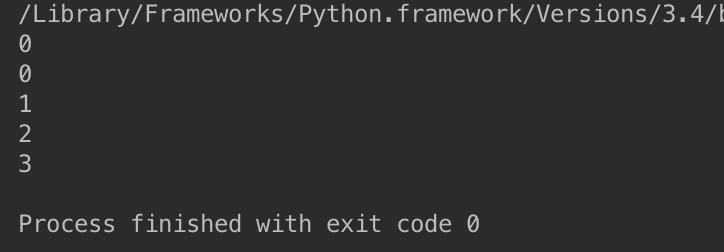
七 生成器的扩展
生成器对象支持几个方法,如gen.next() ,gen.send() ,gen.throw()等。
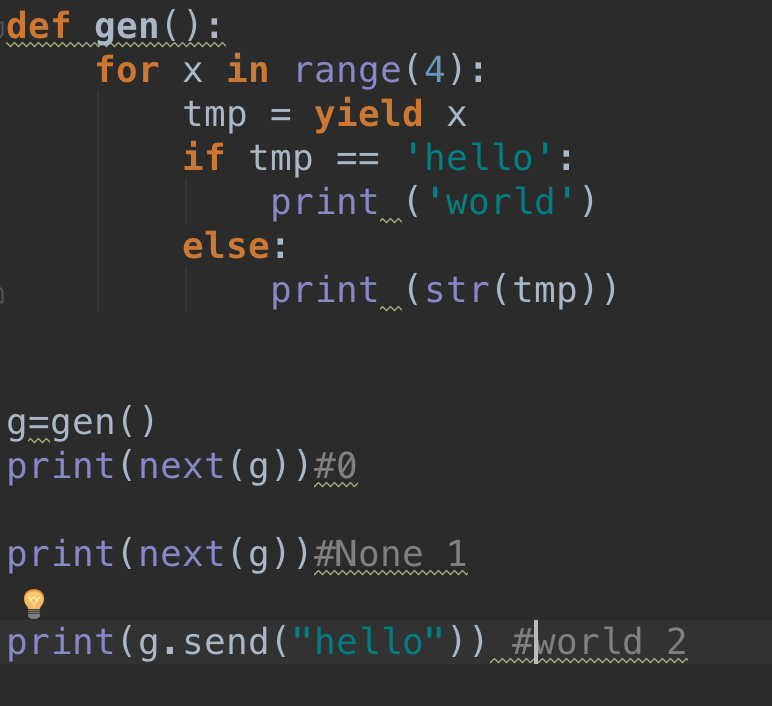
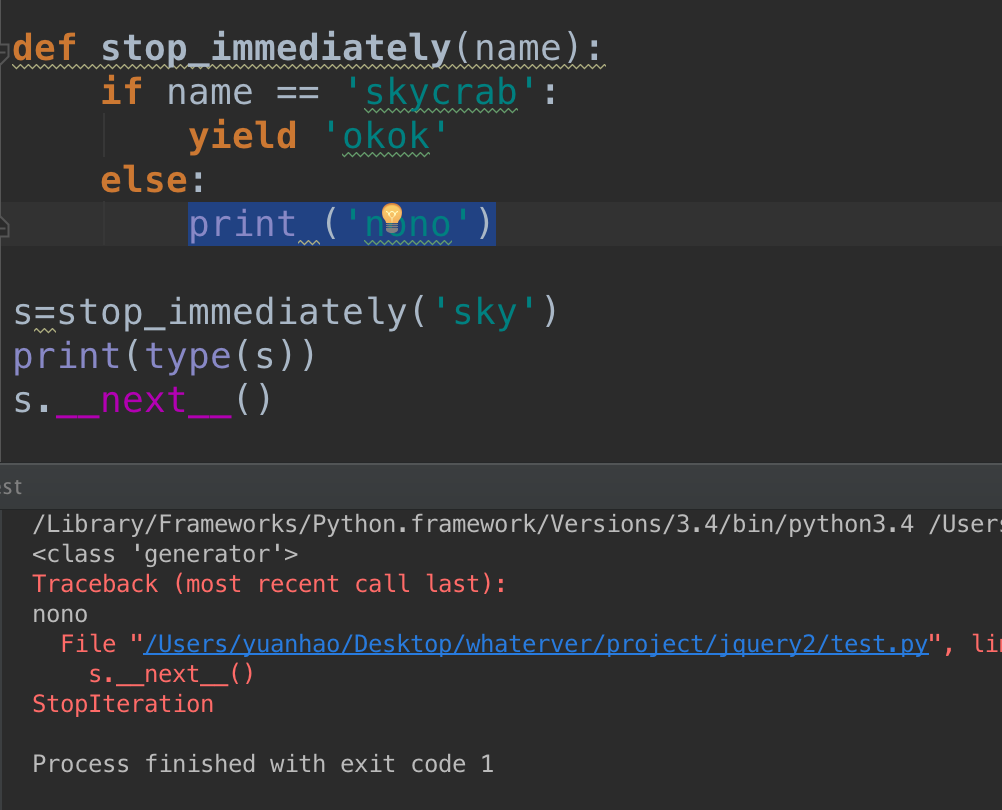
由于没有额外的yield,所以将直接抛出StopIteration。
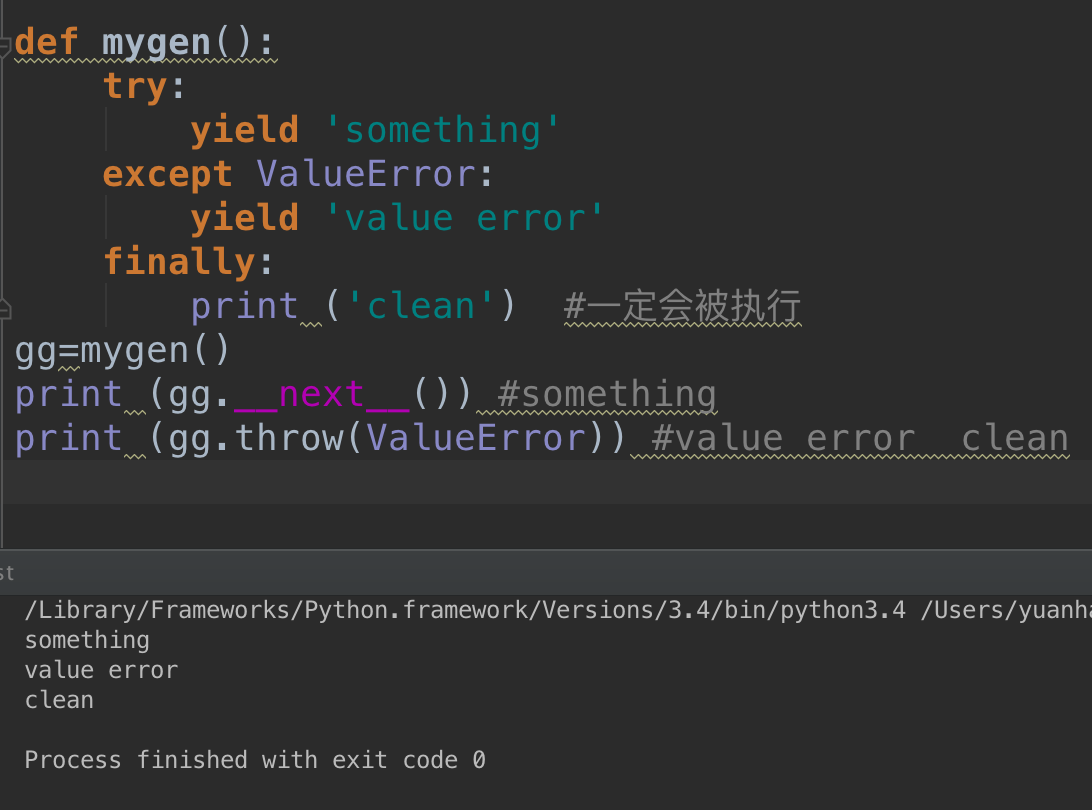
send的工作方式:
def f():
print("ok")
s=yield 7
print(s)
yield 8
f=f()
print(f.send(None))
print(next(f))
#print(f.send(None))等同于print(next(f)),执行流程:打印ok,yield7,当再next进来时:将None赋值给s,然后返回8,可以通过断点来观察
协程应用:
所谓协同程序也就是是可以挂起,恢复,有多个进入点。其实说白了,也就是说多个函数可以同时进行,可以相互之间发送消息等。
import queue
def tt():
for x in range(4):
print ('tt'+str(x) )
yield
def gg():
for x in range(4):
print ('xx'+str(x) )
yield
class Task():
def __init__(self):
self._queue = queue.Queue()
def add(self,gen):
self._queue.put(gen)
def run(self):
while not self._queue.empty():
for i in range(self._queue.qsize()):
try:
gen= self._queue.get()
gen.send(None)
except StopIteration:
pass
else:
self._queue.put(gen)
t=Task()
t.add(tt())
t.add(gg())
t.run()
# tt0
# xx0
# tt1
# xx1
# tt2
# xx2
# tt3
# xx3
参考:
http://anandology.com/python-practice-book/iterators.html
http://www.cnblogs.com/kaituorensheng/p/3826911.html
http://www.jb51.net/article/80740.htm
http://www.open-open.com/lib/view/open1463668934647.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号