
paddleocr 在docker环境下部署
paddleocr 在docker环境下部署
-
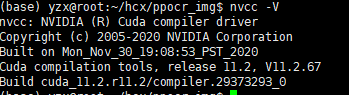
第一步 查看cuda的版本nvcc -V,我的是11.2;nvidia-smi 对应的cuda version是11.6,所以采用了registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.6-cudnn8.4-trt8.4-gcc82作为基础镜像
![]()
![]()
-
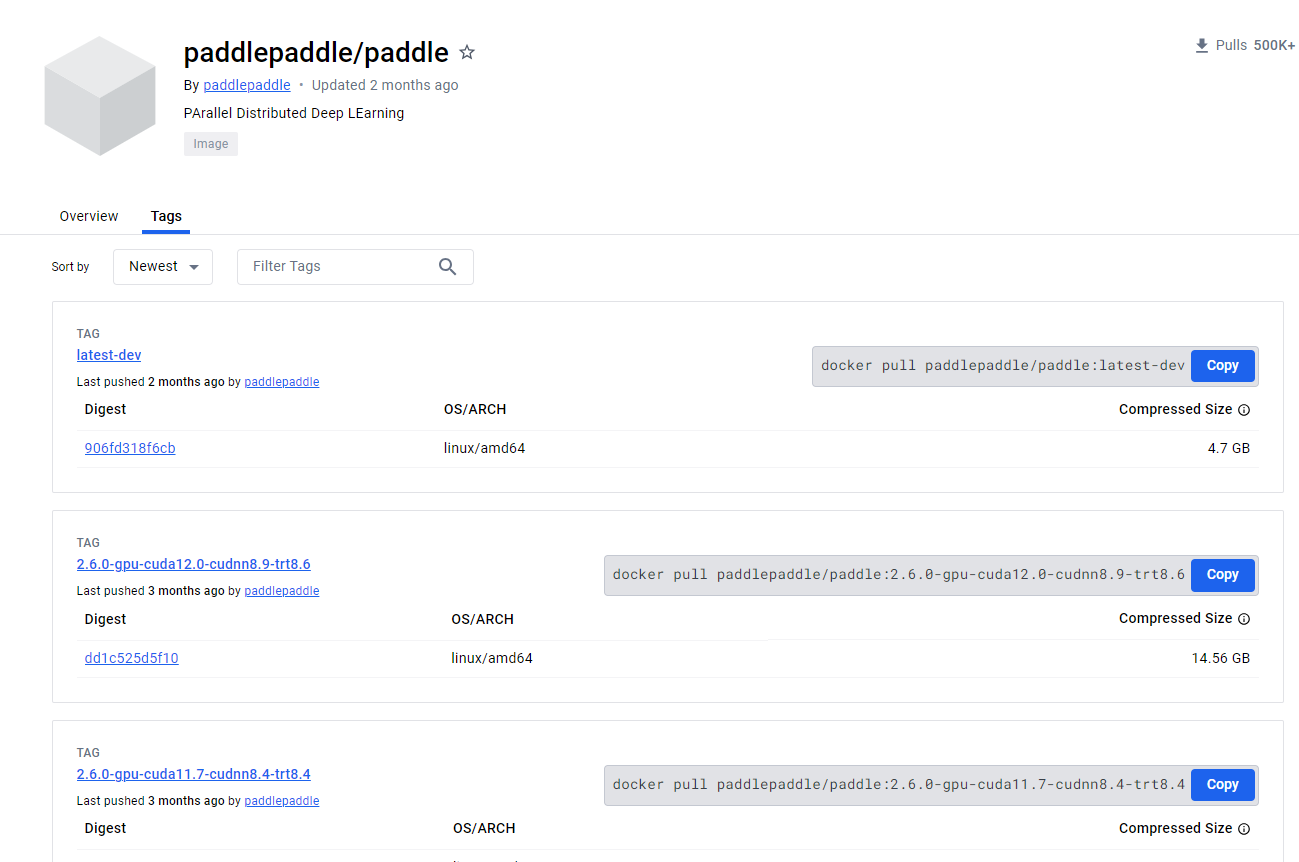
Docker镜像源选择,DockerHub地址
![]()
-
Dockerfile配置
FROM registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.6-cudnn8.4-trt8.4-gcc82 # 设置工作目录 WORKDIR /paddle ENV TZ=Asia/Shanghai \ DEBIAN_FRONTEND=noninteractive #将本地代码同步到镜像的/paddle目录下 copy . /paddle #安装python依赖环境 RUN python -m pip install paddlepaddle-gpu==0.0.0.post112 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html RUN pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple RUN pip install uvicorn -i https://pypi.tuna.tsinghua.edu.cn/simple RUN pip install python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple RUN pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple CMD ["python", "/paddle/main_ocr.py"] -
核心代码
## ocr_paddle.py from paddleocr import PaddleOCR, draw_ocr # Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换 # 例如`ch`, `en`, `fr`, `german`, `korean`, `japan` def ocr(file_name): ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory img_path = './uploads/'+file_name result = ocr.ocr(img_path, cls=True) final_txt=[] for idx in range(len(result)): res = result[idx] for line in res: final_txt.append(line[1][0]) print("\n".join(final_txt)) return "\n".join(final_txt)#main_ocr.py from fastapi import FastAPI, UploadFile, File import codecs import sys from fastapi.middleware.cors import CORSMiddleware from fastapi.responses import JSONResponse from ocr_paddle import ocr from PIL import Image import io app = FastAPI() app.add_middleware( CORSMiddleware, # 允许跨域的源列表,例如 ["http://www.example.org"] 等等,["*"] 表示允许任何源 allow_origins=["*"], # 跨域请求是否支持 cookie,默认是 False,如果为 True,allow_origins 必须为具体的源,不可以是 ["*"] allow_credentials=False, # 允许跨域请求的 HTTP 方法列表,默认是 ["GET"] allow_methods=["*"], # 允许跨域请求的 HTTP 请求头列表,默认是 [],可以使用 ["*"] 表示允许所有的请求头 # 当然 Accept、Accept-Language、Content-Language 以及 Content-Type 总之被允许的 allow_headers=["*"], # 可以被浏览器访问的响应头, 默认是 [],一般很少指定 # expose_headers=["*"] # 设定浏览器缓存 CORS 响应的最长时间,单位是秒。默认为 600,一般也很少指定 # max_age=1000 ) @app.post("/image2text/") async def image2text(file: UploadFile): # print(file.filename) try: # 检查文件是否上传成功 if file.content_type.startswith('image'): # 指定本地文件保存路径 with open(f"./uploads/{file.filename}", "wb") as f: f.write(file.file.read()) res=ocr(file.filename) return JSONResponse(content={"message": res}, status_code=200) else: return JSONResponse(content={"message": "Invalid file format. Only images are allowed."}, status_code=400) except Exception as e: return JSONResponse(content={"message": str(e)}, status_code=500) @app.post("/image2text2/") async def image2text2(image_bytes): print(image_bytes) status=0 res="" try: image_stream = io.BytesIO(image_bytes) # print(file.filename) # 指定图像文件的本地保存路径 save_path = "./uploads/image.png" image = Image.open(image_stream) # 保存图像到本地文件 image.save(save_path) status=200 res=ocr("image.png") except Exception as e: status=500 finally: # 关闭图像对象和二进制流 image.close() image_stream.close() return JSONResponse(content={"message": res}, status_code=status) # 在最下面加上 这一句 代替命令行启动 if __name__ == "__main__": import uvicorn uvicorn.run(app='main_ocr:app', host="0.0.0.0", port=8888, reload=True) -
制作镜像,build
docker build -t ppocr:1.0 . -
运行
nvidia-docker run --name ppocr --shm-size=64G --network=host -it ppocr:1.0

脚踏实地,注重基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号