
word2Vec实战解读
-
word2vec介绍
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
-
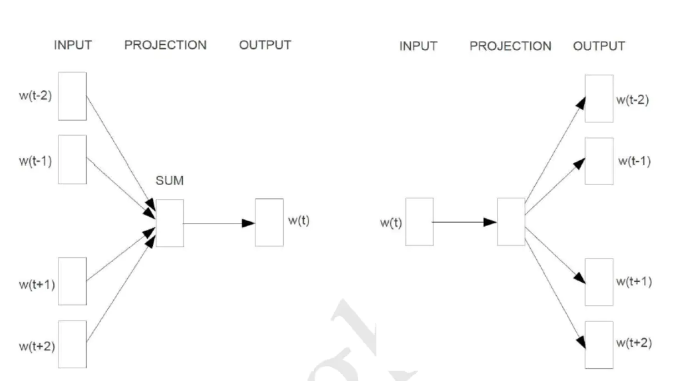
CBOW算法:CBOW是已知当前词的上下文,来预测当前词。
-
skip-gram算法:已知当前词的情况下,预测其上下文。
-
优缺点
-
skip-gram比Cbow准确率高,能更好的处理生僻字(即出现频率低的字)。因为在计算时,Cbow会将context word加起来,所以在遇到生僻词时预测效果将会大大降低,而skip-gram则会预测生僻字的使用环境
-
Cbow比skip-gram训练快
![]()
-
-
代码执行
- 下载源码,在TensorFlow-Examples\tensorflow_v1\examples\2_BasicModels\word2vec.py路径下,会找到word2vec.py文件。
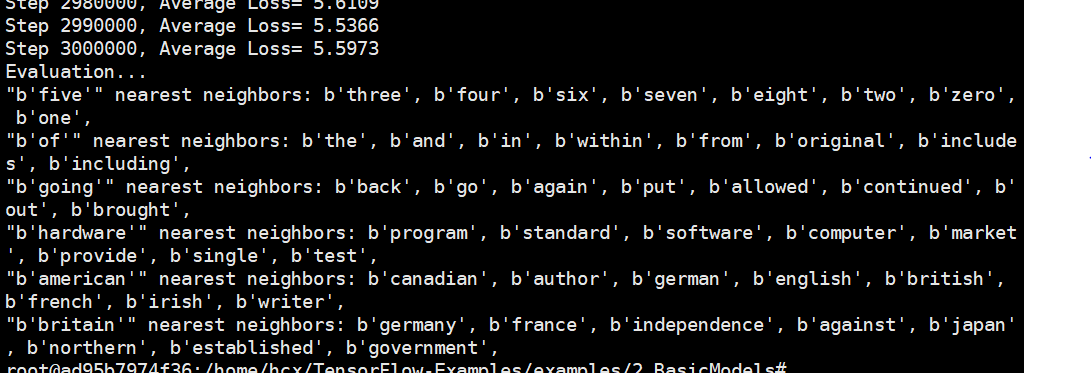
""" Word2Vec. Implement Word2Vec algorithm to compute vector representations of words. This example is using a small chunk of Wikipedia articles to train from. References: - Mikolov, Tomas et al. "Efficient Estimation of Word Representations in Vector Space.", 2013. Links: - [Word2Vec] https://arxiv.org/pdf/1301.3781.pdf Author: Aymeric Damien Project: https://github.com/aymericdamien/TensorFlow-Examples/ """ from __future__ import division, print_function, absolute_import import collections import os import random import urllib import zipfile import numpy as np import tensorflow as tf # Training Parameters learning_rate = 0.1 batch_size = 128 num_steps = 3000000 display_step = 10000 eval_step = 200000 # Evaluation Parameters#评价参数 eval_words = [b'five', b'of', b'going', b'hardware', b'american', b'britain'] # Word2Vec Parameters embedding_size = 200 # Dimension of the embedding vector max_vocabulary_size = 50000 # Total number of different words in the vocabulary min_occurrence = 10 # Remove all words that does not appears at least n times skip_window = 3 # How many words to consider left and right num_skips = 2 # How many times to reuse an input to generate a label num_sampled = 64 # Number of negative examples to sample # Download a small chunk of Wikipedia articles collection url = 'http://mattmahoney.net/dc/text8.zip' data_path = 'text8.zip' if not os.path.exists(data_path): print("Downloading the dataset... (It may take some time)") filename, _ = urllib.request.urlretrieve(url, data_path) print("Done!") # Unzip the dataset file. Text has already been processed with zipfile.ZipFile(data_path) as f: text_words = f.read(f.namelist()[0]).lower().split() # Build the dictionary and replace rare words with UNK token #构建字典,并用UNK令牌替换稀有单词 count = [('UNK', -1)] # Retrieve the most common words#检索最常用的单词 count.extend(collections.Counter(text_words).most_common(max_vocabulary_size - 1)) # Remove samples with less than 'min_occurrence' occurrences#删除小于'min_occurrence'的样本 #删除出现次数小于'min_occurrence'的样本 for i in range(len(count) - 1, -1, -1): if count[i][1] < min_occurrence: count.pop(i) else: # The collection is ordered, so stop when 'min_occurrence' is reached break # Compute the vocabulary size vocabulary_size = len(count) # Assign an id to each word word2id = dict() for i, (word, _)in enumerate(count): word2id[word] = i data = list() unk_count = 0 for word in text_words: # Retrieve a word id, or assign it index 0 ('UNK') if not in dictionary index = word2id.get(word, 0) if index == 0: unk_count += 1 data.append(index) count[0] = ('UNK', unk_count) id2word = dict(zip(word2id.values(), word2id.keys())) print("Words count:", len(text_words)) print("Unique words:", len(set(text_words))) print("Vocabulary size:", vocabulary_size) print("Most common words:", count[:10]) data_index = 0 # Generate training batch for the skip-gram model def next_batch(batch_size, num_skips, skip_window): global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) # get window size (words left and right + current one) span = 2 * skip_window + 1 buffer = collections.deque(maxlen=span) if data_index + span > len(data): data_index = 0 buffer.extend(data[data_index:data_index + span]) data_index += span for i in range(batch_size // num_skips): context_words = [w for w in range(span) if w != skip_window] words_to_use = random.sample(context_words, num_skips) for j, context_word in enumerate(words_to_use): batch[i * num_skips + j] = buffer[skip_window] labels[i * num_skips + j, 0] = buffer[context_word] if data_index == len(data): buffer.extend(data[0:span]) data_index = span else: buffer.append(data[data_index]) data_index += 1 # Backtrack a little bit to avoid skipping words in the end of a batch data_index = (data_index + len(data) - span) % len(data) return batch, labels # Input data X = tf.placeholder(tf.int32, shape=[None]) # Input label Y = tf.placeholder(tf.int32, shape=[None, 1]) # Ensure the following ops & var are assigned on CPU # (some ops are not compatible on GPU) with tf.device('/cpu:0'): # Create the embedding variable (each row represent a word embedding vector) embedding = tf.Variable(tf.random_normal([vocabulary_size, embedding_size])) # Lookup the corresponding embedding vectors for each sample in X X_embed = tf.nn.embedding_lookup(embedding, X) # Construct the variables for the NCE loss nce_weights = tf.Variable(tf.random_normal([vocabulary_size, embedding_size])) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) # Compute the average NCE loss for the batch loss_op = tf.reduce_mean( tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, labels=Y, inputs=X_embed, num_sampled=num_sampled, num_classes=vocabulary_size)) # Define the optimizer optimizer = tf.train.GradientDescentOptimizer(learning_rate) train_op = optimizer.minimize(loss_op) # Evaluation # Compute the cosine similarity between input data embedding and every embedding vectors X_embed_norm = X_embed / tf.sqrt(tf.reduce_sum(tf.square(X_embed))) embedding_norm = embedding / tf.sqrt(tf.reduce_sum(tf.square(embedding), 1, keepdims=True)) cosine_sim_op = tf.matmul(X_embed_norm, embedding_norm, transpose_b=True) # Initialize the variables (i.e. assign their default value) init = tf.global_variables_initializer() with tf.Session() as sess: # Run the initializer sess.run(init) # Testing data x_test = np.array([word2id[w] for w in eval_words]) average_loss = 0 for step in range(1, num_steps + 1): # Get a new batch of data batch_x, batch_y = next_batch(batch_size, num_skips, skip_window) # Run training op _, loss = sess.run([train_op, loss_op], feed_dict={X: batch_x, Y: batch_y}) average_loss += loss if step % display_step == 0 or step == 1: if step > 1: average_loss /= display_step print("Step " + str(step) + ", Average Loss= " + \ "{:.4f}".format(average_loss)) average_loss = 0 # Evaluation if step % eval_step == 0 or step == 1: print("Evaluation...") sim = sess.run(cosine_sim_op, feed_dict={X: x_test}) for i in range(len(eval_words)): top_k = 8 # number of nearest neighbors nearest = (-sim[i, :]).argsort()[1:top_k + 1] log_str = '"%s" nearest neighbors:' % eval_words[i] for k in range(top_k): log_str = '%s %s,' % (log_str, id2word[nearest[k]]) print(log_str) -
运行结果
![]()
脚踏实地,注重基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号