
基于BERT的中文情感分类(TensorFlow)
-
TensorFlow环境
官方requirements.txt要求环境版本
tensorflow >= 1.11.0 # CPU Version of TensorFlow
tensorflow-gpu >= 1.11.0 # GPU version of TensorFlow.本人实现代码TensorFlow环境版本
tensorflow 1.15.0
tensorflow-estimator 1.15.1
tensorflow-gpu 1.15.0python=3.6
-
数据集
数据情感标注:[0,1,2]=>正 中 负
1 最大的优点也就是价钱比较实惠,另外有免费停车场如果住在古镇里面,白天是不允许把车开进去的。这个宾馆的服务员都说自己的餐厅做的当地小吃好吃,实在不敢苟同,份量少,味道也不地道,价格却不低,建议重视当地美食的朋友不要在宾馆的餐厅就餐,会对山西的小吃产生错误 2 2 华为回应CFO孟晚舟在加拿大被捕不实报道 2 3 这个配置和价位真的很合适,完全够用,而且小黑的质量非常不错。 1 4 待机长,色彩鲜艳,屏幕大,成象效果好,我用了飞利浦535、T628等手机,在价格上比GD88要贵,可是实际效果比上两款手要好很多,真的!或许在时尚的外观上不如,但是最后还是选择了GD88!! 0 5 之前2次是10月中旬的时候住的,记忆不是很深刻了,但是即使我再怎么不满意,我后来还是定了这里,而且一直跟朋友推荐这里,然后这次的经历真的是让我极度不爽!CTRIP预定的房间,大床,以前这样的大床,158还是168,现在的大床就是当初这样的房间,房价200多 0 6 装系统比较麻烦,建议找专业人员安装。桌面图标太大,不太美观。 2 7 这款手机是直板机中的一个突破,设计注重人性化,操作简单易于上手。商务功能强大,可以称得上是性价比最高的彩屏手机。其主要优势有以下几个方面1.机身质感较强,既美观手感也很好2.屏幕大,显示效果不错3.键盘手感舒适4.支持JAVA功能5.有录 1 -
BERT_Chinese_Classification源码地址
-
代码目录
-
代码运行流程
-
下载BERT_Chinese_Classification源码;
-
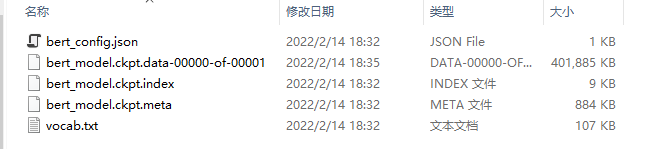
从google提供的BERT官方下载中文BERT预训练模型chinese_L-12_H-768_A-12,将其放到BERT_Chinese_Classification目录下;
""" 其中 bert_model.ckpt开头的文件是负责模型变量载入的 vocab.txt是训练时中文文本采用的字典 bert_config.json是BERT在训练时,可选调整的一些参数 """
-
修改run_classifier.py文件,针对不同的训练数据【train、test、dev数据集】进行修改Processor;
#继承DataProcessor模块,针对自己的数据集,重写里面的数据获取方法 class DataProcessor(object): """Base class for data converters for sequence classification data sets.""" def get_train_examples(self, data_dir): """Gets a collection of `InputExample`s for the train set.""" raise NotImplementedError() def get_dev_examples(self, data_dir): """Gets a collection of `InputExample`s for the dev set.""" raise NotImplementedError() def get_test_examples(self, data_dir): """Gets a collection of `InputExample`s for prediction.""" raise NotImplementedError() def get_labels(self): """Gets the list of labels for this data set.""" raise NotImplementedError() #例如中文情感分类,可以写一个SimProcessor(DataProcessor)模块 def SimProcessor(DataProcessor): def get_train_examples(self, data_dir): file_path = os.path.join(data_dir, 'train_sentiment.txt') f = open(file_path, 'r', encoding='utf-8') train_data = [] index = 0 for line in f.readlines(): guid = 'train-%d' % index # 参数guid是用来区分每个example的 line = line.replace("\n", "").split("\t") text_a = tokenization.convert_to_unicode(str(line[1])) # 要分类的文本 label = str(line[2]) # 文本对应的情感类别 train_data.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) # 加入到InputExample列表中 index += 1 return train_data #.....略 -
修改processor字典
processors = { "cola": ColaProcessor, "mnli": MnliProcessor, "mrpc": MrpcProcessor, "xnli": XnliProcessor, "sim": SimProcessor,#添加相应的字典,其中sim可自己设计! } -
训练
#运行run_classfier.py进行训练 #可以写一个train.sh,代码如下 #!/usr/bin/env bash export BERT_BASE_DIR=/home/hcx/BERT_Chinese_Classification/chinese_L-12_H-768_A-12 #中文BERT模型地址 export Data_DIR=/home/hcx/BERT_Chinese_Classification/data #数据集地址 python3.6 run_classifier.py \ --data_dir=$Data_DIR \ #训练数据目录 --task_name=sim \ #运行的任务名 与processor字典相对应。 --vocab_file=$BERT_BASE_DIR/vocab.txt \ #模型的词典(中文) --bert_config_file=$BERT_BASE_DIR/bert_config.json \ #BERT的配置(超参数),比如网络的层数,通常我们不需要修改,但是也会经常用到。 --output_dir=sim_model \ # 训练得到的模型的存放目录 --do_train=true \ #是否训练,这里为True --do_eval=true \ #是否在训练结束后验证,这里为True --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ #预训练好的模型的checkpoint --max_seq_length=70 \ #Token序列的最大长度 --train_batch_size=32 \ #batch大小,对于普通8GB的GPU,最大batch大小只能是8,再大就会OOM --learning_rate=5e-5 \ --num_train_epochs=3.0 #训练的epoch次数,根据任务进行调整执行命令:sh ./train.sh,训练成功结果!

-
进行测试
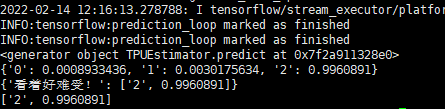
#测试代码test_predict.py from predict import predicts import sys import codecs sys.stdout = codecs.getwriter('utf-8')(sys.stdout.detach()) contents = ['看着好难受!'] predict_result = predicts(contents) print(predict_result) for pre in zip(predict_result): print(predict_result[pre[0]])执行python3 test_predict.py,查看成功结果!
-
脚踏实地,注重基础。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)