Http发展史
HTTP 是浏览器与服务端之间最主要的通信协议。
20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,这被认为是互联网的起源。70 年代,研究人员基于对 ARPA 网的实践和思考,发明出了著名的 TCP/IP 协议。该协议具有良好的分层结构和稳定的性能,并在 80 年代中期进入了 UNIX 系统内核,促使更多的计算机接入了网络。
1989 年,蒂姆伯纳斯-李博士发表了一篇论文,提出了在互联网上构建超链接文档系统的构想。在篇文章中他确立了三项关键技术:URI、HTML、HTTP。
基于这三项技术,可以把超文本系统完美地运行在互联网上,李博士把这个系统称为“万维网”(World Wide Web)。
HTTP/0.9
1991 年 HTTP(HyperText Transfer Protocol,超文本传输协议)正式诞生,当时的版本是 0.9。从名字可以看出,该协议的作用是传输传输超文本内容 HTML。
协议定义了客户端发起请求、服务端响应请求的通信模式。请求报文内容只有 1 行:
GET + 请求的文件路径
服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档。
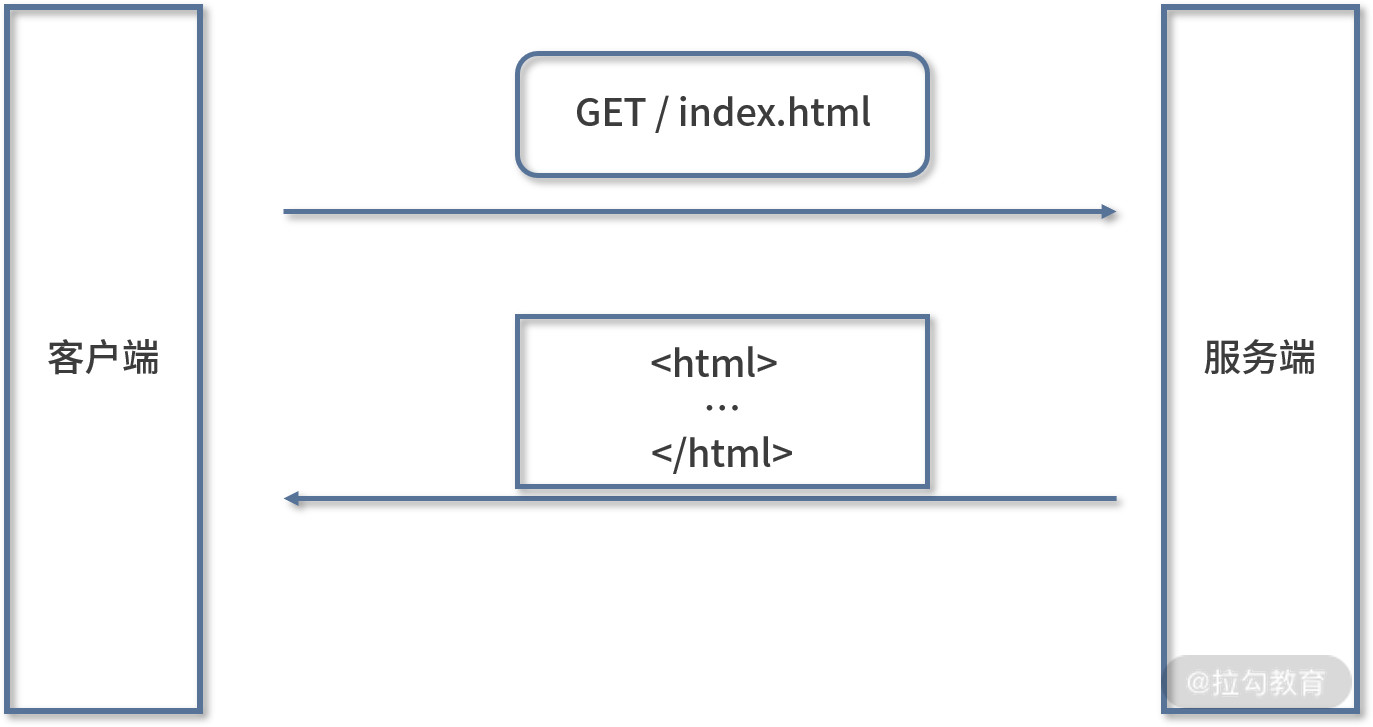
HTTP/0.9 虽然简单,但是它充分验证了 Web 服务的可行性:
把简单的系统变复杂,要比把复杂的系统变简单容易得多。
HTTP/1.0
随着互联网的发展以及浏览器的出现,单纯的文本内容已经无法满足用户需求了,浏览器希望通过 HTTP 来传输脚本、样式、图片、音频和视频等不同类型的文件,所以在 1996 年 HTTP 更新的 1.0 版本中引入了如下特性:
增加了 HEAD、POST 等新方法
增加了响应状态码,标记可能的错误原因
引入了协议版本号概念
引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活
传输的数据不再局限于文本
其中最核心的改变是增加了头部设定,头部内容以键值对的形式设置。请求头部通过 Accept 字段来告诉服务端可以接收的文件类型,响应头部再通过 Content-Type 字段来告诉浏览器返回文件的类型。
头部字段不仅用于解决不同类型文件传输的问题,也可以实现其他很多功能如缓存、认证信息等。

但是 HTTP/1.0 并不是一个“标准”,只是一份参考文档,不具有实际的约束力。
HTTP/1.1
随着互联网的迅速发展,HTTP/1.0 也已经无法满足需求,最核心的就是连接问题。
具体来说就是 HTTP/1.0 每进行一次通信,都需要经历建立连接、传输数据和断开连接三个阶段。当一个页面引用了较多的外部文件时,这个建立连接和断开连接的过程就会增加大量网络开销。
为了解决 HTTP/1.0 的问题,1999 年推出的 HTTP/1.1 有以下特点:
长连接(Connection:keep-alive):引入了 TCP 连接复用,即一个 TCP 默认不关闭,可以被多个请求复用
并发连接:对一个域名的请求允许分配多个长连接(缓解了长连接中的「队头阻塞」问题)
引入管道机制,一个 TCP 连接,可以同时发送多个请求。(响应的顺序必须和请求的顺序一致,因此不常用)
增加了 PUT、DELETE、OPTIONS、PATCH 等新的方法
新增缓存字段(cache-control E-tag)
请求头中引入了 range 字段,支持断点续传
允许响应数据分块(chunked),利于传输大文件
强制要求 Host 头,让互联网主机托管称为可能

HTTP/1.1 与 HTTP/1.0 的一个重要区别是:
HTTP/1.1 是一个“正式的标准”
此后互联网上所有的浏览器、服务器、网关、代理等,只要用到 HTTP 协议,就必须严格遵守这个标准。
HTTP/2
HTTP/1.1 通过长连接减少了大量创建/断开连接造成的性能消耗,但是它的并发能力受到限制,表现在两个方面:
HTTP/1.1 中使用持久连接时,一个连接中同一时刻只能处理一个请求。当前的请求没有结束之前,其他的请求只能处于阻塞状态,这种情况被称为「队头阻塞」
浏览器为了减轻服务器的压力,限制了同一个域名下的 HTTP 连接数,即 6 ~ 8 个
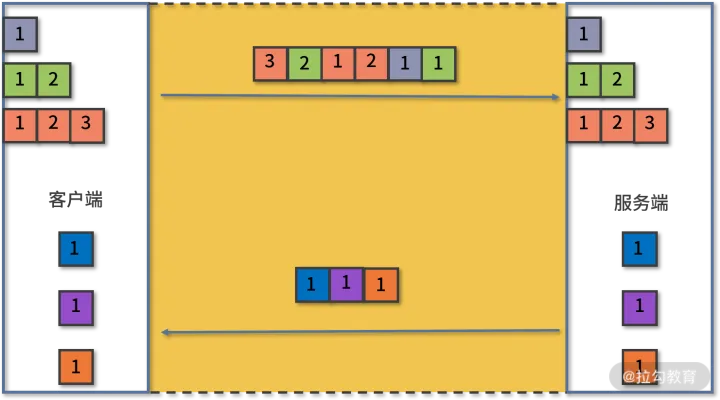
2015 年正式发布的 HTTP/2 默认不再使用 ASCII 编码传输,而是改为二进制数据,来提升传输效率。
客户端在发送请求时会将每个请求的内容封装成不同的带有编号的二进制帧(Frame),然后将这些帧同时发送给服务端。服务端接收到数据之后,会将相同编号的帧合并为完整的请求信息。同样,服务端返回结果、客户端接收结果也遵循这个帧的拆分与组合的过程。
有了二进制分帧后,对于同一个域,客户端只需要与服务端建立一个连接即可完成通信需求,这种利用一个连接来发送多个请求的方式称为「多路复用」。每一条路都被称为一个 stream(流)。
HTTP/2.0 的主要改动包括:
数据通过二进制协议传输,不再是纯文本
多路复用,废弃了 1.1 中的管道
使用专用算法压缩头部,减少数据传输量
通过设置数据帧的优先级,让服务器优先处理某些请求
允许服务器主动向客户推送数据
头部字段全部改为小写;引入了伪头部的概念,出现在头部字段之前,以冒号开头
增强了安全性,“事实上”要求加密通信
HTTP/2.0 虽然已经发布了 6 年,不过由于 HTTP/1.1 实在太过经典和强势,目前 HTTP/2.0 的普及率还比较低,仍然有很多网站使用的是 HTTP/1.1 版本。
HTTP/3
当然 HTTP/2 也并非完美,如果客户端或服务端在通信时出现数据包丢失,或者任何一方的网络出现中断,那么整个 TCP 连接就会暂停。
HTTP/2 由于采用二进制分帧进行多路复用,通常只使用一个 TCP 连接进行传输,在丢包或网络中断的情况下后面的所有数据都被阻塞。
但对于 HTTP/1.1 来说,可以开启多个 TCP 连接,任何一个 TCP 出现问题都不会影响其他 TCP 连接,剩余的 TCP 连接还可以正常传输数据。这种情况下 HTTP/2 的表现就不如 HTTP/1 了。
2018 年 HTTP/3 将底层依赖的 TCP 改成 UDP,从而彻底解决了这个问题。UDP 相对于 TCP 而言最大的特点是传输数据时不需要建立连接,可以同时发送多个数据包,所以传输效率很高,缺点就是没有确认机制来保证对方一定能收到数据。
总结
| 版本 | 解决的核心问题 | 解决的方法 |
|---|---|---|
| 0.9 | HTML 文件传输 | 确立了客户端请求、服务端响应的通信流程 |
| 1.0 | 不同类型文件传输 | 设立头部字段 |
| 1.1 | 创建/断开 TCP 连接开销大 | 建立长连接进行复用(一个请求多个连接) |
| 2 | 并发数有限 | 二进制分帧、多路复用 |
| 3 | TCP 丢包阻塞 | 采用 UDP 协议 |
HTTP 1.0: GET + 请求的文件路径,服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档。
HTTP 1.0:支持最基本的 GET、POST 方法、引入 header、传输的数据不局限于纯文本
HTTP 1.1:增减缓存策略、支持长连接、支持断点续传,状态码 206、支持新的方法 PUT,DELETE 等,可用于 Restful API
HTTP 2.0:数据通过二进制协议传输、支持压缩 header,减少体积、多路复用,一次 TCP 连接中可以多个 HTTP 并行请求、服务端推送

 浙公网安备 33010602011771号
浙公网安备 33010602011771号