

第七次作业(补交)
原因:五一假期忘了
1.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
Spark SQL 的前身是 Shark ,即"Hive on Spark",由 Reynold Xin 主导开发。Shark 项目最初启动于 2011 年,当时 Hive 几乎算是唯一的 SQL-on-Hadoop 选择方案。Hive 将 SQL 语句翻译为 MapReduce ,性能会受限于 MapReduce 计算模型,始终无法满足各种交互式 SQL 分析的需求,因此许多机构仍然依赖传统的企业数据仓库( EDW )。Shark 的提出就是针对这种需求的,目标是既能够达到 EDW 的性能,又能够具有 MapReduce 的水平扩展功能。Shark 建立在 Hive 代码的基础上,只修改了内存管理、物理计划、执行 3 个模块中的部分逻辑。Shark 通过将 Hive 的部分物理执行计划交换出来(“swapping out the physical execution engine part of Hive"),最终将 HiveQL 转换为 Spark 的计算模型,使之能运行在 Spark 引擎上,从而使得 SQL 査询的速度得到 10 ~ 100 倍的提升。此外, Shark 的最大特性是与 Hive 完全兼容,并且支持用户编写机器学习或数据处理函数,对 HiveQL 执行结果进行进一步分析。
2. 简述RDD 和DataFrame的联系与区别?
RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是模式(schema)。
3.DataFrame的创建
spark.read.text(url)
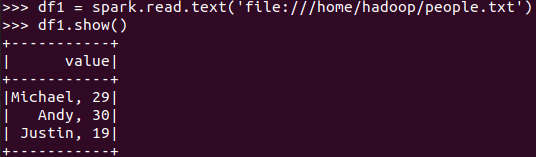
spark.read.json(url)
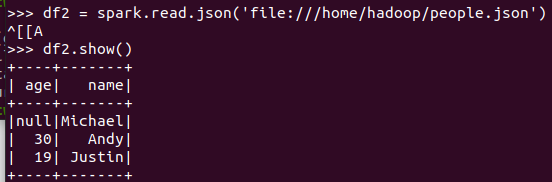
spark.read.format("text").load("people.txt")

spark.read.format("json").load("people.json")

描述从不同文件类型生成DataFrame的区别。
txt生成的无结构
json生成的有结构
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。

RDD直接输出对象集合
DataFrame输出ROW对象集合
4. PySpark-DataFrame各种常用操作
4.1基于df的操作:
打印数据 df.show()默认打印前20条数据

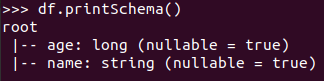
打印概要 df.printSchema()
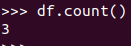
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

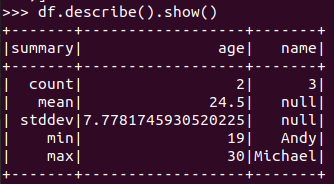
查询概况 df.describe().show()
取列 df[‘name’], df.name, df[1]

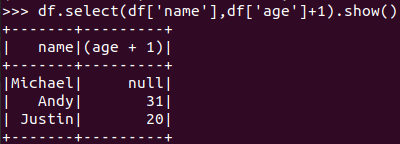
选择 df.select() 每个人的年龄+1
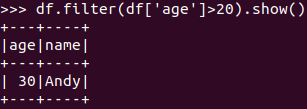
筛选 df.filter() 20岁以上的人员信息
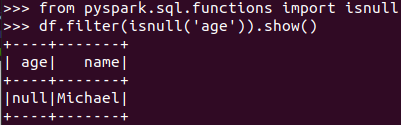
筛选年龄为空的人员信息
分组df.groupBy() 统计每个年龄的人数

排序df.sortBy() 按年龄进行排序
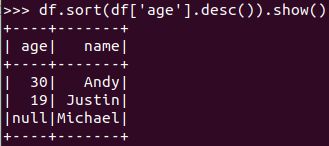
4.2 基于spark.sql的操作:
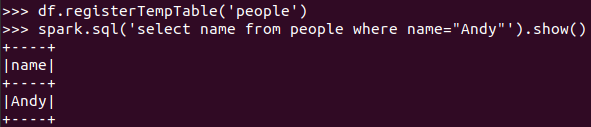
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句 spark.sql('select name from people').show()
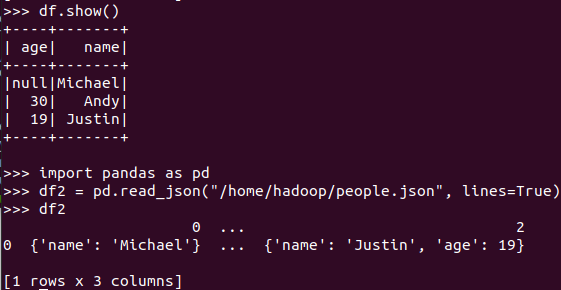
5. Pyspark中DataFrame与pandas中DataFrame
分别从文件创建DataFrame
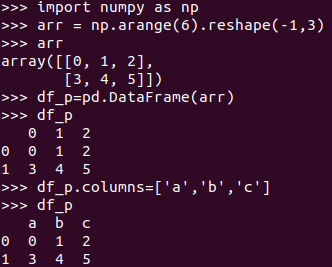
pandas中DataFrame转换为Pyspark中DataFrame
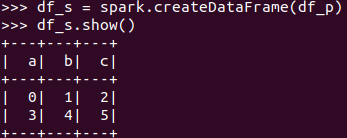
Pyspark中DataFrame转换为pandas中DataFrame
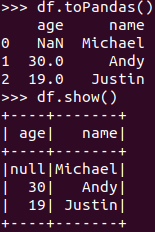
从创建与操作上,比较两者的异同
pandas创建的有索引,而DataFrame的没有


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通