


设计模式
UML支持13种图,可分为两大类
结构图:类图、组合结构图、构件图、部署图、对象图、包图
行为图:活动图、交互图(顺序图、通信图、交互概览图、时序图)、用例图、状态图
主要作用:
- 数据流图-功能建模
- 实体联系图-数据建模
- 状态迁移图-行为建模
开发模型
V模型:包括低层测试又包括了高层测试,低层测试是为了确保源代码的正确性,高层测试是为了使整个系统满足用户的需求
H模型:强调的是测试准备与测试实施的分离,而不是紧密结合
瀑布模型:以文档为驱动,适合于软件需求明确的软件项目模型
原型模型:需求不明确情况下,快速开发出一个原型
喷泉模型:以对象为驱动,适合面向对象的开发方法
螺旋模型:项目失败风险较低,预知开发的风险
关系代数
常见的关系运算:并、差、交、选择、投影、连接

数据的表示
采用8位整数,数据的表示范围
原码:-127~+127
反码:-127~+127
补码:-128~+127
详细设计的基本任务
- 数据库物理设计
- 模块算法
- 数据结构设计
- 其他设计
软件维护阶段
- 正确性维护:改正在开发阶段发现的错误
- 适应性维护:使软件适应信息技术变化和管理需求变化而进行的修改
- 完善性维护:是为了扩充功能和改善性能而进行的修改
- 预防性维护:为了适应未来的软硬件环境的变化
维护行为
- 改正性维护:诊断和改正这些隐蔽错误而修改软件
- 适应性维护:适用变化了环境而修改软件
- 完善性维护:扩充或完善原有软件功能或性能而修改软件
- 预防性维护:为了提高软件的可维护性和可靠性,增强可读性,而修改软件你
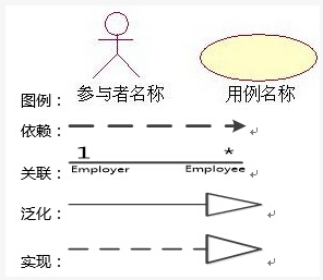
用例图
作用:可用来对功能需求建模
注意:泛化就是继承

极限编程XP
- 四个部分组成
- 四个价值观
- 五大原则
耦合
非直接耦合: 两个模块之间没有直接关系,它们的联系完全是通过主模块的控制和调用来实现的。
数据耦合: 两个模块彼此间通过数据参数交换信息。
标记耦合: 一组模块通过参数表传递记录信息,这个记录是某一个数据结构的子结构,而不是简单变量。
控制耦合: 两个模块彼此间传递的信息中有控制信息。
外部耦合: 一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息
公共耦合: 两个模块之间通过一个公共的数据区域传递信息。
内容耦合: 一个模块需要涉及到另一个模块的内部信息。
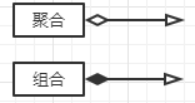
内聚
巧合聚合: 模块完成的动作之间没有任何关系,或者仅仅是一种非常松散的关系。
逻辑聚合: 模块内部的各个组成在逻辑上具有相似的处理动作,但功能用途上彼此无关。
时间聚合: 模块内部的各个组成部分所包含的处理动作必须在同一时间内执行。
过程聚合: 按特定的次序执行。
通信聚合: 模块的各个组成部分所完成的动作都使用了同一个数据或产生同一输出数据。
顺序聚合: 模块内部的各个部分,前一部分处理动作的最后输出是后一部分处理动作的输入。
功能聚合: 模块内部各个部分全部属于一个整体,并执行同一功能,且各部分对实现该功能都比不可少
软件设计
包括概要设计、详细设计
概要设计
- 体系结构设计
- 模块划分
- 数据结构、数据库设计
- 编写设计文档、评审
知识点
松弛时间:关键路径-所在路径的长度
结构化开发方法:自顶向下、功能的分解抽象、面向数据流、适合数据处理领域的问题,不适合解决大规模复杂项目,难以适应需求的变化
结构化分析的输出包括:数据流图、数据字典、加工逻辑
数据字典:为数据流图中的每个数据流、文件、加工,以及组成数据流或文件的数据项做说明
数据字典包含:数据流、数据项、数据存储、数据加工
加工:描述了输入数据流到输出数据流之间的变换
数据流图:用于行为建模,包含了加工,不能表示实体之间的关系和清晰地表达加工的处理过程
--参考链接
https://www.cnblogs.com/poloyy/category/1625646.html

