
LinkedHashMap源码分析
LinkedHashMap源码分析
简介
首先看一下LinkedHashMap继承体系:
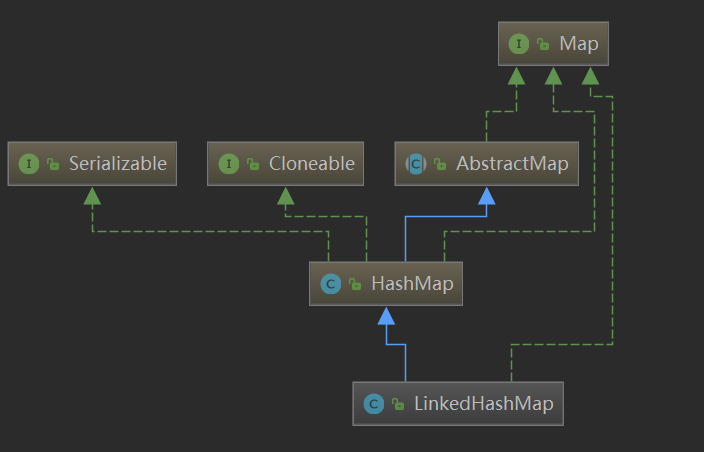
LinkedHashMap继承HashMap,拥有HashMap的全部特性,所以必须对HashMap源码有一定了解(本文也基于此基础讲解)。
LinkedHashMap在HashMap的基础上增加了有序迭代的特性,这也是其核心功能,保证访问时能够:
- 按插入顺序访问
- 按访问顺序访问
数据结构
为了实现有序迭代的功能,LinkedHashMap在HashMap的数据结构上新增一个双向链表来维护所有元素的顺序。
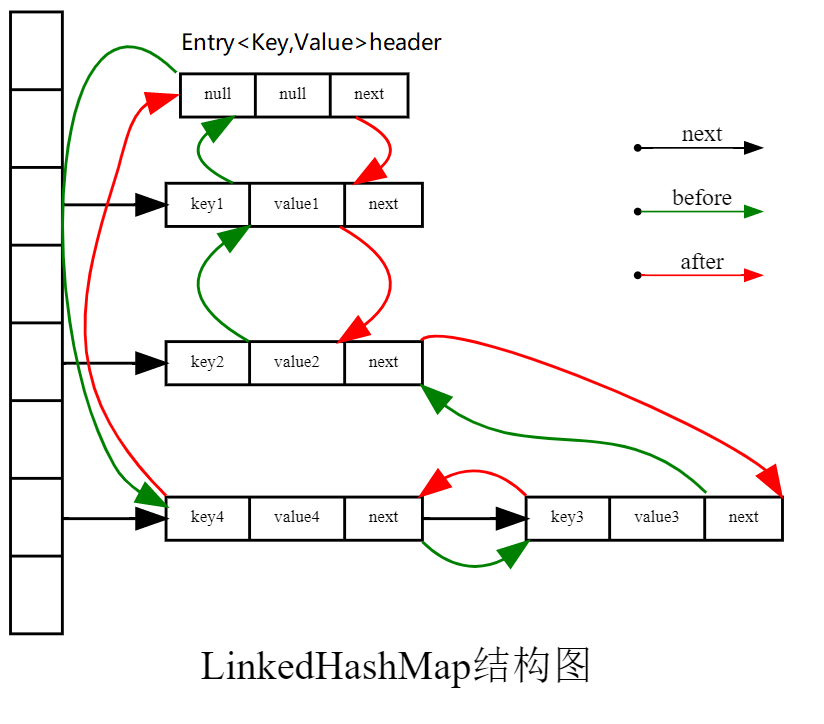
如果忽略图中表示双向链表的红色和绿色线条,其实就是HashMap的存储结构。
源码分析
属性
/**
* 双向链表头
*/
private transient Entry<K,V> header;
/**
* 迭代顺序:
* <tt>true</tt> 访问顺序
* <tt>false</tt> 插入顺序
*/
private final boolean accessOrder;
- header:双向链表头结点
- accessOrder:迭代顺序,
true表示按元素访问顺序;false表示按元素插入顺序
Entry类
private static class Entry<K,V> extends HashMap.Entry<K,V> {
//双向链表
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
}
同时回顾下HashMap的Entry类:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
LinkedHashMap的Entry新增了存储双链表的前驱(before)和后继(after)结点,可见,LinkedHashMap本质上是数组+单链表+双链表的结构。
构造函数
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
和HashMap类似的构造函数,只额外初始化了迭代顺序(默认按元素插入顺序),如果要按元素访问顺序迭代,就必须使用最后一个构造函数。
在HashMap的构造函数中最后调用了init()方法,该方法是子类初始化钩子,LinkedHashMap重写了该方法,用于初始化双链表头。
/**
* HashMap中的子类初始化钩子
*/
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
Put操作
本部分内容需要回忆HashMap的put操作流程,LinkedHashMap只在此基础上覆盖部分方法。
//HashMap put源码
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
addEntry
/**
* 覆盖addEntry,在此基础上删除最久的元素(如果允许)
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
在父类方法上新增删除最老元素的操作,因此可以通过removeEldestEntry实现LRU缓存。
removeEldestEntry
/**
*
* true:删除最久的元素,被 put/putAll方法调用。当用于缓存时,非常有用:删除旧元素控制内存消耗
* 如:
* <pre>
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
* </pre>
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
源码的注释说明的非常清晰,同时还举例实现。后面我们将实现LRU缓存Demo,主要就是重写该方法。
createEntry
/**
* 覆盖crateEntry,添加将新建元素维护到双向链表中
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//新建元素维护到双向链表中
e.addBefore(header);
size++;
}
将新增元素插入到双链表。
addBefore
/**
* 插入前驱节点
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
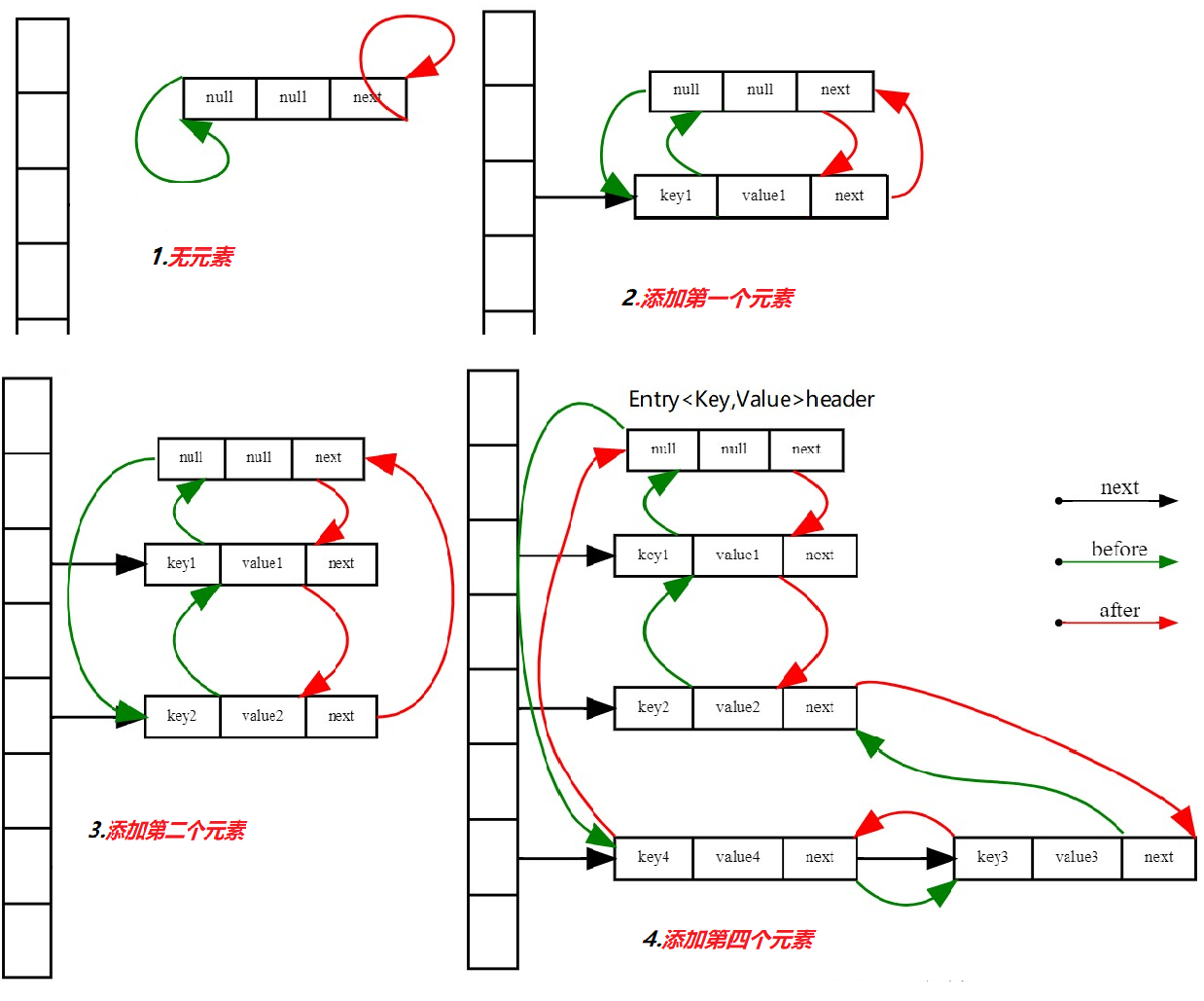
从createEntry方法调用传入header节点看出,新增元素插入到header节点的前一个位置,下面这幅图模拟元素不断插入时,双链表的变化。
扩容
transfer
/**
* 因为性能问题而覆盖
* 遍历双向链表,具有更高的性能
*/
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
//HashMap中transfer源码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
直接遍历双链表提高性能。
Get操作
recordAccess
/**
* Map.get、Map.set调用此方法
* 如果按访问顺序(即:accessOrder为true),则将元素移动到list尾部
* 按插入顺序,则不做任何
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
用于维护按访问顺序(accessOrder为true)情况下,最新访问元素在双链表中的位置,也就是将最新访问的元素移动到双链表header的前一个位置。
该方法有两个调用时机:
- Map.get
- Map.put,当新增元素的
key已经存在时,即新值替换旧值。
LRU示例
public class LRUCache {
public static void main(String[]args){
//缓存容量:4
LRU<String,String> lru = new LRU<>(16,0.75f,4);
lru.put("星期一","1");
lru.put("星期二","2");
lru.put("星期三","3");
lru.put("星期四","4");
lru.put("星期五","5");
for(Map.Entry<String, String> entry : lru.entrySet()){
System.out.println(entry.getKey());
}
}
}
class LRU<K,V> extends LinkedHashMap<K,V>{
//缓存容量
private int cacheSize;
/**
* @param cacheSize 缓存容量
*/
public LRU(int capacity , float loadFactor , int cacheSize){
super(capacity , loadFactor , true);
this.cacheSize = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
//删除超过缓存容量时,删除最老元素
return size() > this.cacheSize;
}
}
缓存容量设置为4,因此"星期一"将被删除。
总结
LinkedHashMap继承自HashMap,具有其全部特性。LinkedHashMap相较于HashMap,通过新增双链表保证元素的按访问顺序访问或按插入顺序访问 两种顺序迭代LinkedHashMap很适合实现LRU缓存LinkedHashMap实现很巧妙,多地方直接实现HashMap中预留的钩子。
