
NLP:14.1 词嵌入(Word2vec)李沐
李沐 动手学深度学习 学习笔记
词向量是⽤于表⽰单词意义的向量,并且还可以被认为是单词的特征向量或表⽰。
将单词映射到实向量的技术称为词嵌⼊。近年来,词嵌⼊逐渐成为⾃然语⾔处理的基础知识。
虽然独热向量很容易构建,但它们通常不是⼀个好的选择。
⼀个主要原因是独热向量不能准确表达不同词之间的相似度,⽐如我们经常使⽤的“余弦相似度”。
14.5.2 GloVe模型
任意两个不同词的独热向量之间的余弦相似度为0,所以独热向量不能编码词之间的相似性。
word2vec⼯具是为了解决上述问题⽽提出的。
它将每个词映射到⼀个固定⻓度的向量,这些向量能更好地表达不同词之间的相似性和类⽐关系。
word2vec⼯具包含两个模型,即跳元模型(skip-gram)[Mikolov et al., 2013b]和连续词袋(CBOW)[Mikolov et al., 2013a]。
对于在语义上有意义的表⽰,它们的训练依赖于条件概率,条件概率可以被看作是使⽤语料库中⼀些词来预测另⼀些单词。
由于是不带标签的数据,因此跳元模型和连续词袋都是⾃监督模型。
14.1.3 跳元模型(Skip-Gram)
跳元模型 假设 ⼀个词 可以⽤来 在 ⽂本序列 中 ⽣成 其 周围的单词。
14.1.4 连续词袋(CBOW)模型
连续词袋(CBOW)模型类似于跳元模型。
与跳元模型的主要区别在于,连续词袋模型 假设 中⼼词 是 基于其 在 ⽂本序列 中 的 周围上下⽂词 ⽣成的。
负采样和分层softmax
14.5 全局向量的词嵌⼊(GloVe)
14.5.1 带全局语料统计的跳元模型
14.5.3 从条件概率⽐值理解GloVe模型
14.6 ⼦词嵌⼊
⼦词嵌⼊可以提⾼稀有词和词典外词的表⽰质量
14.6.1 fastText模型
基于word2vec中的跳元模型,它将中⼼词表⽰为其⼦词向量之和
14.6.2 字节对编码(Byte Pair Encoding)
执⾏训练数据集的统计分析,以发现词内的公共符号。作为⼀种贪⼼⽅法,字节对编码迭代地合并最频繁的连续符号对。
14.8 来⾃Transformers的双向编码器表⽰(BERT)
14.8.1 从上下⽂⽆关到上下⽂敏感
流⾏的上下⽂敏感表⽰包括
- TagLM(language-model augmented sequence tagger,语⾔模型增强的序列标记器)[Peters et al., 2017b]、
- CoVe(Context Vectors,上下⽂向量)[McCann et al., 2017]
- ELMo(Embeddings from Language Models,来⾃语⾔模型的嵌⼊)[Peters et al., 2018]。
14.8.2 从特定于任务到不可知任务
GPT(GenerativePre Training,⽣成式预训练)模型为上下⽂的敏感表⽰设计了通⽤的任务⽆关模型 [Radford et al., 2018]。
由于语⾔模型的⾃回归特性,GPT只能向前看(从左到右)。
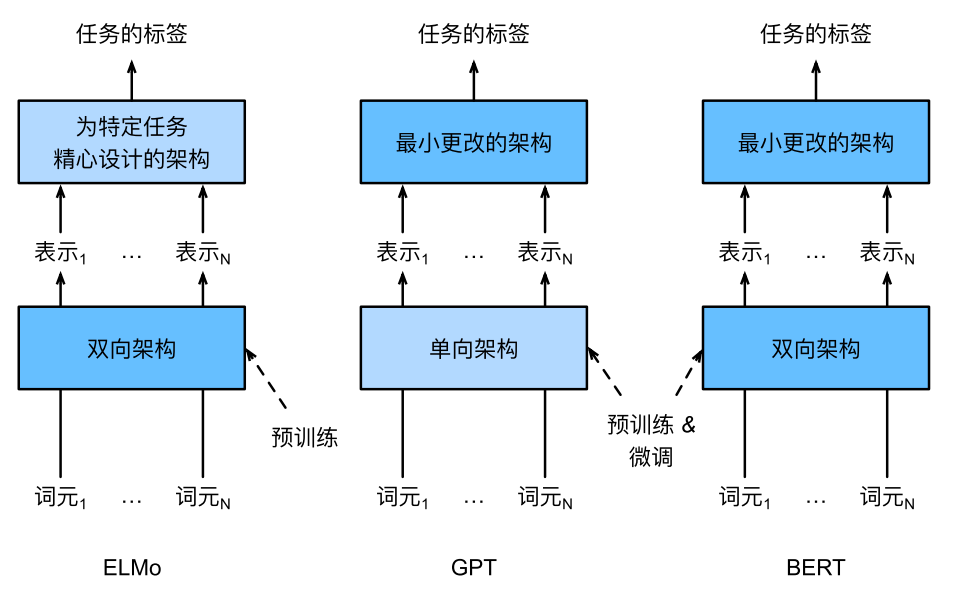
14.8.3 BERT:把两个最好的结合起来
ELMo对上下⽂进⾏双向编码,但使⽤特定于任务的架构;⽽GPT是任务⽆关的,但是从左到右编码上下⽂。
BERT(来⾃Transformers的双向编码器表⽰)结合了这两个⽅⾯的优点。它对上下⽂进⾏双向编码,并且对于⼤多数的⾃然语⾔处理任务 [Devlin et al., 2018]只需要最少的架构改变。
通过使⽤预训练的Transformer编码器,BERT能够基于其双向上下⽂表⽰任何词元。
在下游任务的监督学习过程中,BERT在两个⽅⾯与GPT相似。
⾸先,BERT表⽰将被输⼊到⼀个添加的输出层中,根据任务的性质对模型架构进⾏最⼩的更改,例如预测每个词元与预测整个序列。
其次,对预训练Transformer编码器的所有参数进⾏微调,⽽额外的输出层将从头开始训练。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律