Transformer 必备知识点
NNDL 学习笔记
transformer:基于多头自注意力的序列到序列的模型
- 前馈神经网络
- 全连接
- ResNet残差连接
- 层归一化
- Softmax
- 编码器-解码器
- 掩蔽自注意力:通过一个掩码(Mask)来阻止每个位置选择其后面的输入信息。掩蔽自注意力 - HBU_DAVID - 博客园 (cnblogs.com)
- 词嵌入:单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
- 位置编码:正余弦编码
10.6. 自注意力和位置编码 — 动手学深度学习 2.0.0 documentation (d2l.ai)
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
Transformer学习笔记一:Positional Encoding(位置编码) - 知乎 (zhihu.com)
一文读懂Transformer模型的位置编码 - 知乎 (zhihu.com)
Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
Transformer结构图比较唬人,那么多个小方块,那么多条连接线。其实拆开了看,就轻松了~
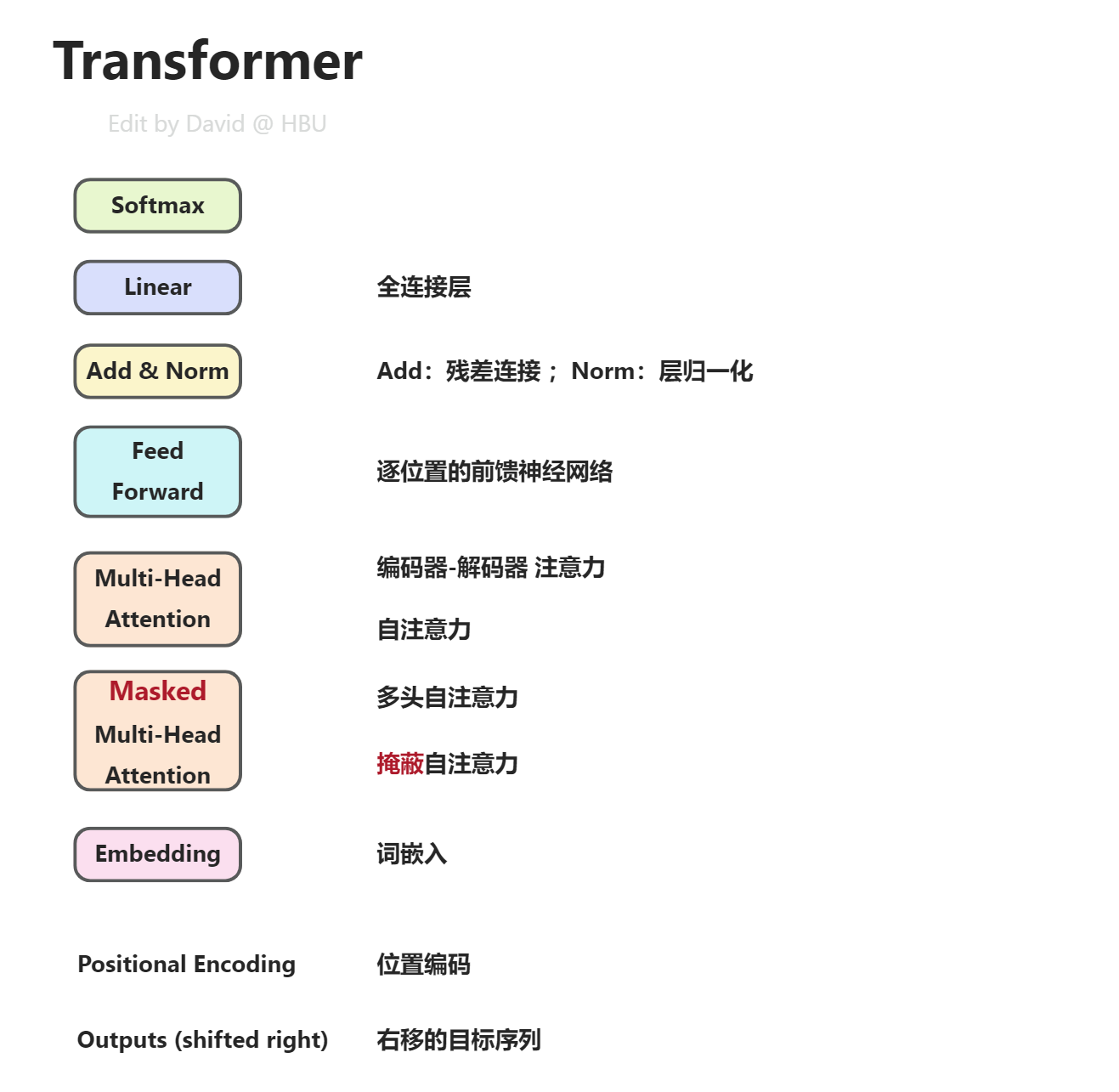
把每个小模块都研究明白了,组装起来,跟搭积木一样。
注意虚线框外面的N×,表明循环使用N次。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号