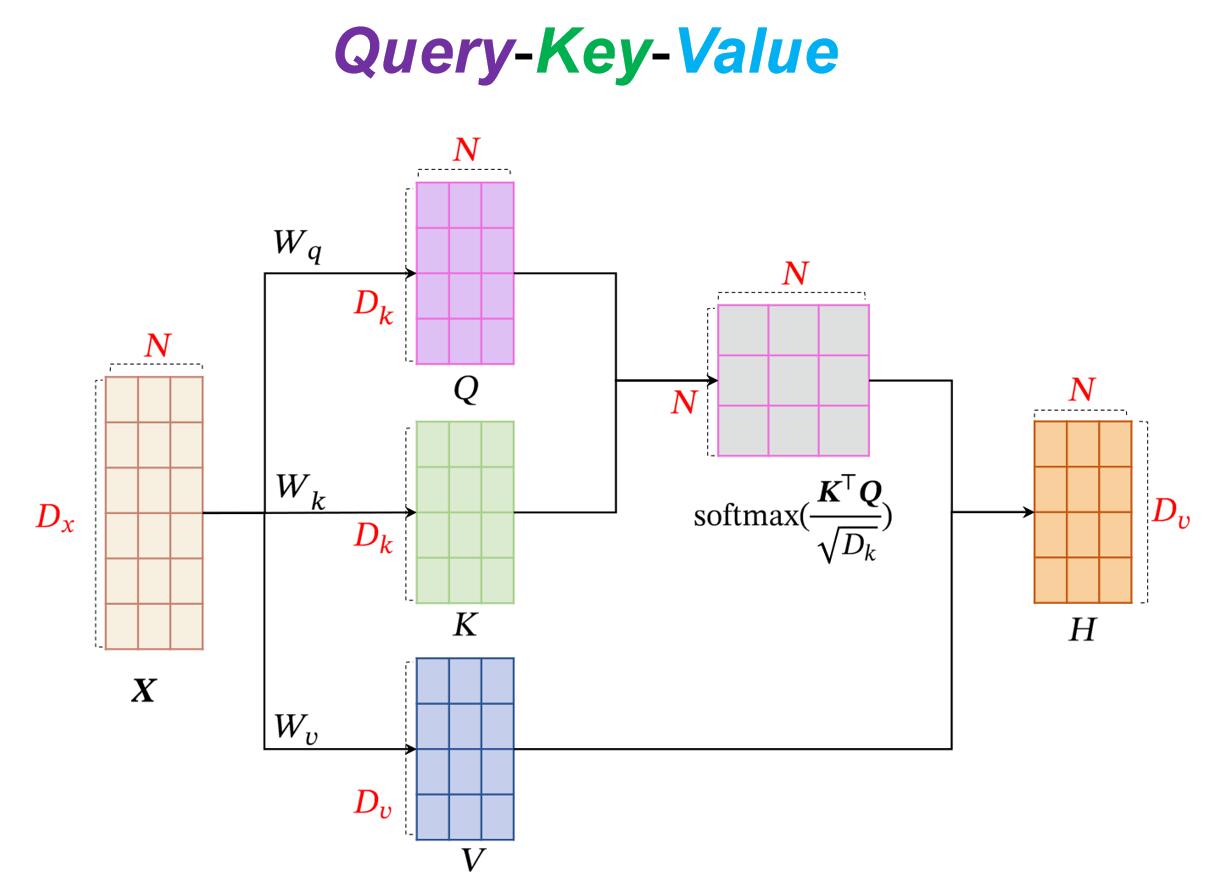
Self-Attention:Learning QKV step by step
邱锡鹏 NNDL 学习笔记
学习自注意力模型不难,研究透彻还是需要花点功夫。
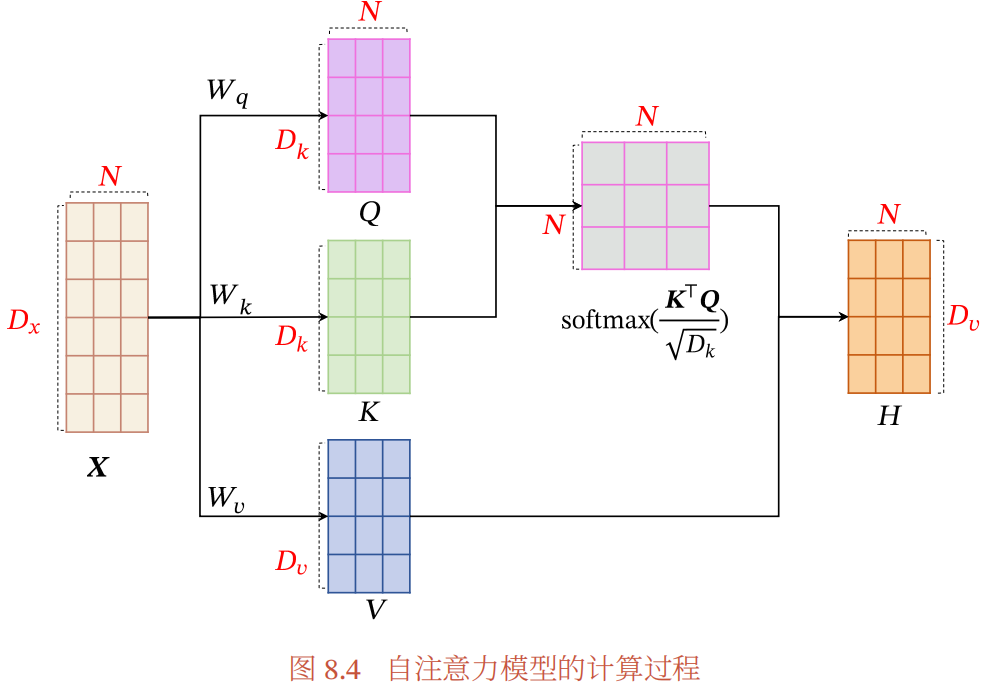
这张图赏心悦目,看上去并不复杂,但其中的细节还需慢慢体会。
1. 为了提高模型能力,自注意力模型经常采用查询-键-值(Query-Key-Value,QKV)模式.
怎么就提高模型能力了呢?为什么用QKV就能提高?
NNDL配套实验书,讲解了“简单自注意力模型”,先体会最简单的模型有助于对“自注意力”这个“自”的理解。
键值对注意力 VS. 自注意力,会发现公式中的不同之处:QKV变成了XXX。(注意:此处的QKV,KV来自Key Value Pair注意力,Q来自外部。不是自注意力的Query-Key-Value,QKV均来自内部。)
一切都源于自身,所以是:Self注意力。
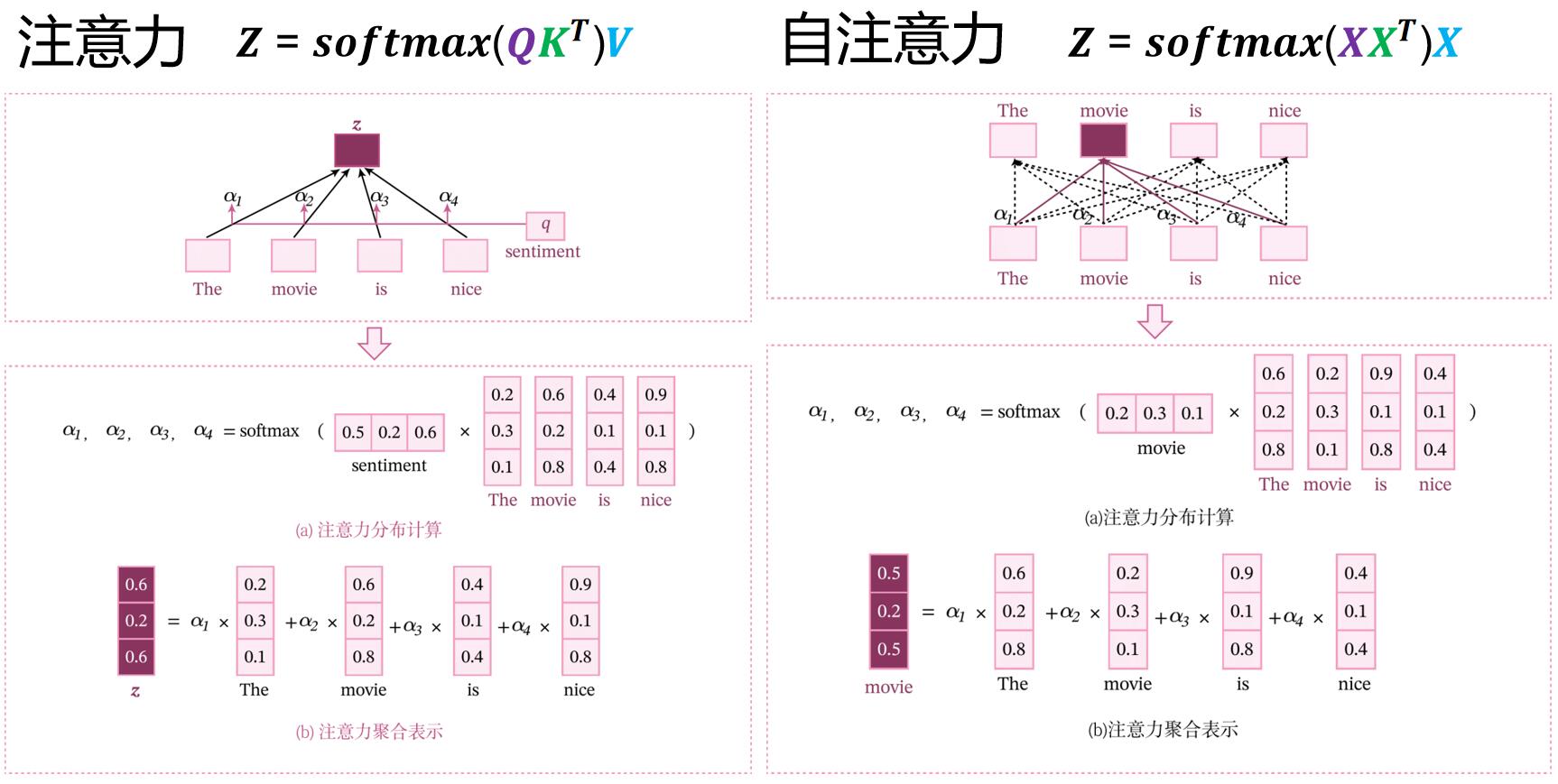
简单自注意力模型 不带参数,模型能力有限。
“查询-键-值”模式 带参数,提高了模型能力。自注意力模型常用QKV方式 。
这就说到了本质:QKV是带参数的,所以能力提高了。
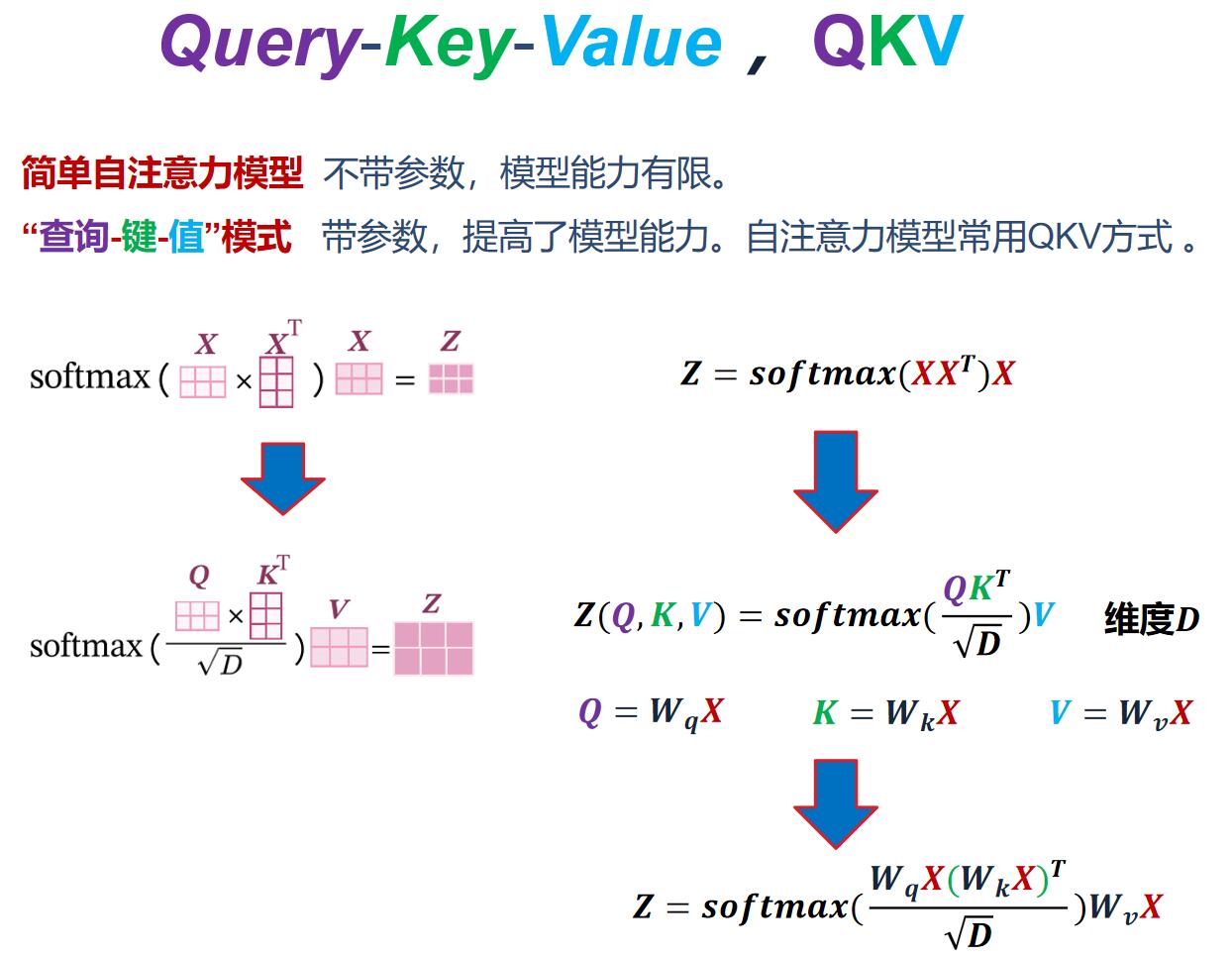
放在一起仔细端详~ 发现其中奥妙:
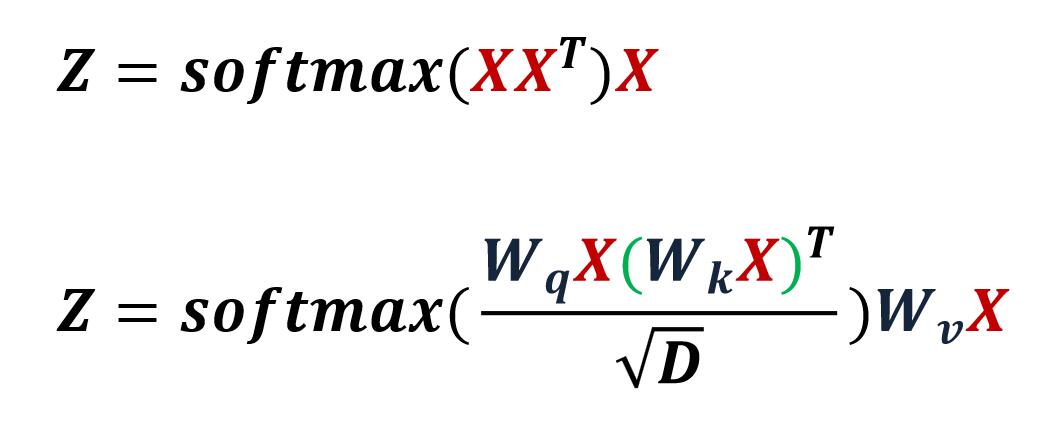
2. X线性映射到三个不同的空间QKV
把图拆开了看更方便。就是最简单的线性变换,没有难度。注意一下维度。QK维度相等,why? V的维度可以不一样?
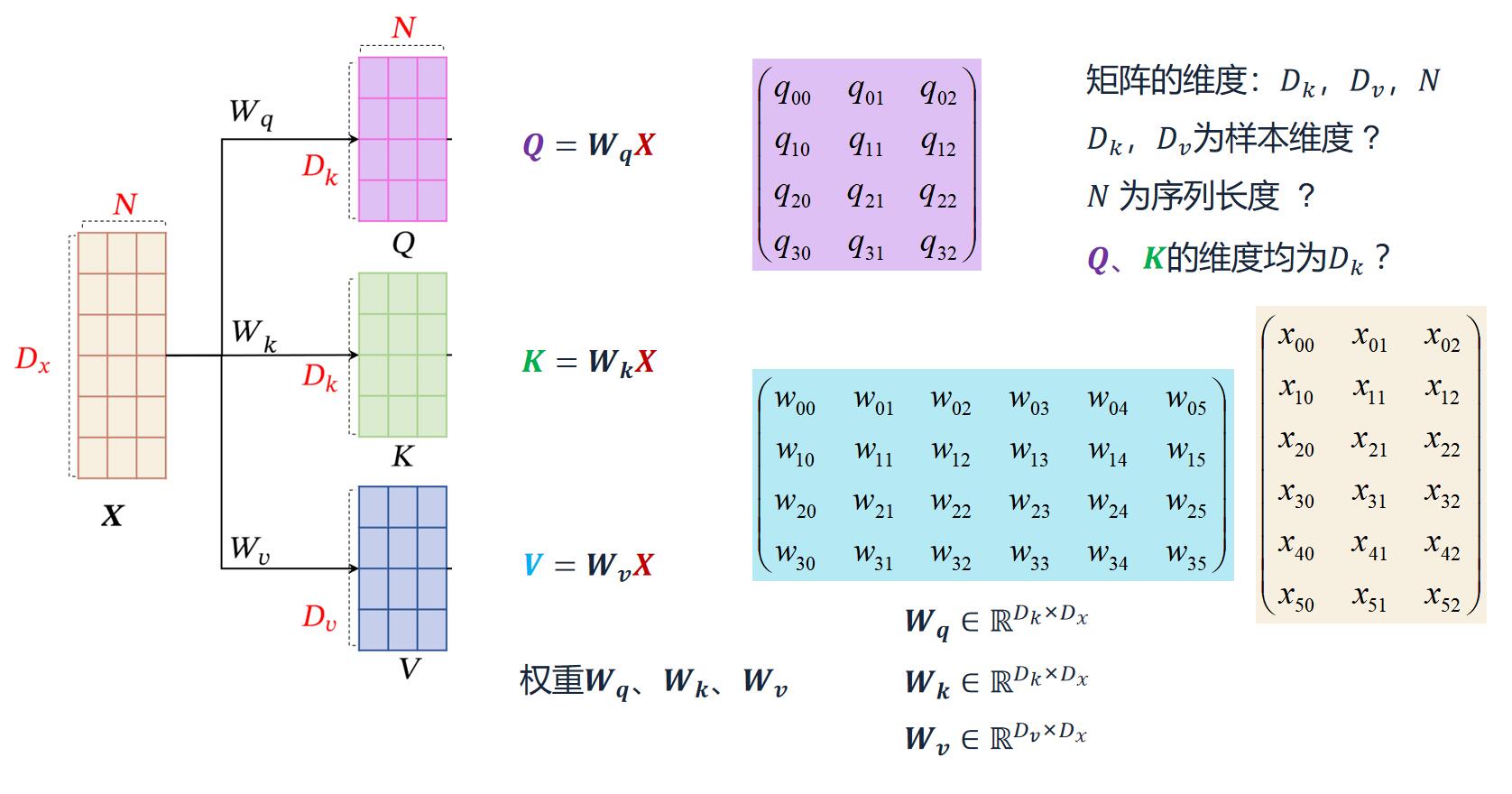
3. 键值对注意力 VS. QKV
除了QKV的来源不一样,其他都一样。所以,如果前面的注意力机制学的没问题,这里的自注意力也不难。
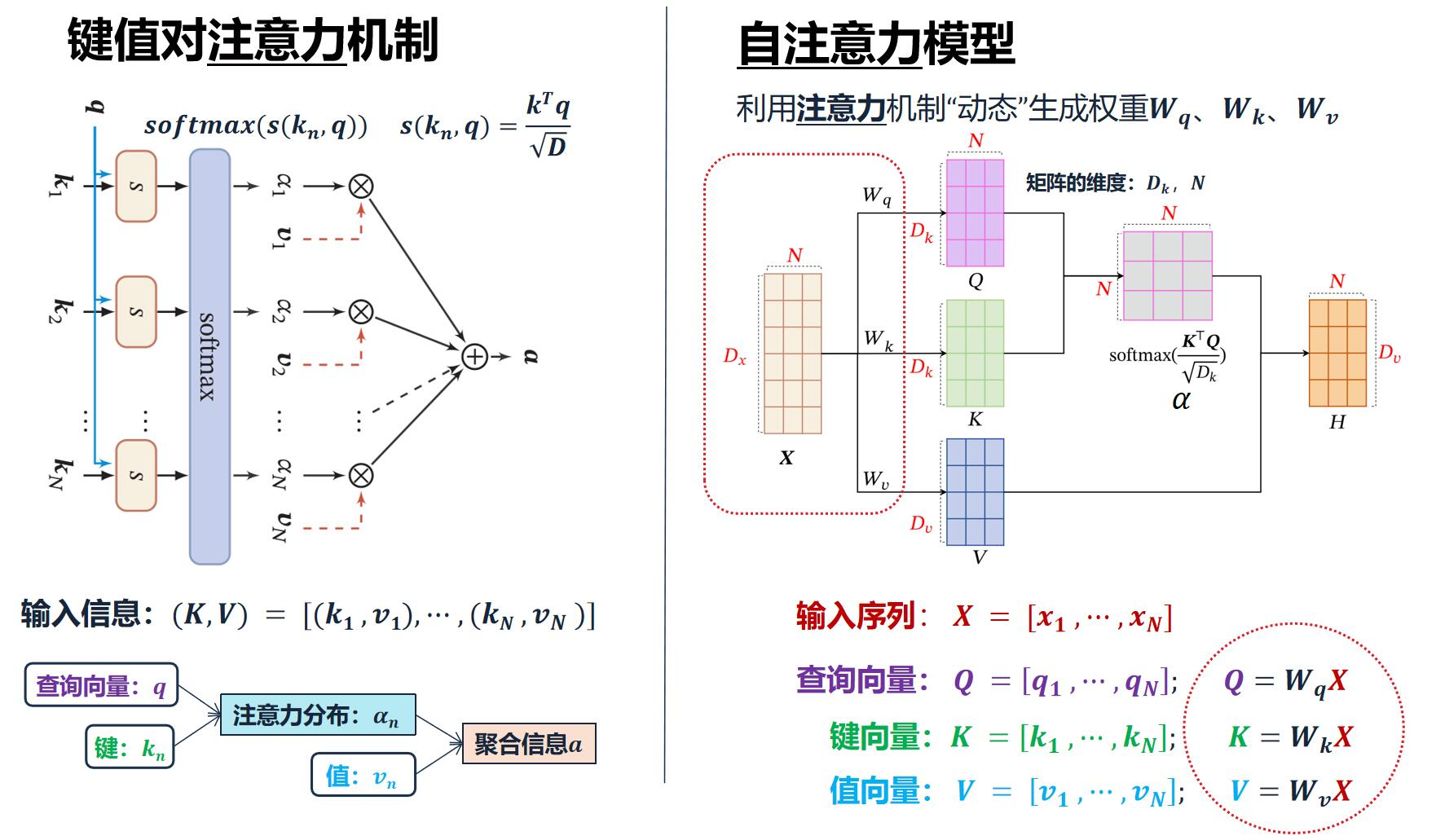
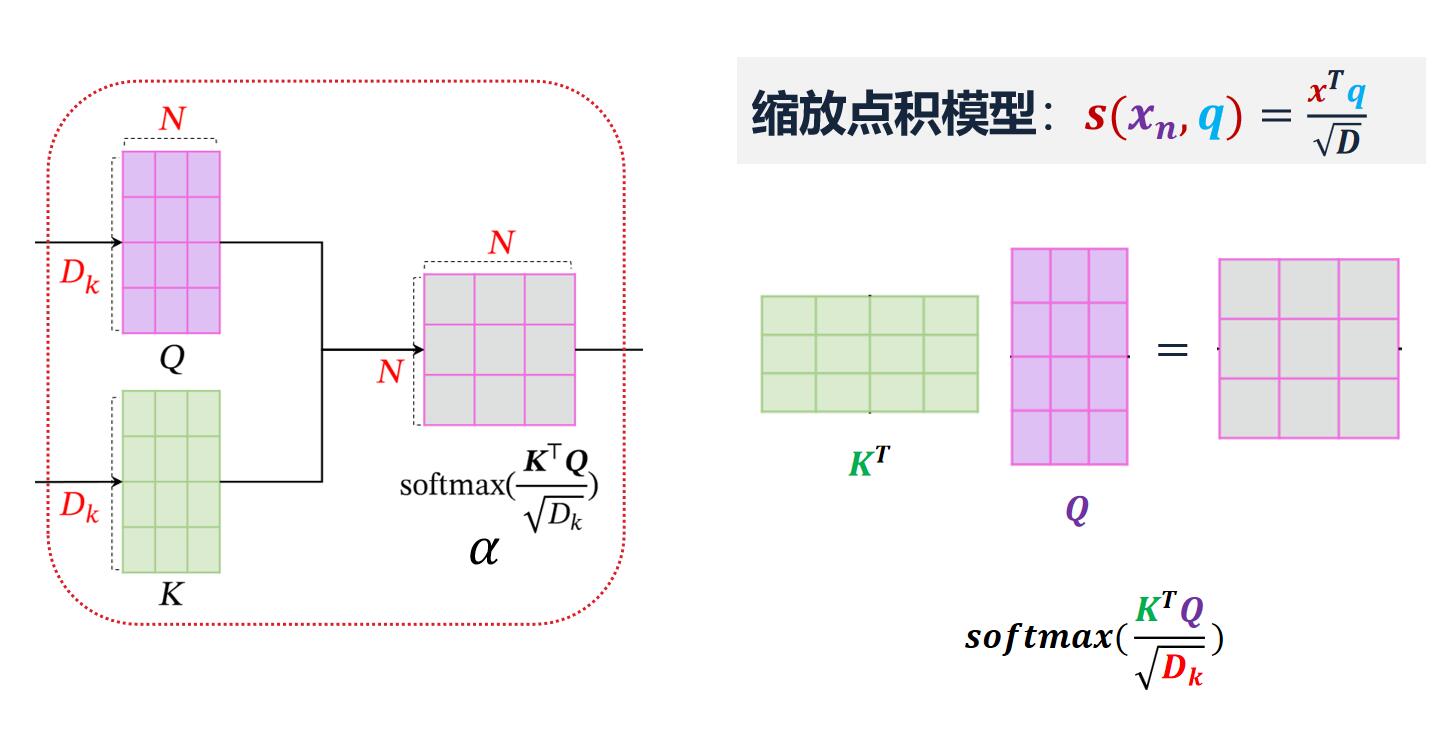
4. QKV缩放点积模型的使用
计算注意力模型分布,并softmax归一化
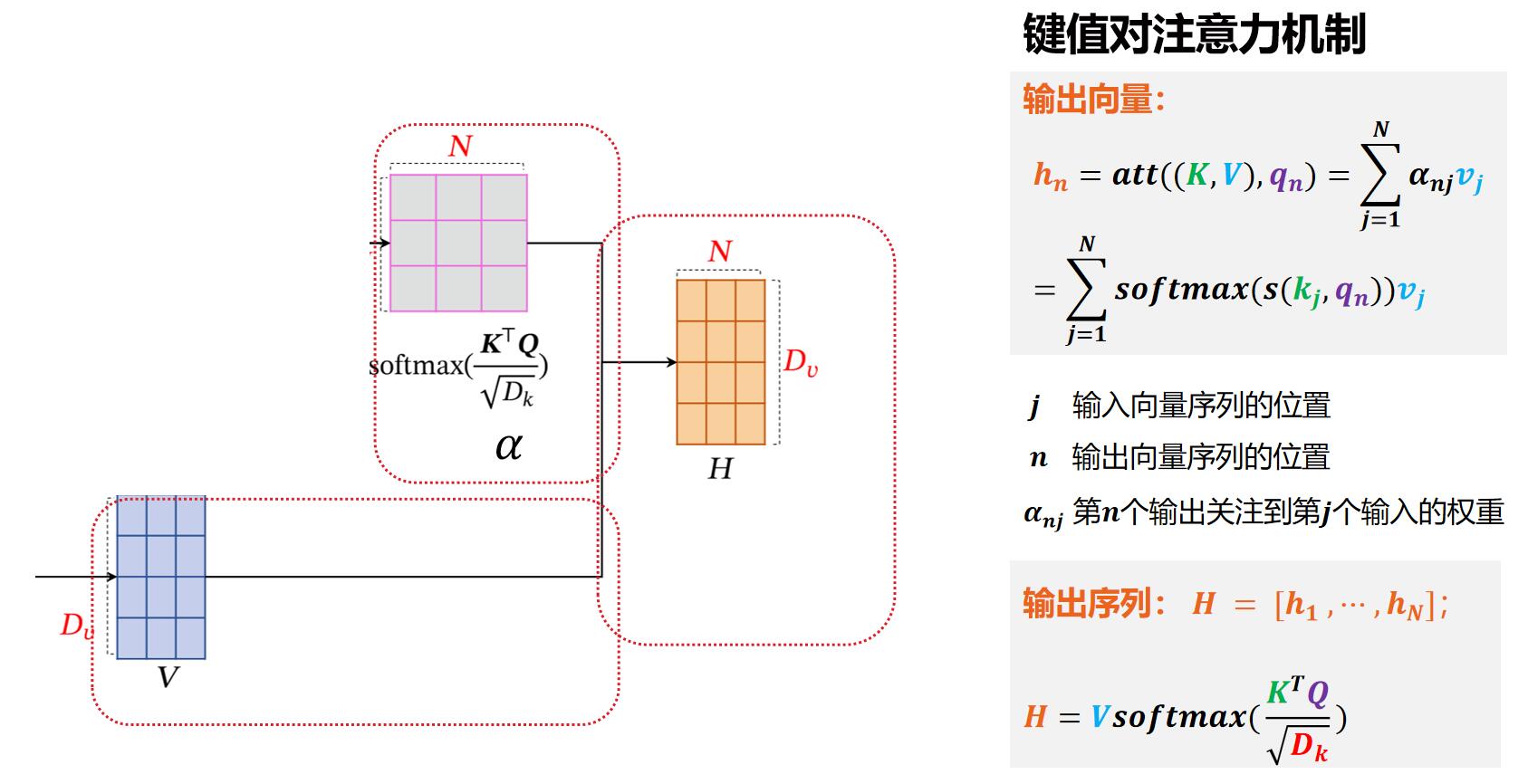
5. 键值对注意力模式聚合
根据求得的分布α,结合V,计算加权平均,得到输出向量H。这里采用的方式是键值对注意力模式。
6. 合在一起。再看此图,就觉得很清晰了
这时候,不只是觉得图片好看,脉络也清清楚楚了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号