Self-Attention 实例 pytorch
BERT模型入门系列(三):Self-Attention详解 - 知乎 (zhihu.com)
读了不少书,看了不少视频,感觉这片文章最适合入门。
简洁清晰,例子好懂。
为什么需要self-attention模型?1、训练速度受限 2、处理长文本能力弱
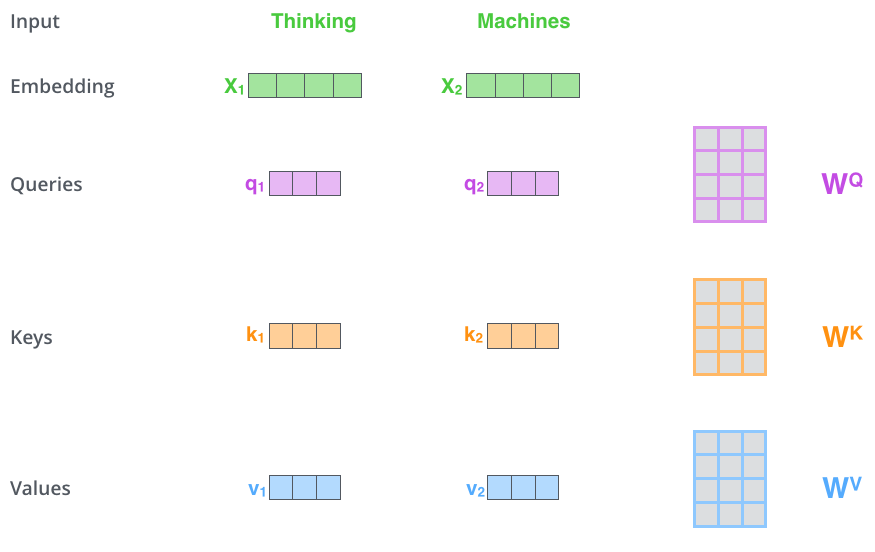

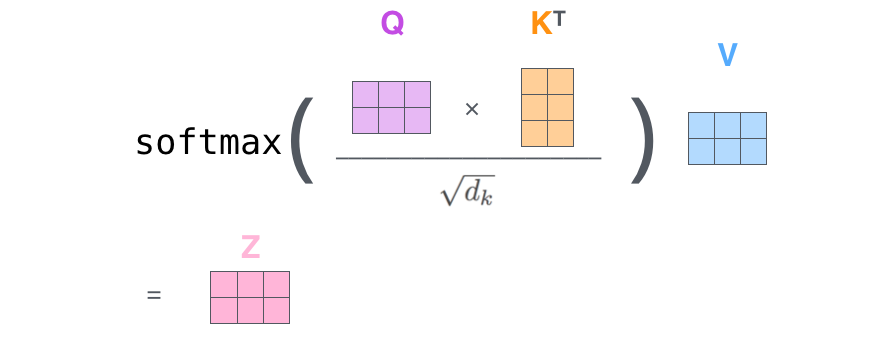
计算过程
1、计算Q(查询向量Quey)、K(键向量)、Value(值向量)
2、计算注意力权重,这里使用点积来作为注意力打分函数
3、计算输出向量序列

详细步骤请参考原文:BERT模型入门系列(三):Self-Attention详解 - 知乎 (zhihu.com)
原文程序貌似TensorFlow写的,这里用pytorch写一下。
import torch
import numpy as np
import torch.nn as nn
import math
import torch.nn.functional as F
# https://blog.csdn.net/weixin_53598445/article/details/125009686
# https://zhuanlan.zhihu.com/p/345280272
class selfAttention(nn.Module):
def __init__(self, input_size, hidden_size):
super(selfAttention, self).__init__()
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
def forward(self, x, w_k, w_q, w_v):
self.key_layer.weight.data = w_k.mT # 初始化key参数,可以直接学习
self.key_layer.bias.data = torch.Tensor([0.0])
key = self.key_layer(x)
self.query_layer.weight.data = w_q.mT
self.query_layer.bias.data = torch.Tensor([0.0])
query = self.query_layer(x)
self.value_layer.weight.data = w_v.mT
self.value_layer.bias.data = torch.Tensor([0.0])
value = self.value_layer(x)
print('key:\n', key)
print('query:\n', query)
print('value:\n', value)
attention_scores = torch.matmul(query, key.mT) # query * (key的转置)
print('query * (key的转置):\n', attention_scores)
attention_softmax = F.softmax(attention_scores, dim=-1) # dim=n参数用来指定第n个维度的和为1
torch.set_printoptions(precision=2, sci_mode=False) # 显示小数点后的位数
print('注意力权重:\n', attention_softmax)
h1 = value[0][0] * attention_softmax[0][0][0] \
+ value[0][1] * attention_softmax[0][0][1] \
+ value[0][2] * attention_softmax[0][0][2]
h2 = value[0][0] * attention_softmax[0][1][0] \
+ value[0][1] * attention_softmax[0][1][1] \
+ value[0][2] * attention_softmax[0][1][2]
h3 = value[0][0] * attention_softmax[0][2][0] \
+ value[0][1] * attention_softmax[0][2][1] \
+ value[0][2] * attention_softmax[0][2][2]
print('输出向量序列:')
print(h1)
print(h2)
print(h3)
return 0
features = torch.tensor([[[1, 0, 1, 0],
[0, 2, 0, 2],
[1, 1, 1, 1]]], dtype=torch.float)
wk = torch.tensor([[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]], dtype=torch.float)
wq = torch.tensor([[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]], dtype=torch.float)
wv = torch.tensor([[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]], dtype=torch.float)
attention = selfAttention(4, 3)
attention.forward(features, wk, wq, wv)运行结果,与图片计算基本一致(精度不同,略有差异)
key:
tensor([[[0., 1., 1.],
[4., 4., 0.],
[2., 3., 1.]]], grad_fn=<AddBackward0>)
query:
tensor([[[1., 0., 2.],
[2., 2., 2.],
[2., 1., 3.]]], grad_fn=<AddBackward0>)
value:
tensor([[[1., 2., 3.],
[2., 8., 0.],
[2., 6., 3.]]], grad_fn=<AddBackward0>)
query * (key的转置):
tensor([[[ 2., 4., 4.],
[ 4., 16., 12.],
[ 4., 12., 10.]]], grad_fn=<UnsafeViewBackward0>)
注意力权重:
tensor([[[ 0.06, 0.47, 0.47],
[ 0.00, 0.98, 0.02],
[ 0.00, 0.88, 0.12]]], grad_fn=<SoftmaxBackward0>)
输出向量序列:
tensor([1.94, 6.68, 1.60], grad_fn=<AddBackward0>)
tensor([2.00, 7.96, 0.05], grad_fn=<AddBackward0>)
tensor([2.00, 7.76, 0.36], grad_fn=<AddBackward0>)
不初始化,通过学习得到wq,wk,wv,源代码如下:
import torch
import numpy as np
import torch.nn as nn
import math
import torch.nn.functional as F
# https://blog.csdn.net/weixin_53598445/article/details/125009686
# https://zhuanlan.zhihu.com/p/345280272
class selfAttention(nn.Module):
def __init__(self, input_size, hidden_size):
super(selfAttention, self).__init__()
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
def forward(self, x):
key = self.key_layer(x)
query = self.query_layer(x)
value = self.value_layer(x)
print('key:\n', key)
print('query:\n', query)
print('value:\n', value)
attention_scores = torch.matmul(query, key.mT) # query * (key的转置)
print('query * (key的转置):\n', attention_scores)
attention_softmax = F.softmax(attention_scores, dim=-1) # dim=n参数用来指定第n个维度的和为1
torch.set_printoptions(precision=2, sci_mode=False) # 显示小数点后的位数
print('注意力权重:\n', attention_softmax)
h1 = value[0][0] * attention_softmax[0][0][0] \
+ value[0][1] * attention_softmax[0][0][1] \
+ value[0][2] * attention_softmax[0][0][2]
h2 = value[0][0] * attention_softmax[0][1][0] \
+ value[0][1] * attention_softmax[0][1][1] \
+ value[0][2] * attention_softmax[0][1][2]
h3 = value[0][0] * attention_softmax[0][2][0] \
+ value[0][1] * attention_softmax[0][2][1] \
+ value[0][2] * attention_softmax[0][2][2]
print('输出向量序列:')
print(h1)
print(h2)
print(h3)
return 0
features = torch.tensor([[[1, 0, 1, 0],
[0, 2, 0, 2],
[1, 1, 1, 1]]], dtype=torch.float)
attention = selfAttention(4, 3)
attention.forward(features)输出结果:
key:
tensor([[[ 0.0680, 0.2645, 0.0556],
[-1.2327, -0.1178, 0.3482],
[-0.6597, 0.1382, 0.1653]]], grad_fn=<AddBackward0>)
query:
tensor([[[-0.0121, -0.0466, -0.2353],
[-0.2424, 0.3289, -0.2127],
[-0.1471, 0.0114, -0.2089]]], grad_fn=<AddBackward0>)
value:
tensor([[[-0.3317, -0.3424, -0.6434],
[ 0.4560, 1.2522, -1.7553],
[-0.0401, 0.1366, -1.2749]]], grad_fn=<AddBackward0>)
query * (key的转置):
tensor([[[-0.0262, -0.0615, -0.0373],
[ 0.0587, 0.1860, 0.1702],
[-0.0186, 0.1072, 0.0641]]], grad_fn=<UnsafeViewBackward0>)
注意力权重:
tensor([[[0.34, 0.33, 0.33],
[0.31, 0.35, 0.34],
[0.31, 0.35, 0.34]]], grad_fn=<SoftmaxBackward0>)
输出向量序列:
tensor([ 0.02, 0.34, -1.22], grad_fn=<AddBackward0>)
tensor([ 0.04, 0.38, -1.25], grad_fn=<AddBackward0>)
tensor([ 0.04, 0.38, -1.25], grad_fn=<AddBackward0>)
进程已结束,退出代码0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号