扩展学习: 中文分词;词云制作
中文分词工具有很多,这里选择使用jieba jieba · PyPI
wordcloud安装时候需要注意版本号 pip安装wordcloud出错 ERROR: Command errored out with exit status 1:_密言的博客-CSDN博客_pip安装wordcloud 出错
词云代码 词云可视化:四行Python代码轻松上手到精通_同济 子豪兄的博客-CSDN博客_python词云代码
1. 中文分词
import jieba
seg_list = jieba.cut("我在河北大学上学,My name is Tom", cut_all=True)# 全模式
print("Full Mode: " + "/ ".join(seg_list))
seg_list = jieba.cut("我在河北大学上学,My name is Tom", cut_all=False) # 精确模式(默认是精确模式)
print("Default Mode: " + "/ ".join(seg_list))
2. 词云
简易版
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
w = wordcloud.WordCloud()
w.generate('and that government of the people, by the people, for the people, shall not perish from the earth.')
w.to_file('output1.png')
img = Image.open("output1.png")
m = np.asarray(img)
plt.imshow(m)
plt.show()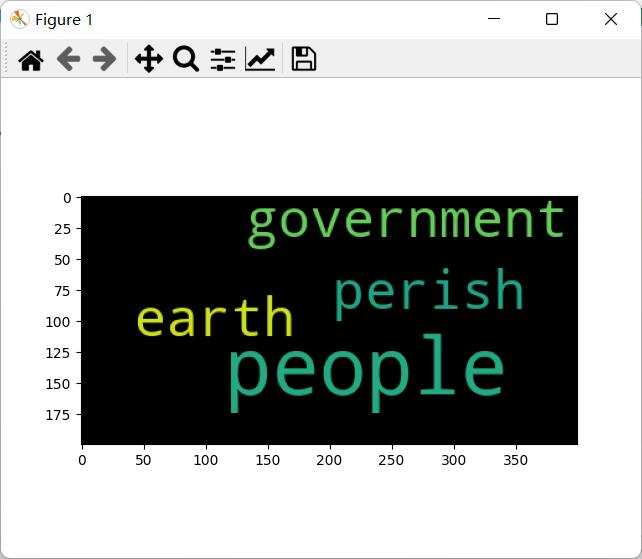
升级版
import wordcloud
import jieba
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import imageio
mk = imageio.imread("chinamap.png")
# 构建并配置词云对象w,注意要加stopwords集合参数,将不想展示在词云中的词放在stopwords集合里,这里去掉“曹操”和“孔明”两个词
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path='msyh.ttc',
mask=mk,
scale=5,
stopwords={'曹操','孔明'})
# 对来自外部文件的文本进行中文分词,得到string
f = open('三国演义.txt',encoding='utf-8')
txt = f.read()
txtlist = jieba.lcut(txt)
string = " ".join(txtlist)
# 将string变量传入w的generate()方法,给词云输入文字
w.generate(string)
# 将词云图片导出到当前文件夹
w.to_file('output8-threekingdoms.png')
img=Image.open("output8-threekingdoms.png")
m=np.asarray(img)
plt.imshow(m)
plt.show()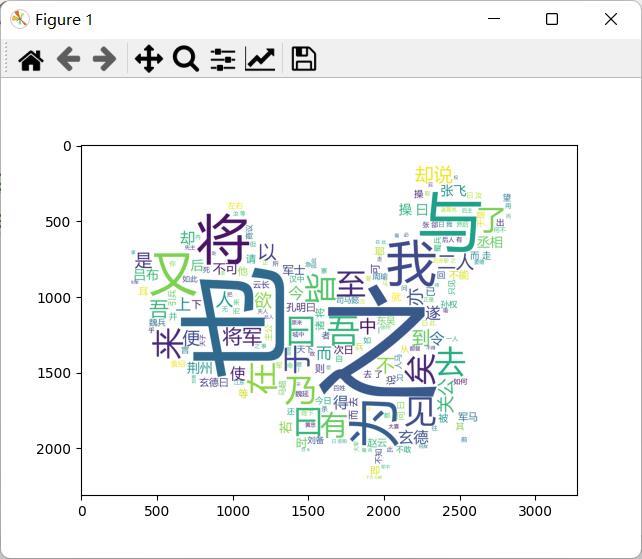

 浙公网安备 33010602011771号
浙公网安备 33010602011771号