
【动手学深度学习pytorch】学习笔记 8.2 文本预处理
8.2. 文本预处理 — 动手学深度学习 2.0.0-beta0 documentation (d2l.ai)
1. 改写为读本地文件
2. 增加更多输出项,研究内部结构
编程环境:pycharm,python 3.9
将文本作为字符串加载到内存中。
-
将字符串拆分为词元(如单词和字符)。
-
建立一个词表,将拆分的词元映射到数字索引。
-
将文本转换为数字索引序列,方便模型操作。
1. 将字符串拆分为词元(如单词和字符)
词元(token)是文本的基本单位
直接处理文本是无法操作的。首先把文本拆为词元。也就是拆成一个个单词,或者拆的更碎,直接拆成字母。中文一般是用分词工具,拆成一个个词语,或者更碎,拆成一个个文字。
import re
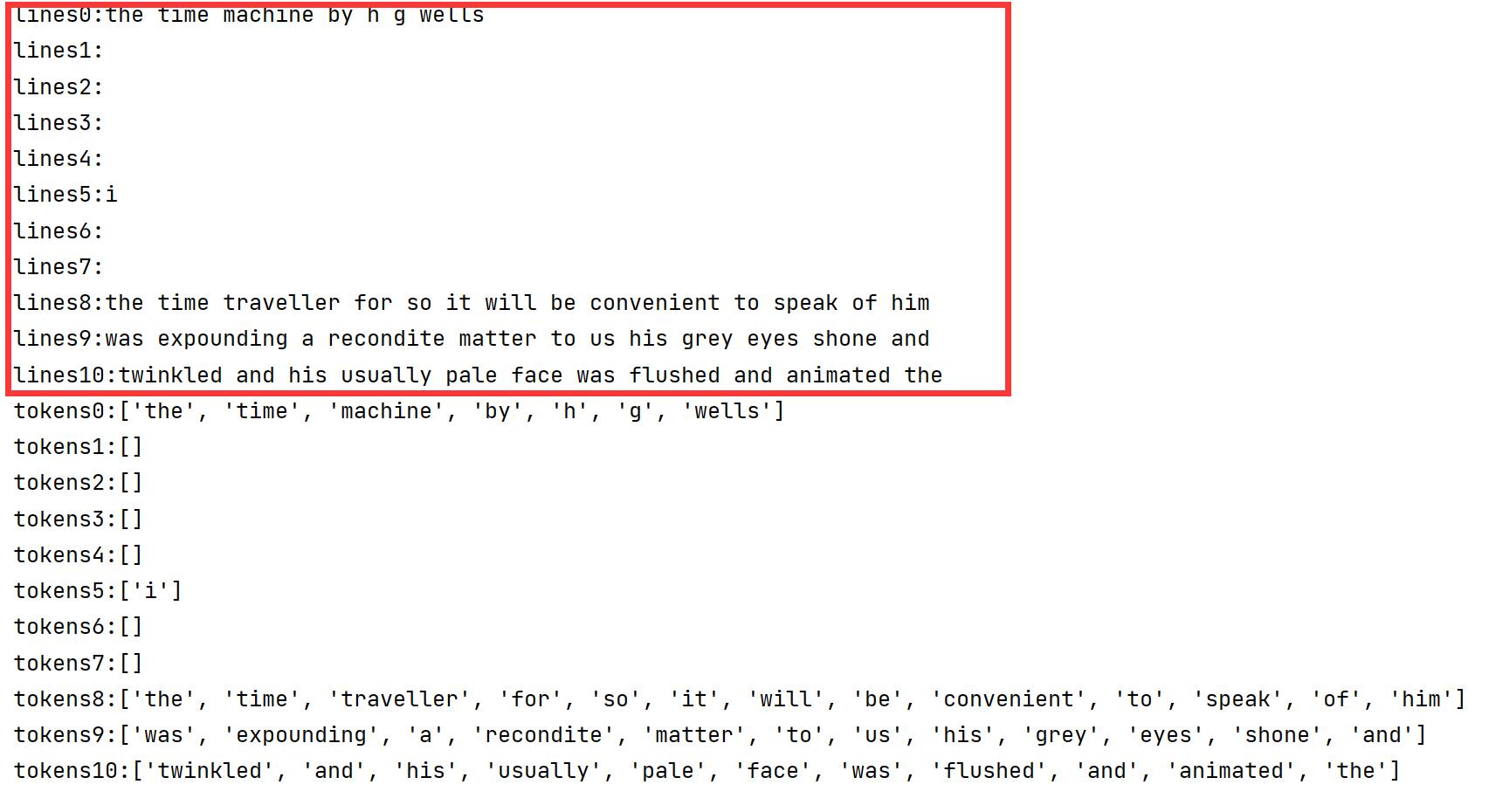
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open('../timemachine.txt', 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
for i in range(11):
print(f'lines{i}:{lines[i]}')
def tokenize(lines, token='word'):
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
for i in range(11):
print(f'tokens{i}:{tokens[i]}')运行结果,文本拆成了一个个单词。
2. 建立词表,将拆分的词元映射到数字索引
训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。
根据每个唯一词元的出现频率,为其分配一个数字索引。
构建字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从0开始的数字索引中。
import collections
import re
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open('../timemachine.txt', 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
lines = read_time_machine()
def tokenize(lines, token='word'):
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
class Vocab:
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens):
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
print(vocab.token_freqs[:10])
for i in [0, 10, 15]:
print('文本(词元):', i, tokens[i])
print('索引(词表):', i, vocab[tokens[i]])运行结果, 词表的 索引、词频、单词与词频的对照

3. 整合在一起使用
第1步的例子是单词词元,这里用的字符词元。
import collections
import re
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open('../timemachine.txt', 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
def tokenize(lines, token='word'):
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
class Vocab:
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens):
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
def load_corpus_time_machine(max_tokens=-1):
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine()
tokens = tokenize(lines, 'char') # 使用字符(而不是单词)实现文本词元化
for i in [0, 10, 15]:
print(f'tokens{i}:{tokens[i]}')
vocab = Vocab(tokens)
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line] # 语料(corpus)
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
print('len(corpus), len(vocab):', len(corpus), len(vocab))
lines = read_time_machine()
print(f'lines{0}:{lines[0]}')
print('index of char:', corpus[:10])
print('vocab index:', list(vocab.token_to_idx.items()))
print('vocab freqs:', vocab.token_freqs)运行结果
- 观察词元:是一个个字符,
- 观察对应关系:一个个字符,映射成了一个个数字(数字是词表中的索引号),
- 观察词表:28个字符的索引,28个字符的词频

分类:
Deep Learning


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2017-06-09 名词解释: Wi-Fi