设计基函数(basis function) 以及数据读取
import numpy as np
import matplotlib.pyplot as plt
def identity_basis(x):
ret = np.expand_dims(x, axis=1)
return ret
def multinomial_basis(x, feature_num=10):
x = np.expand_dims(x, axis=1) # shape(N, 1)
feat = [x]
for i in range(2, feature_num+1):
feat.append(x**i)
ret = np.concatenate(feat, axis=1)
return ret
def gaussian_basis(x, feature_num=10):
centers = np.linspace(0, 25, feature_num)
width = 1.0 * (centers[1] - centers[0])
x = np.expand_dims(x, axis=1)
x = np.concatenate([x]*feature_num, axis=1)
out = (x-centers)/width
ret = np.exp(-0.5 * out ** 2)
return ret
# basis_func 三选一:identity_basis; multinomial_basis; gaussian_basis
def load_data(filename, basis_func=gaussian_basis):
"""载入数据。"""
xys = []
with open(filename, 'r') as f:
for line in f:
xys.append(map(float, line.strip().split()))
xs, ys = zip(*xys)
xs, ys = np.asarray(xs), np.asarray(ys)
o_x, o_y = xs, ys
phi0 = np.expand_dims(np.ones_like(xs), axis=1)
phi1 = basis_func(xs)
xs = np.concatenate([phi0, phi1], axis=1)
return (np.float32(xs), np.float32(ys)), (o_x, o_y)
定义模型
import tensorflow as tf
from tensorflow.keras import optimizers, layers, Model
print(tf.__version__) # 输出TensorFlow版本
class linearModel(Model):
def __init__(self, ndim):
super(linearModel, self).__init__()
self.w = tf.Variable(
shape=[ndim, 1],
initial_value=tf.random.uniform([ndim,1], minval=-0.1, maxval=0.1, dtype=tf.float32))
@tf.function
def call(self, x):
y = tf.squeeze(tf.matmul(x, self.w), axis=1)
return y
(xs, ys), (o_x, o_y) = load_data('train.txt')
ndim = xs.shape[1]
model = linearModel(ndim=ndim)
2.9.1
训练以及评估
optimizer = optimizers.Adam(0.1)
@tf.function
def train_one_step(model, xs, ys):
with tf.GradientTape() as tape:
y_preds = model(xs)
loss = tf.reduce_mean(tf.sqrt(1e-12+(ys-y_preds)**2))
grads = tape.gradient(loss, model.w)
optimizer.apply_gradients([(grads, model.w)])
return loss
@tf.function
def predict(model, xs):
y_preds = model(xs)
return y_preds
def evaluate(ys, ys_pred):
"""评估模型。"""
std = np.sqrt(np.mean(np.abs(ys - ys_pred) ** 2))
return std
for i in range(1000):
loss = train_one_step(model, xs, ys)
if i % 100 == 1:
print(f'loss = {loss:.4}')
y_preds = predict(model, xs)
std = evaluate(ys, y_preds)
print('训练集预测值与真实值的标准差:{:.1f}'.format(std))
(xs_test, ys_test), (o_x_test, o_y_test) = load_data('test.txt')
y_test_preds = predict(model, xs_test)
std = evaluate(ys_test, y_test_preds)
print('训练集预测值与真实值的标准差:{:.1f}'.format(std))
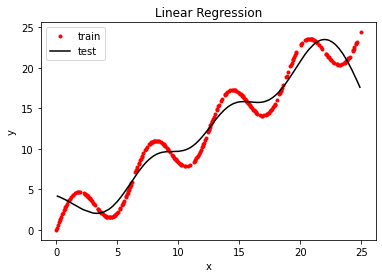
plt.plot(o_x, o_y, 'ro', markersize=3)
plt.plot(o_x_test, y_test_preds, 'k')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Linear Regression')
plt.legend(['train', 'test', 'pred'])
plt.show()
loss = 11.71
loss = 1.656
loss = 1.609
loss = 1.573
loss = 1.535
loss = 1.497
loss = 1.456
loss = 1.414
loss = 1.369
loss = 1.323
训练集预测值与真实值的标准差:1.5
训练集预测值与真实值的标准差:1.8
ref:https://www.cnblogs.com/douzujun/p/13282073.html


