神经网络与深度学习(邱锡鹏)编程练习 2 实验5 使用pytorch实现线性回归、基函数回归
# 定义模型
class LR(nn.Module):
def __init__(self):
super().__init__()
self.lr = nn.Linear(ndim, 1)
def forward(self, x):
out = self.lr(x)
return out
model = LR() # 构建模型对象
criterion = torch.nn.MSELoss() # 构建损失函数对象
optimizer = torch.optim.SGD(model.parameters(), 0.001) # 构建优化器函数对象,学习率0.001实验结论:
- 线性回归效果良好
- 多项式基函数梯度爆炸,没有结果
- 高斯基函数效果良好
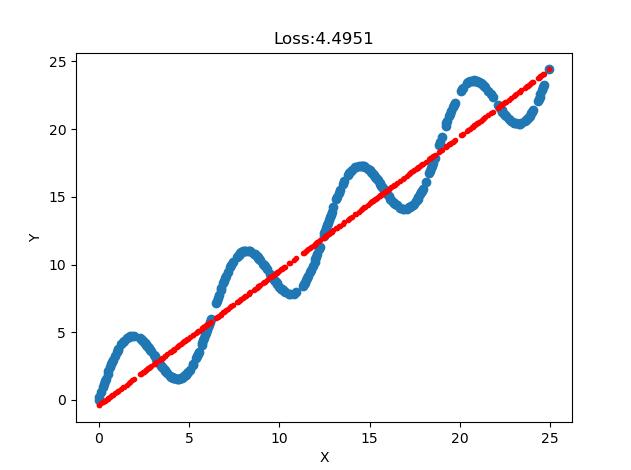
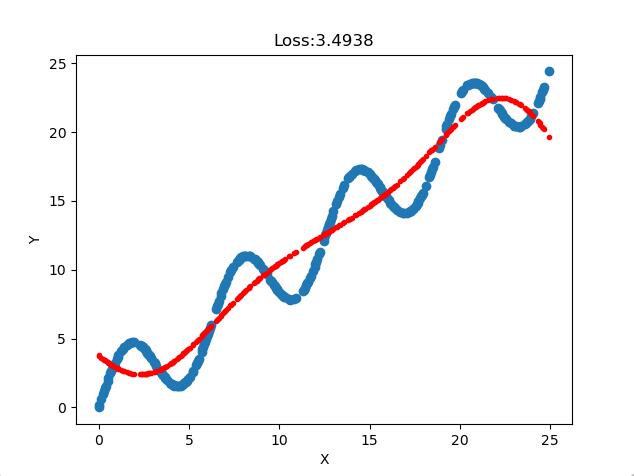
源代码:
替换不同基函数,修改basis_func赋值即可。例如:basis_func=gaussian_basis)
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# ref:https://blog.csdn.net/weixin_44113625/article/details/118790198
def identity_basis(x):
ret = np.expand_dims(x, axis=1)
return ret
def multinomial_basis(x, feature_num=10):
x = np.expand_dims(x, axis=1) # shape(N, 1)
feat = [x]
for i in range(2, feature_num + 1):
feat.append(x ** i)
ret = np.concatenate(feat, axis=1)
return ret
def gaussian_basis(x, feature_num=10):
centers = np.linspace(0, 25, feature_num)
width = 1.0 * (centers[1] - centers[0])
x = np.expand_dims(x, axis=1)
x = np.concatenate([x] * feature_num, axis=1)
out = (x - centers) / width
ret = np.exp(-0.5 * out ** 2)
return ret
def load_data(filename, basis_func=gaussian_basis):
"""载入数据。"""
xys = []
with open(filename, 'r') as f:
for line in f:
xys.append(map(float, line.strip().split()))
xs, ys = zip(*xys)
xs, ys = np.asarray(xs), np.asarray(ys)
o_x, o_y = xs, ys
phi0 = np.expand_dims(np.ones_like(xs), axis=1)
phi1 = basis_func(xs)
xs = np.concatenate([phi0, phi1], axis=1)
return (np.float32(xs), np.float32(ys)), (o_x, o_y)
(xs, ys), (o_x, o_y) = load_data('train.txt')
ndim = xs.shape[1]
x_train = torch.from_numpy(xs).float() # 将数据x转换为Tensor
y_train = torch.from_numpy(ys).float() # 将数据y转换为Tensor
# 定义模型
class LR(nn.Module):
def __init__(self):
super().__init__()
self.lr = nn.Linear(ndim, 1)
def forward(self, x):
out = self.lr(x)
return out
model = LR() # 构建模型对象
criterion = torch.nn.MSELoss() # 构建损失函数对象
optimizer = torch.optim.SGD(model.parameters(), 0.001) # 构建优化器函数对象,学习率0.001
# 训练以及评估
nums_epochs = 10000 # 将轮数设置为10,即训练将进行10轮
for i in range(nums_epochs):
input_data = x_train # 在x_train的第二个维度上增加一个维度,其目的是为计算损失data_loss时输出为标量
output_target = y_train.unsqueeze(1) # 在y_train的第二个维度上增加一个维度,其目的是为计算损失data_loss时输出为标量
output_predict = model(input_data) # 存放预测值
data_loss = criterion(output_predict, output_target) # 存放损失值
optimizer.zero_grad() # 进行梯度清零操作
data_loss.backward() # 进行反馈传播
optimizer.step() # 进行更新
print("Epoch:[{}/{}],data_loss:[{:.4f}]".format(i + 1, nums_epochs, data_loss.item()))
plt.plot(o_x, output_predict.squeeze(1).data.numpy(), 'r.') # f(x)的图像
loss_view = criterion(output_predict, output_target)
plt.title("Loss:{:.4f}".format(loss_view.item())) # 损失
plt.xlabel("X")
plt.ylabel("Y")
plt.scatter(o_x, o_y) # 数据散点图
plt.show()
