

34. 过滤条件、多表查询、子查询
1. 过滤条件
1.1 过滤条件之having
[1]概念
HAVING 子句用于对分组后的结果进行过滤。它通常与 GROUP BY 子句一起使用,在 SELECT 语句的聚合函数(如 SUM(), AVG(), COUNT(), MAX(), MIN() 等)之后应用条件。
HAVING 子句与 WHERE 子句类似,但 HAVING 适用于分组后的数据,而 WHERE 适用于原始数据。
[2]应用
分组之后的数据再进行过滤,不能用where,只能用having
案例:员工按部门进行分组,筛选出30岁以上员工的工资,筛选出30岁以上员工平均工资大于10000的部门
先筛选出30岁以上的员工数据,再对数据按部门进行分组,分组后用聚合函数avg求平均值
select post,avg(salary) from emp where age>30 group by post;
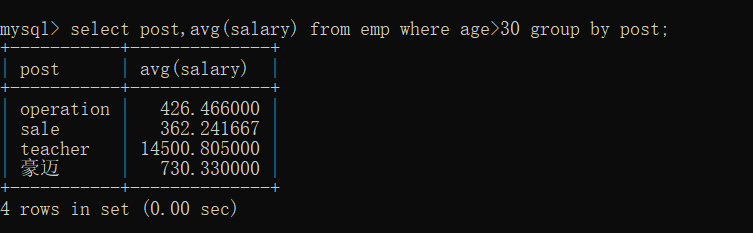
在以上分组后的基础上再筛选出平均工资大于10000的部门
方法一:分组之后的数据用where再筛选(报错)
select post,avg(salary) from emp where age>30 group by post where avg(salary)>10000;

方法二:分组之后的数据用having再筛选
select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000;

1.2 过滤条件之distinct
去重,使用SELECT语句查询数据时,distinct可以从查询结果中删除重复的行,并仅返回唯一的记录。
语法:select distinct 列1,列2... from 表名
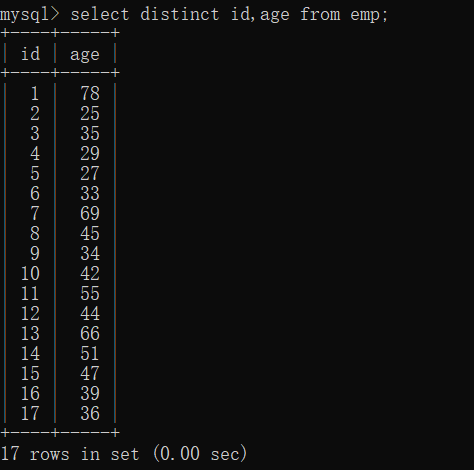
主键不重复,对主键去重无意义。
select distinct id,age from emp;
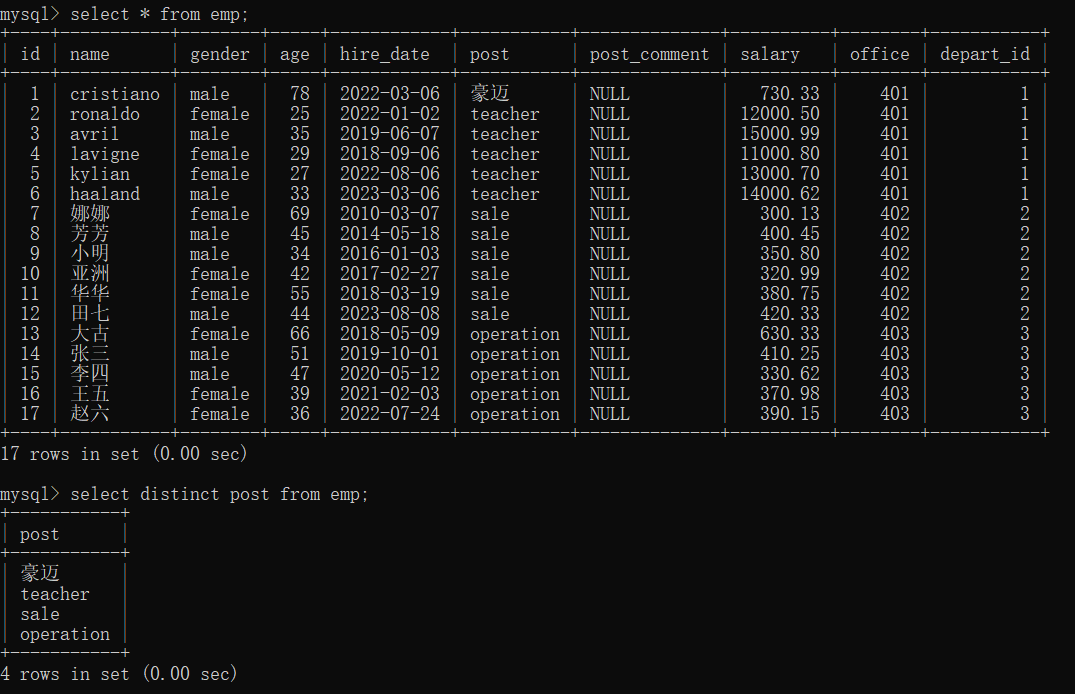
对post去重
select distinct post from emp;
1.3 过滤条件之order by
[1]概念
语法:select */列名 from 表名 order by 列名 asc/desc;
asc:升序(asc/desc不写时默认也为升序)
desc:降序
[2]代码应用
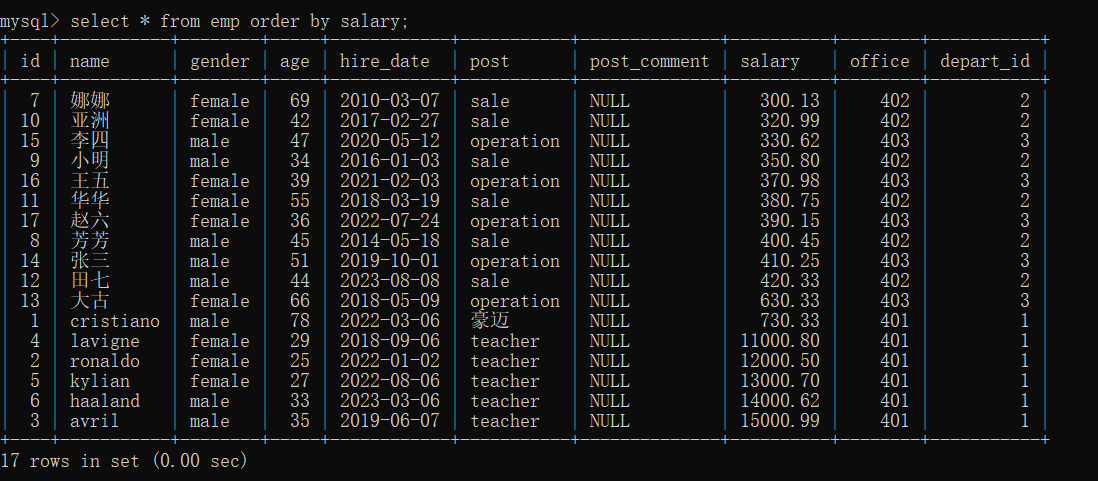
(1)查询所有数据,按工资的升序排列
select * from emp order by salary;
(2)查询所有数据,按工资的降序排列
select * from emp order by salary desc;

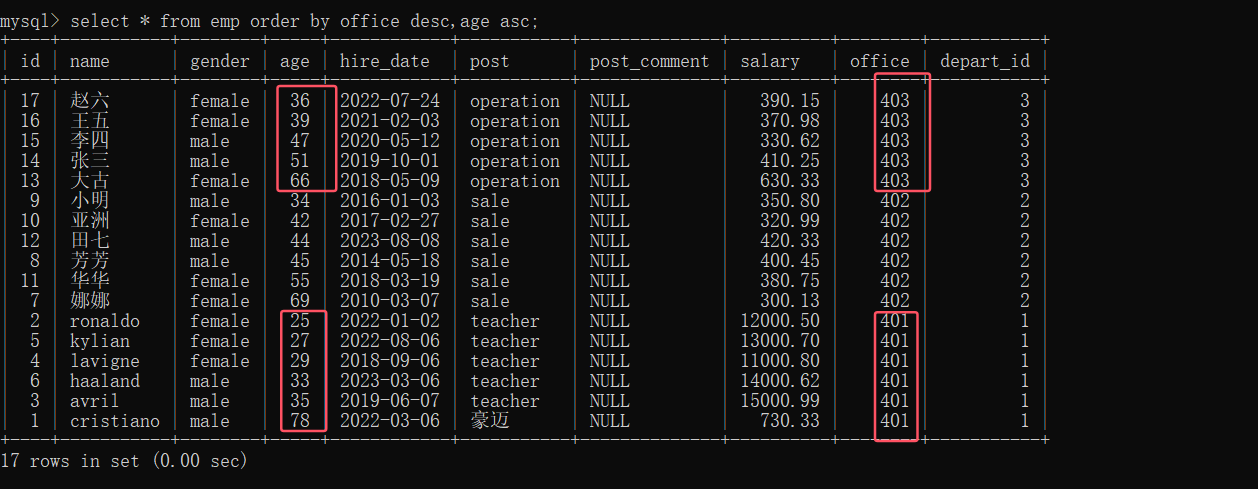
(3)先按部门编号降序排,同一个部门编号内的多条记录按年龄升序排
select * from emp order by office desc,age asc;
(4)混合排序,与where、group by、having配合使用
员工按部门进行分组,筛选出30岁以上员工的工资,筛选出30岁以上员工平均工资大于500的部门,对筛选出的列(部门、平均工资)按升序排列
select post,avg(salary) from emp where age>30 group by post having avg(salary)>500 order by avg(salary) asc;

1.4 过滤条件之limit
[1] 概念
limit子句用于限制查询结果的数量
使用方法一:
limit offset, count
offset:指定从哪一条记录开始返回数据(从0开始计数)。
count:指定返回记录的数量。
使用方法二:
limit count
只指定count时,offset默认为0,即从第一条记录开始返回数据。
[2]代码应用
(1)获取前10条记录
select * from emp limit 10;

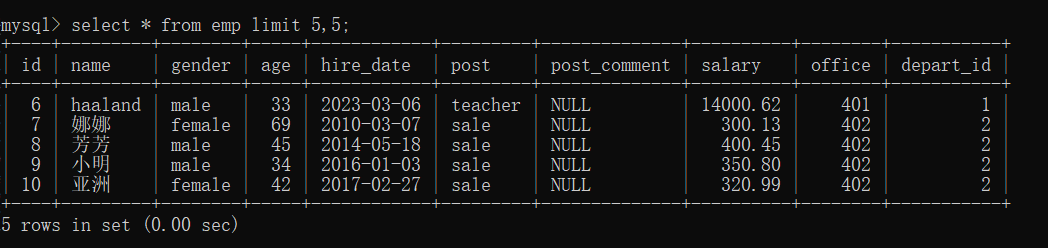
(2)从第6条记录开始,向后获取5条记录
select * from emp limit 5,5;
1.5 过滤条件之正则表达式
[1]概念
列名 REGEXP 表达式:检查列中的值是否匹配正则表达式模式。
|
选项 |
说明 |
例子 |
匹配值示例 |
|
^ |
匹配文本的开始字符 |
‘^b’ 匹配以字母 b 开头的字符串 |
book、big、banana、bike |
|
$ |
匹配文本的结束字符 |
‘st$’ 匹配以 st 结尾的字符串 |
test、resist、persist |
|
. |
匹配任何单个字符 |
‘b.t’ 匹配任何 b 和 t 之间有一个字符 |
bit、bat、but、bite |
|
* |
匹配前面的字符 0 次或多次 |
‘f*n’ 匹配字符 n 前面有任意个字符 f |
fn、fan、faan、abcn |
|
+ |
匹配前面的字符 1 次或多次 |
‘ba+’ 匹配以 b 开头,后面至少紧跟一个 a |
ba、bay、bare、battle |
|
? |
匹配前面的字符 0 次或1次 |
‘sa?’ 匹配0个或1个a字符 |
sa、s |
|
字符串 |
匹配包含指定字符的文本 |
‘fa’ 匹配包含‘fa’的文本 |
fan、afa、faad |
|
[字符集合] |
匹配字符集合中的任何一个字符 |
‘[xz]’ 匹配 x 或者 z |
dizzy、zebra、x-ray、extra |
|
[^] |
匹配不在括号中的任何字符 |
‘[^abc]’ 匹配任何不包含 a、b 或 c 的字符串 |
desk、fox、f8ke |
|
字符串{n,} |
匹配前面的字符串至少 n 次 |
‘b{2}’ 匹配 2 个或更多的 b |
bbb、bbbb、bbbbbbb |
|
字符串{n,m} |
匹配前面的字符串至少 n 次, 至多 m 次 |
‘b{2,4}’ 匹配最少 2 个,最多 4 个 b |
bbb、bbbb |
[2]代码应用
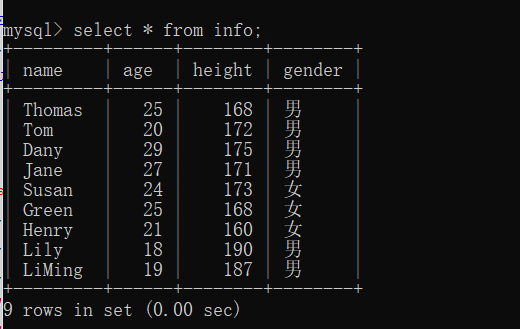
(1)准备数据

CREATE TABLE `info` (
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(40) NULL DEFAULT NULL,
`height` int(40) NULL DEFAULT NULL,
`gender` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
);
INSERT INTO `info` VALUES ('Thomas ', 25, 168, '男');
INSERT INTO `info` VALUES ('Tom ', 20, 172, '男');
INSERT INTO `info` VALUES ('Dany', 29, 175, '男');
INSERT INTO `info` VALUES ('Jane', 27, 171, '男');
INSERT INTO `info` VALUES ('Susan', 24, 173, '女');
INSERT INTO `info` VALUES ('Green', 25, 168, '女');
INSERT INTO `info` VALUES ('Henry', 21, 160, '女');
INSERT INTO `info` VALUES ('Lily', 18, 190, '男');
INSERT INTO `info` VALUES ('LiMing', 19, 187, '男');
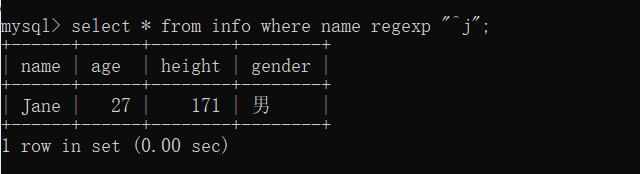
(2)查询name列以 j 开头的记录
select * from info where name regexp "^j";
(3)查询name列以 y 结尾的记录
select * from info where name regexp "y$";
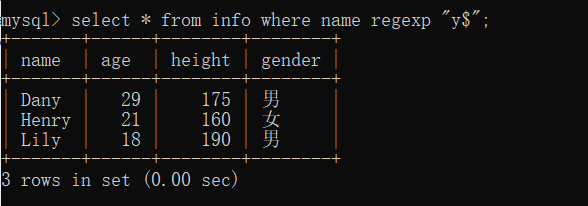
(4)查询name列的值包含a 和 y,且两个字母之间只有一个字母的记录
select * from info where name regexp "a.y";
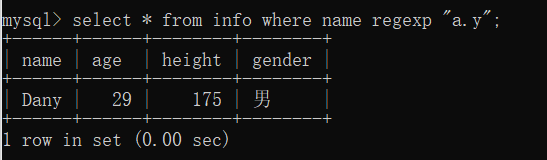
(5)查询name列的值包含T,且 T 后面出现字母 h 0次或多次的记录
select * from info where name regexp "Th*";
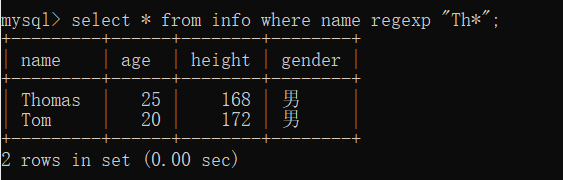
(6)查询name列的值包含T,且 T 后面至少出现h 一次的记录
select * from info where name regexp "Th+";
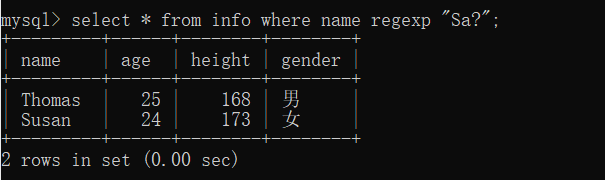
(7)查询name列的值包含S,且 S 后面出现 a 0次或一次的记录
select * from info where name regexp "Sa?";
2. 多表查询与子查询
2.1 概念
子查询:
子查询是一种嵌套在另一个查询中的查询。子查询可以出现在 SELECT, INSERT, UPDATE, 或 DELETE 语句中,并且必须被圆括号包围。
类比于解决问题的方式(一步一步解决)、将一条SQL语句的查询结果加括号当做另外一条SQL语句的查询条件。
多表查询:
多表查询通常使用 JOIN 关键字来组合来自两个或多个表的数据。
将多张表拼接在一起,形成一张表,然后基于单表查询数据。
2.2 准备数据
create table dep(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20)
);
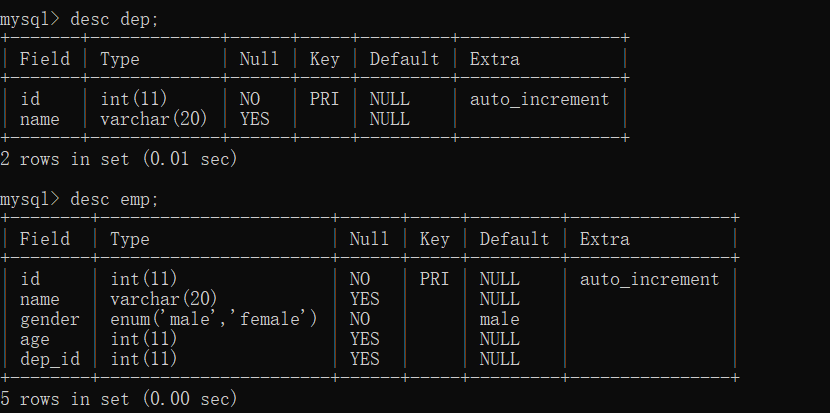
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
gender ENUM("male","female") NOT NULL DEFAULT "male",
age INT,
dep_id INT
);
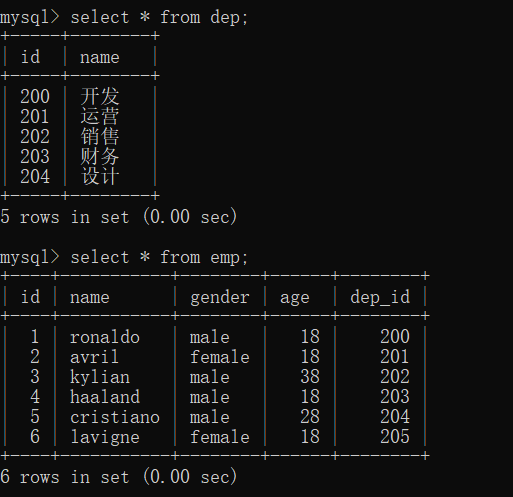
insert into dep values
("200","开发"),
("201","运营"),
("202","销售"),
("203","财务"),
("204","设计");
insert into emp(name,gender,age,dep_id) values
("ronaldo","male",18,200),
("avril","female",18,201),
("kylian","male",38,202),
("haaland","male",18,203),
("cristiano","male",28,204),
("lavigne","female",18,205);
2.3 子查询
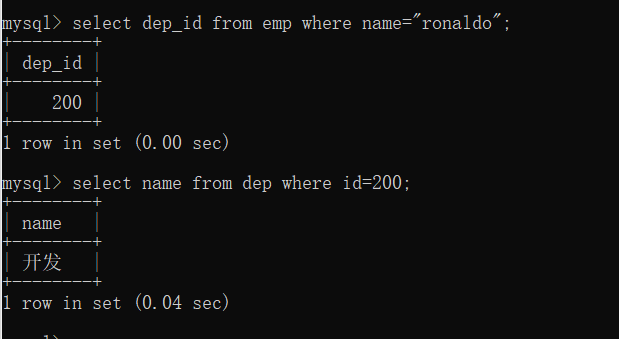
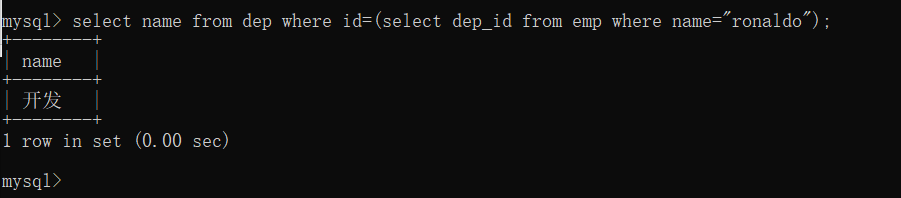
(1)案例1:获取员工ronaldo所在的部门名称
方法一:分步查询
先在员工表中查询员工ronaldo部门id,再去部门表中根据部门id查询部门名称
select dep_id from emp where name="ronaldo";
select name from dep where id=200;
方法二:子查询
将方法一的两步合并为一步,将一个SQL语句的结果加上括号作为查询条件
select name from dep where id=(select dep_id from emp where name="ronaldo");
(2)案例2:查询开发或运营部门的员工信息
方法一:分步查询
先在部门表中查询对应部门id,再去员工表中根据部门id查询对应员工信息
select id from dep where name="开发" or name="运营";
select * from emp where dep_id=200 or dep_id=201;
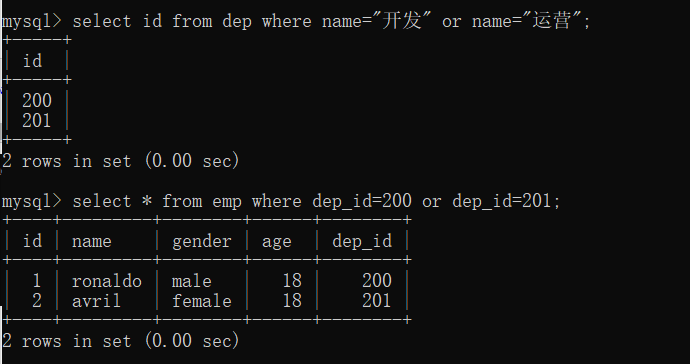
方法二:子查询
将方法一的两步合并为一步
select * from emp where dep_id in (select id from dep where name="开发" or name="运营");

2.4 多表查询
[1]笛卡尔积
(1)笛卡尔积的概念
笛卡尔积是一个数学概念,它描述的是两个集合之间所有可能的元素组合的数量。
具体来说,如果集合A有n个元素,集合B有m个元素,则它们的笛卡尔积的大小为nm。
(2)笛卡尔积的理解
笛卡尔积是通过组合两个集合的所有元素来创建一个新的集合的过程。
在最简单的例子中,如果有一个集合包含三个元素a、b和c,另一个集合包含两个元素x和y,那么这两个集合的笛卡尔积将包含六个元素:ax、ay、bx、by、cx和cy。
(3)MySQL中的笛卡尔积
在SQL中,当使用JOIN操作将两个或更多的表连接在一起时,结果集中的行数是所有连接表的行数的乘积。这就是所谓的笛卡尔积。
例如,假设有两个表A和B,其中A有5行,B有3行。
如果使用INNER JOIN将这两个表连接起来,那么结果集中将会有5 x 3 = 15行。
这是因为对于每一行A,可以从B中选择任意一行进行匹配。
因此,总共有5种不同的方式来组合A表中的每一行和B表中的每一行,这导致了最终结果集的大小为5 x 3 = 15。
这个过程就是笛卡尔积,它是数学中的一种运算,用于计算两个集合的所有可能的元素组合的数量。
在这个情况下,每个元素都是一个表格中的行。
所以,当在MySQL中使用JOIN操作时,结果集的大小实际上是所有连接表的行数的乘积,这就是为什么称其为笛卡尔积的原因。
[2]拼虚拟表
拼虚拟表的结果即为笛卡尔积
select * from dep,emp;
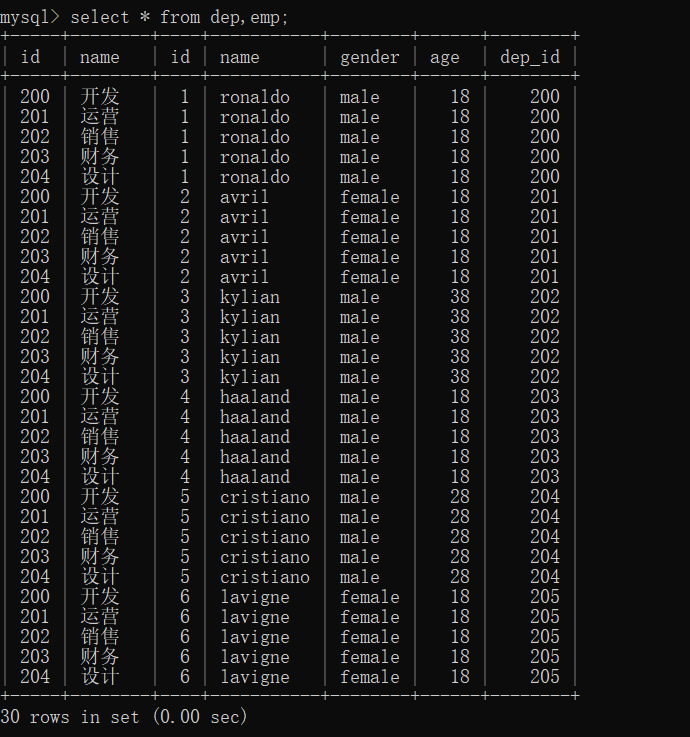
[3]虚拟表去除无效数据
虽然部门表和员工表没有通过外键直接关联,但是设计的初衷是部门表的id即为员工表的dep_id,因此拼接虚拟表生成了大量的无效数据,需要去除
select * from dep,emp where dep.id=emp.dep_id;

部门表的id=员工表的dep_id 的记录才会被保留
[4]拼表关键字
(1)概念
inner join:内连接、交集
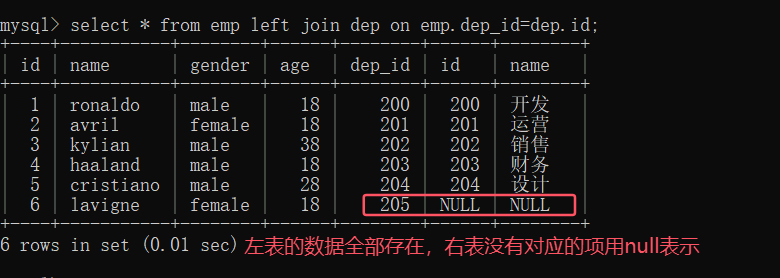
left join:左连接 、左表所有的数据都展示出来,右表中没有对应的项就用null表示
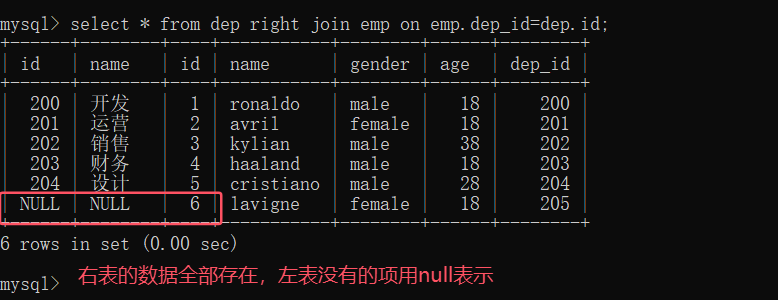
right join:右连接 、右表所有的数据都展示出来,左表中没有对应的项就用null表示
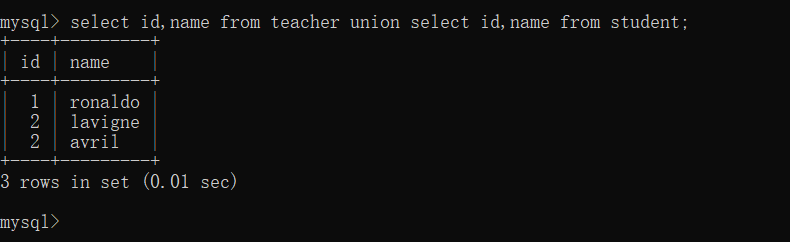
union:全连接 、合并两个或多个 SELECT 语句的结果集,每个 SELECT 语句中的列数必须相同,并且对应列的数据类型也必须兼容,默认去除重复的行
(2)内连接代码示例
inner join仍然为全部拼接,加上限制条件部门表的id=员工表的dep_id后,由于部门表的id没有205,因此求交集被舍去
select * from emp inner join dep;
select * from emp inner join dep on emp.dep_id=dep.id;
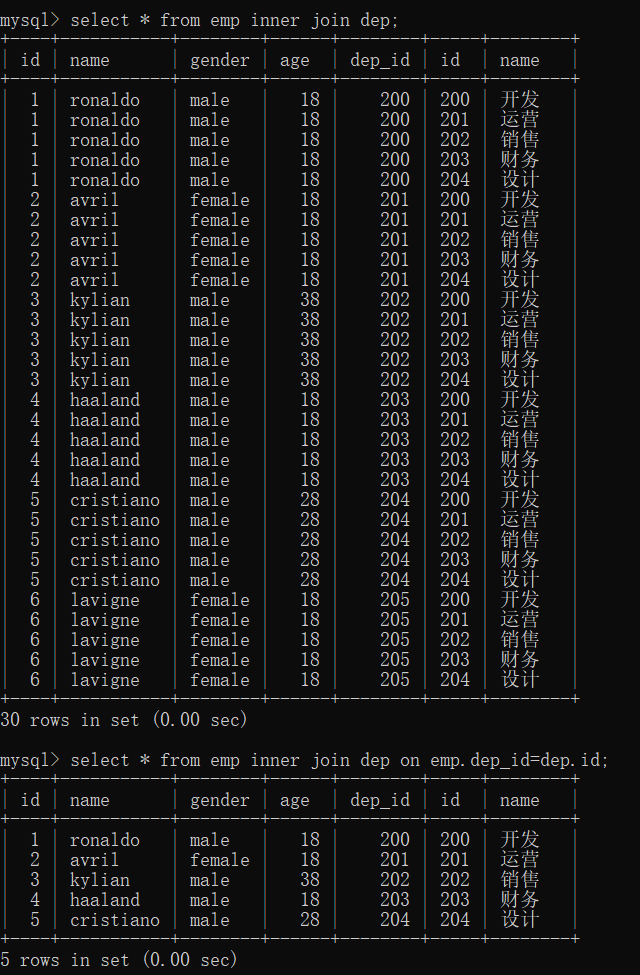
(3)左连接代码示例
select * from emp left join dep on emp.dep_id=dep.id;
(4)右连接代码示例
select * from dep right join emp on emp.dep_id=dep.id;
(5)全连接代码示例
基本语法:
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2;
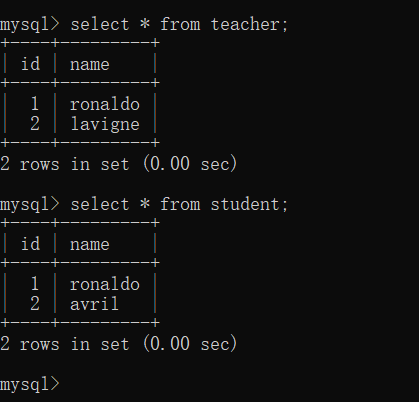
create table teacher(id int auto_increment primary key, name varchar(30));
insert into teacher (id, name) values (1, 'ronaldo'), (2, 'lavigne');
create table student(id int auto_increment primary key, name varchar(30));
insert into student (id, name) values (1, 'ronaldo'), (2, 'avril');
使用union:
去掉了重复的记录
select id,name from teacher union select id,name from student;
2.5 多表查询与子查询的综合应用
[1]需求:
查询平均年龄在25岁以上的部门名称
[2]方法1:多表查询实现
步骤1:拼表,将部门表与员工表拼接在一起
select * from dep inner join emp on dep.id=emp.dep_id;
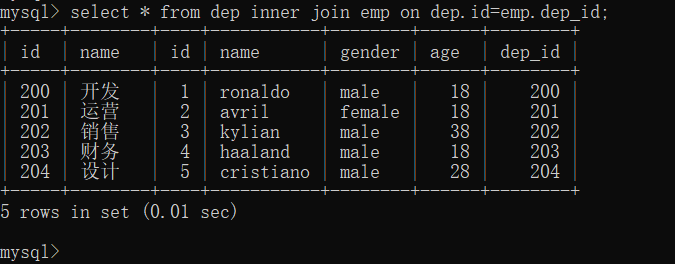
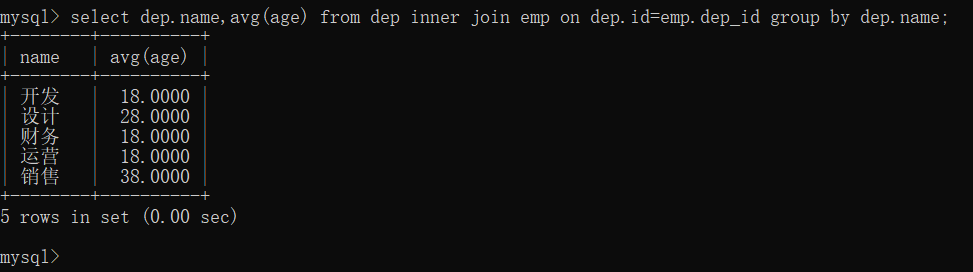
步骤2:在拼表的基础上按部门进行分组,分组后获取当前分组的平均年龄,再过滤出平均年龄大于25岁的部门名称
select dep.name,avg(age) from dep inner join emp on dep.id=emp.dep_id group by dep.name;
select dep.name,avg(age) from dep inner join emp on dep.id=emp.dep_id group by dep.name having avg(age)>25;

[3]方法二:子查询实现
步骤1:对员工表按照部门id进行分组,筛选出年龄大于25岁的部门id
select dep_id from emp group by dep_id having avg(age)>25;
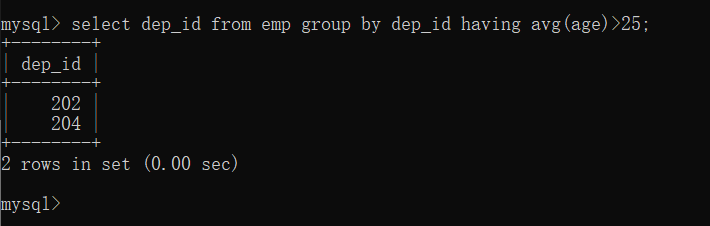
步骤2:将步骤1的结果作为查询条件,去部门表中筛选出对应的部门名称
select name from dep where id in (select dep_id from emp group by dep_id having avg(age)>25);

2.6 子查询运算符之exists
EXISTS子句用于检查子查询是否返回任何行。如果子查询返回至少一行数据,那么EXISTS子句的结果为TRUE;如果子查询没有返回任何行,那么结果为FALSE。这个子句通常与WHERE子句一起使用。
返回TRUE时,外层查询语句执行;返回FALSE时,外层查询语句不执行。
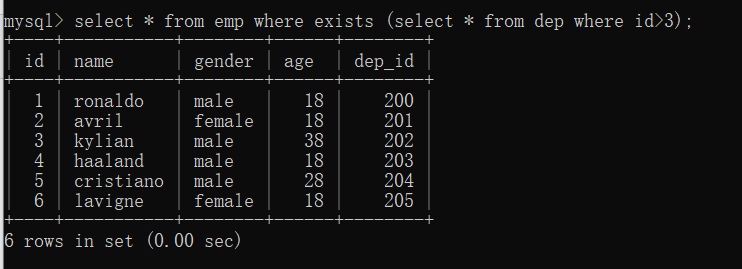
select * from emp where exists (select * from dep where id>3);
子查询不止返回一行数据,结果为TRUE,外层查询语句执行
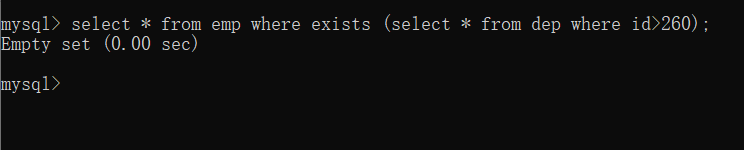
select * from emp where exists (select * from dep where id>260);
子查询没有返回任何行,结果为FALSE,外层查询语句不执行

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步