29. GIL全局解释器锁、信号量、线程池进程池
1. GIL全局解释器锁
1.1 概念
'''
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程运行,无法利用多核优势
'''
GIL是一个纯理论知识,编程过程中无需考虑它的存在。
怎样理解互斥锁的存在:不加互斥锁时开启多线程,第一个线程里面的代码运行完毕才能去运行第二个线程里面的代码(在子线程功能函数没有休眠的前提下)
1.2 GIL锁的代码理解:多线程不加互斥锁、无休眠
这个例子验证了GIL锁存在,一个线程结束之后才能运行下一个线程,即证明有锁存在
from threading import Thread
num = 6
def work():
global num
temp = num
print(f'休眠之前为{num}')
num = temp - 1
print(f'休眠之后为{num}')
def create_thread():
print(f'修改之前为{num}')
task_list = [Thread(target=work) for i in range(6)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后为{num}')
if __name__ == '__main__':
create_thread()

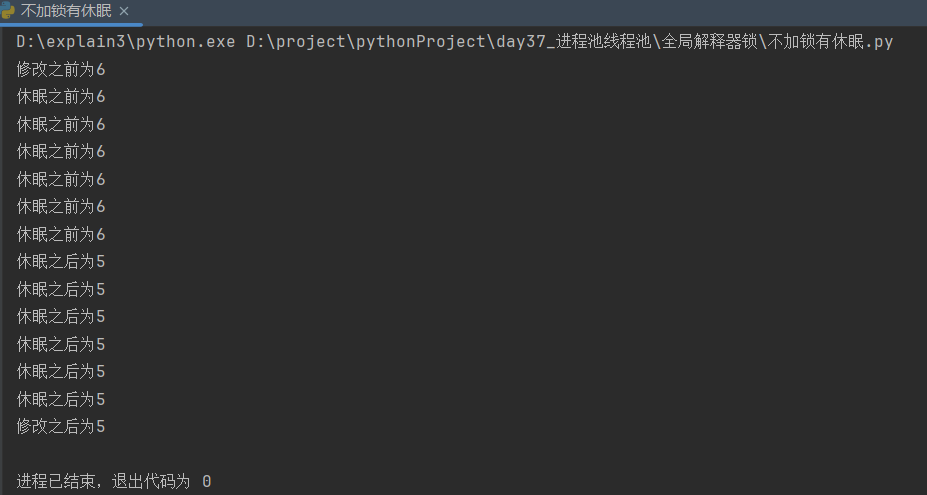
1.3 其它情况对照:多线程不加互斥锁、有休眠
import time
from threading import Thread
num = 6
def work():
global num
temp = num
print(f'休眠之前为{num}')
time.sleep(0.001) # 休眠起到切换线程的作用
num = temp - 1
print(f'休眠之后为{num}')
def create_thread():
print(f'修改之前为{num}')
task_list = [Thread(target=work) for i in range(6)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后为{num}')
if __name__ == '__main__':
create_thread()
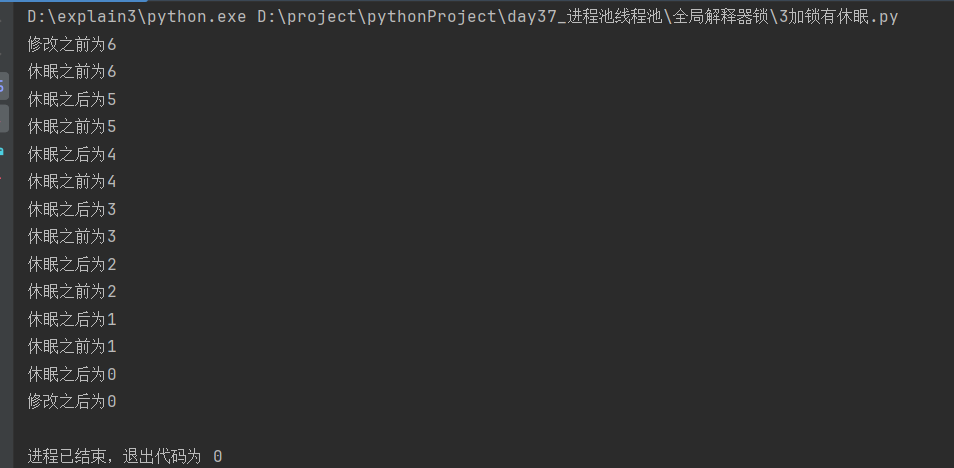
1.4 其它情况对照:多线程互斥加锁、有休眠
import time from threading import Thread, Lock num = 6 def work(lock): lock.acquire() global num temp = num print(f'休眠之前为{num}') time.sleep(0.001) # 休眠起到切换线程的作用;加了锁之后休眠已经无法切换线程 num = temp - 1 print(f'休眠之后为{num}') lock.release() def create_thread(): lock = Lock() print(f'修改之前为{num}') task_list = [Thread(target=work, args=(lock,)) for i in range(6)] [task.start() for task in task_list] [task.join() for task in task_list] print(f'修改之后为{num}') if __name__ == '__main__': create_thread()
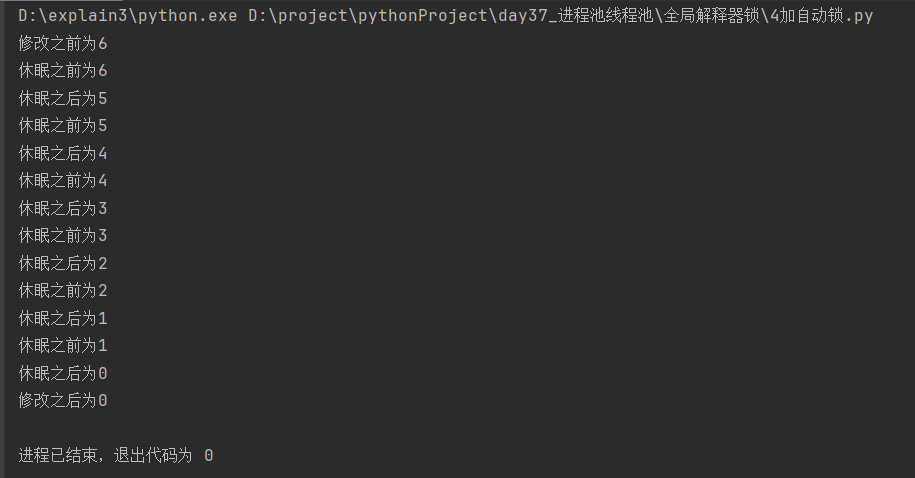
1.5 其它情况对照:加自动互斥锁
子线程启动 , 后先去抢 GIL 锁 , 进入 IO 自动释放 GIL 锁 , 但是自己加的锁还没解开 ,其他线程资源能抢到 GIL 锁,但是抢不到互斥锁
最终 GIL 回到 互斥锁的那个进程上,处理数据
import time
from threading import Thread, Lock
num = 6
lock = Lock()
def work():
with lock: # 加上自动锁
global num
temp = num
print(f'休眠之前为{num}')
time.sleep(0.001) # 休眠起到切换线程的作用;加锁之后休眠已经无法切换线程
num = temp - 1
print(f'休眠之后为{num}')
def create_thread():
print(f'修改之前为{num}')
task_list = [Thread(target=work) for i in range(6)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后为{num}')
if __name__ == '__main__':
create_thread()
1.6 GIL全局解释器锁导致多线程无法利用多核优势
在Cpython解释器中GIL是互斥锁,用来阻止同一个进程下的多个线程同时运行。
在Cpython中的内存管理(垃圾回收机制:引用计数、标记清除、分代回收)不是线程安全的。
同一个进程下的多线程无法利用多核优势,是不是就没用了?多线程是否有用要看情况。
(1)计算密集型
计算密集型多进程下的耗时
import time
import os
from multiprocessing import Process
def work_calculate():
result = 1
for i in range(1, 90):
result *= i
# print(f'计算结果为{result}')
def cal_time(func):
def inner(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print(f'函数{func.__name__}总耗时: {end - start}')
return res
return inner
@cal_time
def create_process():
print(f'正在使用的CPU个数{os.cpu_count()}')
task_list = [Process(target=work_calculate) for i in range(90)]
[task.start() for task in task_list]
[task.join() for task in task_list]
if __name__ == '__main__':
create_process()

计算密集型多线程下的耗时
import time
import os
from threading import Thread
def work_calculate():
result = 1
for i in range(1, 90):
result *= i
# print(f'计算结果为{result}')
def cal_time(func):
def inner(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print(f'函数{func.__name__}总耗时: {end - start}')
return res
return inner
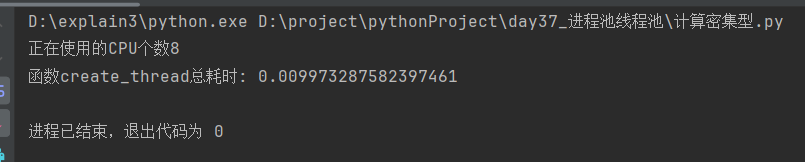
@cal_time
def create_thread():
print(f'正在使用的CPU个数{os.cpu_count()}')
task_list = [Thread(target=work_calculate) for i in range(90)]
[task.start() for task in task_list]
[task.join() for task in task_list]
if __name__ == '__main__':
create_thread()
(2)IO密集型
模仿IO密集型:多个IO切换操作
IO密集型多进程下的耗时
import os
import time
from multiprocessing import Process
def io_switch():
# print('子进程开始运行')
time.sleep(1)
# print('子进程结束运行')
def cal_time(func):
def inner(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print(f'函数{func.__name__}运行总耗时{end - start}')
return res
return inner
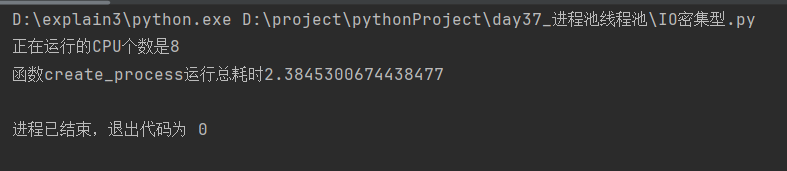
@cal_time
def create_process():
print(f'正在运行的CPU个数是{os.cpu_count()}')
task_list = [Process(target=io_switch) for i in range(90)]
[task.start() for task in task_list]
[task.join() for task in task_list]
if __name__ == '__main__':
create_process()
IO密集型多线程下的耗时
import os
import time
from threading import Thread
def io_switch():
# print('子线程开始运行')
time.sleep(1)
# print('子线程结束运行')
def cal_time(func):
def inner(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print(f'函数{func.__name__}运行总耗时{end - start}')
return res
return inner
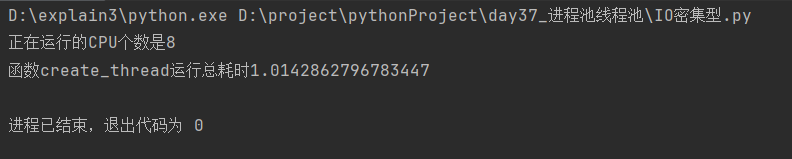
@cal_time
def create_thread():
print(f'正在运行的CPU个数是{os.cpu_count()}')
task_list = [Thread(target=io_switch) for i in range(90)]
[task.start() for task in task_list]
[task.join() for task in task_list]
if __name__ == '__main__':
create_thread()
(3)计算密集型与IO密集型的理论
[1]计算密集型任务(多进程)
计算密集型任务主要是指需要大量的CPU计算资源的任务,其中包括执行代码、进行算术运算、循环等。
在这种情况下,使用多线程并没有太大的优势。
由于Python具有全局解释器锁(Global Interpreter Lock,GIL),在同一时刻只能有一条线程执行代码,这意味着在多线程的情况下,同一时刻只有一个线程在执行计算密集型任务。
但是,如果使用多进程,则可以充分利用多核CPU的优势。
每个进程都有自己独立的GIL锁,因此多个进程可以同时执行计算密集型任务,充分发挥多核CPU的能力。
通过开启多个进程,我们可以将计算密集的任务分配给每个进程,让每个进程都独自执行任务,从而提高整体的计算效率。
[2]IO密集型任务(多线程)
IO密集型任务主要是指涉及大量输入输出操作(如打开文件、写入文件、网络操作等)的任务。
在这种情况下,线程往往会因为等待IO操作而释放CPU执行权限,不会造成太多的CPU资源浪费。
因此,使用多线程能够更好地处理IO密集型任务,避免了频繁切换进程的开销。
当我们在一个进程中开启多个IO密集型线程时,大部分线程都处于等待状态,开启多个进程却不能提高效率,反而会消耗更多的系统资源。
因此,在IO密集型任务中,使用多线程即可满足需求,无需开启多个进程。
[3]总结
计算密集型任务:使用多进程可以充分利用多核CPU的优势,CPU越多越好
IO密集型任务:使用多线程能够更好地处理IO操作,避免频繁的进程切换开销。
根据任务的特性选择合适的并发方式可以有效提高任务的执行效率。
计算消耗cpu多:代码执行,算术,for都是计算
io消耗cpu少:打开文件,写入文件,网络操作都是io
如果遇到io,该线程会释放cpu的执行权限,cpu转而去执行别的线程
由于python有gil锁,开启多条线程,同一时刻,只能有一个线程在执行
如果是计算密集型,开了多线程,同一时刻,只有一个线程在执行
多核cpu,就会浪费多核优势
如果是计算密集型,我们希望,多个核(cpu),都干活,同一个进程下绕不过gil锁
所以我们开启多进程,gil锁只能锁住某个进程中得线程,开启多个进程,就能利用多核优势
io密集型:只要遇到io,就会释放cpu执行权限
进程内开了多个io线程,线程多半都在等待,开启多进程是不能提高效率的,反而开启进程很耗费资源,所以使用多线程即可
1.7 GIL特点总结
GIL不是python的特点,而是Cpython解释器的特点
GIL作用面很窄,仅限于保证解释器级别的数据安全;
自定义锁用来保证更大范围的数据安全。
GIL会导致同一个进程下的多个线程无法同时进行,即无法利用多核优势
针对不同的数据需要加不同的锁处理
解释性语言共同的短板:同一个进程下的多个线程无法利用多核优势
2. 死锁
2.1 概念
死锁是指两个或多个进程(线程),在运行的过程中,因争夺资源而造成的互相等待的现象。
两个或多个进程(线程)持有各自的锁并试图获取对方持有的锁,从而导致阻塞,不能向后运行代码。
解决办法:如果发生了死锁问题,必须使一方先交出锁。
2.2 代码示例
import time
from threading import Thread, Lock
# 类加括号多次,每次产生的都是不同的对象 如果想要实现多次加括号得到的是相同的对象---单例模式
lock_a = Lock()
lock_b = Lock()
class NewThread(Thread):
def run(self):
self.work_one() # 运行子线程函数
self.work_two()
def work_one(self):
lock_a.acquire() # 先拿锁a
print(f'{self.name}拿到了锁a') # Thread类里面有name属性,获取线程名
lock_b.acquire() # 再拿锁b
print(f'{self.name}拿到了锁b')
lock_b.release() # 先释放锁b
print(f'{self.name}释放了锁b')
lock_a.release() # 再释放锁a
print(f'{self.name}释放了锁a')
def work_two(self):
lock_b.acquire() # 先拿锁b
print(f'{self.name}拿到了锁b,开始睡觉0.001秒')
time.sleep(0.001)
print(f'{self.name}睡觉结束')
lock_a.acquire() # 再拿锁a
print(f'{self.name}拿到了锁a')
lock_a.release() # 释放锁a
print(f'{self.name}释放了锁a')
lock_b.release()
print(f'{self.name}释放了锁b')
# 定义产生子线程函数
def create_thread():
st_list = [NewThread() for i in range(1, 3)]
[st.start() for st in st_list]
if __name__ == '__main__':
create_thread()
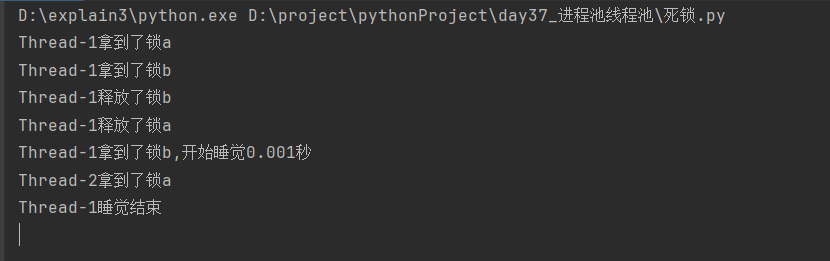
分析:
函数的运行顺序为:先运行完一个函数里面所有的代码,再去运行第二个函数
线程1运行到获取锁a,将切换到线程2,线程2由于获取不到锁a,将切换到线程3,线程3获取不到锁a,切换到线程1,线程1执行获取锁a之后的代码
获取锁b---释放锁b---释放锁a
---线程1获取锁b(锁b未释放)
---切换到线程2---线程2获取锁a(锁a未释放)
---切换到线程3---线程3获取不到锁a
---切换到线程1---打印“线程1拿到锁b,开始睡觉0.001秒”
---休眠,切换到线程2---打印“线程2拿到了锁a”---线程2获取不到锁b
---切换到线程3---线程获取不到锁a
---切换到线程1---打印“线程1睡觉结束”---线程1获取不到锁a
---切换到线程2---线程2仍然获取不到锁b---切换到线程3---线程3仍然获取不到锁a---程序进入阻塞状态
3. 递归锁
3.1 概念
递归锁(也称可重入锁)是一种特殊的锁,允许一个线程多次请求同一个锁,称为“递归的”请求锁。
在该线程释放锁之前,会对锁计数器进行累加操作,线程每成功获得一次锁时,都要进行相应的解锁操作,直到锁计数器清零才能完全释放该锁。
递归锁能够保证同一线程在持有锁时能够再次获取该锁,而不被自己所持有的锁阻塞,从而避免死锁。
但是注意要正常使用递归锁,避免过多的获取锁导致性能下降。
可以被连续的acquire和release,但是只能被第一个获取到这把锁的线程执行该操作
内部有计数器,acquire一次计数+1,release一次计数-1
只要计数不为0,其它线程都无法获取该锁
3.2 代码示例
在死锁的基础上,将Lock模块改为RLock模块,并且两把锁都指向同一个锁对象即可
import time
from threading import Thread, RLock
lock_a = lock_b = RLock() # 两个变量名指向同一把锁
class NewThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
lock_a.acquire()
print(f'{self.name}获取到了锁a') # self.name获取线程名
lock_b.acquire()
print(f'{self.name}获取到了锁b')
lock_b.release()
print(f'{self.name}释放了锁b')
lock_a.release()
print(f'{self.name}释放了锁a')
def func2(self):
lock_b.acquire()
print(f'{self.name}拿到了锁b,开始睡觉0.001秒')
time.sleep(0.001)
print(f'{self.name}睡觉结束')
lock_a.acquire()
print(f'{self.name}拿到了锁a')
lock_a.release() #
print(f'{self.name}释放了锁a')
lock_b.release()
print(f'{self.name}释放了锁b')
# 定义产生子线程函数
def create_thread():
st_list = [NewThread() for i in range(1, 3)]
[st.start() for st in st_list]
if __name__ == '__main__':
create_thread()
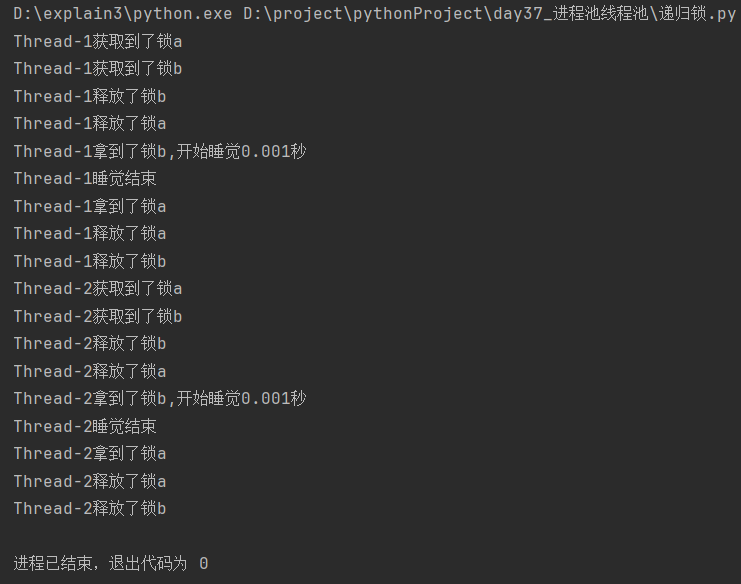
分析:
根据递归锁的定义:一个线程可以多次请求同一个锁
线程1获取锁a---切换到线程2---线程2获取不到锁a---切换到线程3---线程3获取不到锁a---切换到线程1---线程1获取锁b---线程1释放锁b---线程1释放锁a(所有锁释放完毕)
线程1获取锁b(未释放)---切换到线程2---线程2获取不到锁a(锁a锁b为同一个锁对象)---切换到线程3---线程3获取不到锁a---切换到线程1
线程1休眠---将切换线程--其它线程仍然获取不到锁a---切换到线程1---线程1获取锁a---线程1释放锁a---线程1释放锁b---线程1功能函数所有代码运行完毕
因此,该代码的运行顺序是先将一个线程中的代码运行完毕,再去运行另外一个线程中的代码
4. 信号量(了解知识点)
4.1 概念
进程与线程中都有信号量模块Semaphore
GIL锁同一时刻只允许一个线程运行,而信号量同一时刻允许一定数量的线程运行
举例:有一条非常长的铁路,GIL锁是同一时刻该铁路上只能运行1辆列车;信号量是可以运行指定数量的列车,当有1辆列车运行到站时,等待中的列车可以发1辆车。
信号量与进程池的概念比较像,但是要区分开,信号量涉及到获取和释放的概念。
4.2 进程中的信号量
[1]无休眠
from multiprocessing import Process, Semaphore
def train(sem, num):
sem.acquire() # 获取信号量
print(f'列车{num}开始发车')
print(f'列车{num}到站')
sem.release() # 释放信号量
def create_process(sem):
sp_list = [Process(target=train, args=(sem, i)) for i in range(1, 10)]
[sp.start() for sp in sp_list]
[sp.join() for sp in sp_list]
if __name__ == '__main__':
signal = Semaphore(3) # 生成信号量对象,默认参数是1
create_process(sem=signal)

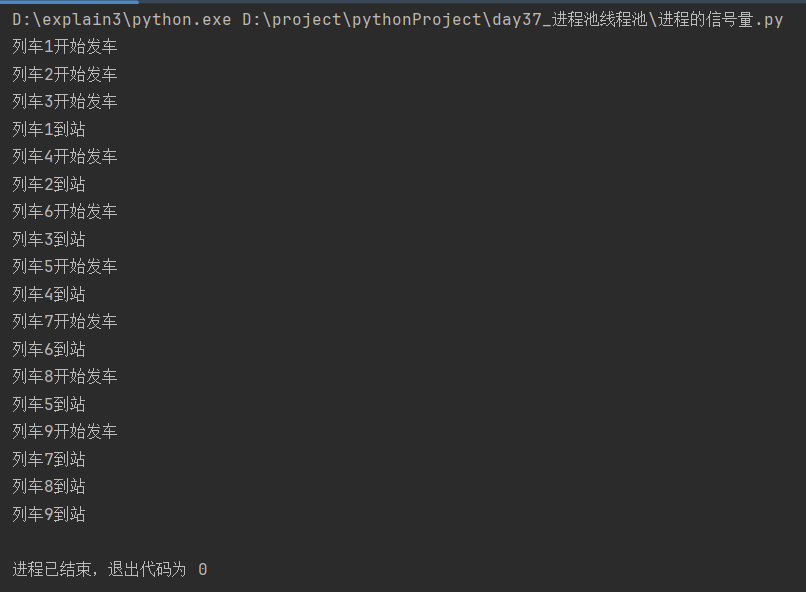
[2]有休眠
import time
from multiprocessing import Process, Semaphore
def train(sem, num):
sem.acquire() # 获取信号量
print(f'列车{num}开始发车')
time.sleep(1)
print(f'列车{num}到站')
sem.release() # 释放信号量
def create_process(sem):
sp_list = [Process(target=train, args=(sem, i)) for i in range(1, 10)]
[sp.start() for sp in sp_list]
[sp.join() for sp in sp_list]
if __name__ == '__main__':
signal = Semaphore(3) # 生成信号量对象,默认参数是1
create_process(sem=signal)
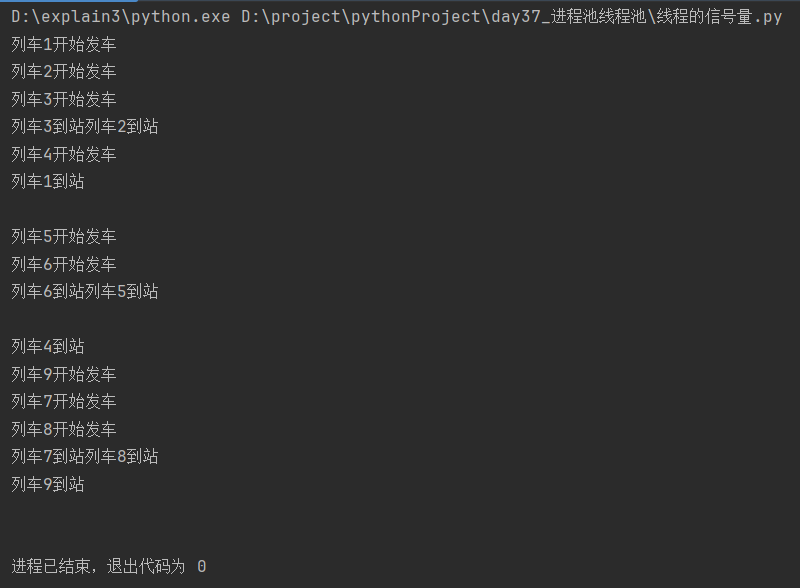
4.3 线程中的信号量
import time
from threading import Thread, Semaphore
def train(sem, num):
sem.acquire() # 获取信号量
print(f'列车{num}开始发车')
time.sleep(1)
print(f'列车{num}到站')
sem.release() # 释放信号量
def create_thread(sem):
st_list = [Thread(target=train, args=(sem, i)) for i in range(1, 10)]
[st.start() for st in st_list]
[st.join() for st in st_list]
if __name__ == '__main__':
signal = Semaphore(3) # 生成信号量对象,默认参数是1
create_thread(sem=signal)
5. Event事件(了解知识点)
5.1 概念
python线程的事件的作用:一个线程可以控制另一个线程的运行
事件提供了三个方法:set、wait、clear
事件的处理机制:
全局定义了一个"Flag",初始值值为Flase
如果"Flag"值为False,程序运行到event.wait会阻塞
如果"Flag"值为True,程序运行到event.wait不会阻塞
clear:将"Flag"值设置为False
set:将"Flag"值设置为True
5.2 代码示例
import time
from threading import Thread, Event
# 定义列车信号灯线程功能函数
def railway_light(event):
print('红灯亮,所有列车处于等待中')
time.sleep(10)
print('绿灯亮,所有列车发车')
event.set()
# 定义列车发车线程功能函数
def train(event, num):
print(f'列车{num}等待发车信号')
event.wait()
print(f'列车{num}发车')
# 定义产生子线程函数
def create_thread():
signal = Event() # 生成事件对象
railway_light_thread = Thread(target=railway_light, args=(signal,)) # 产生信号灯子线程
railway_light_thread.start()
train_thread_list = [Thread(target=train, args=(signal, i)) for i in range(1, 10)]
[train_st.start() for train_st in train_thread_list]
if __name__ == '__main__':
create_thread()
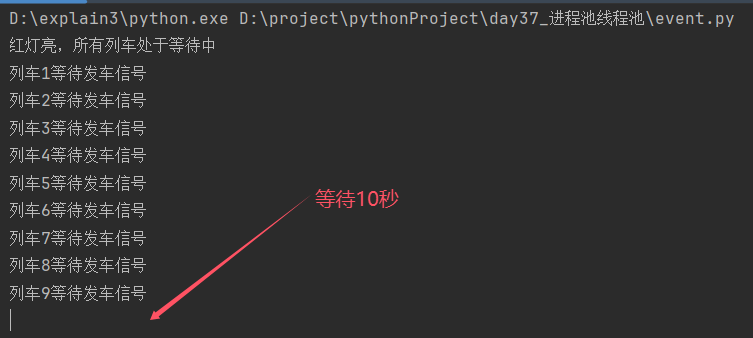
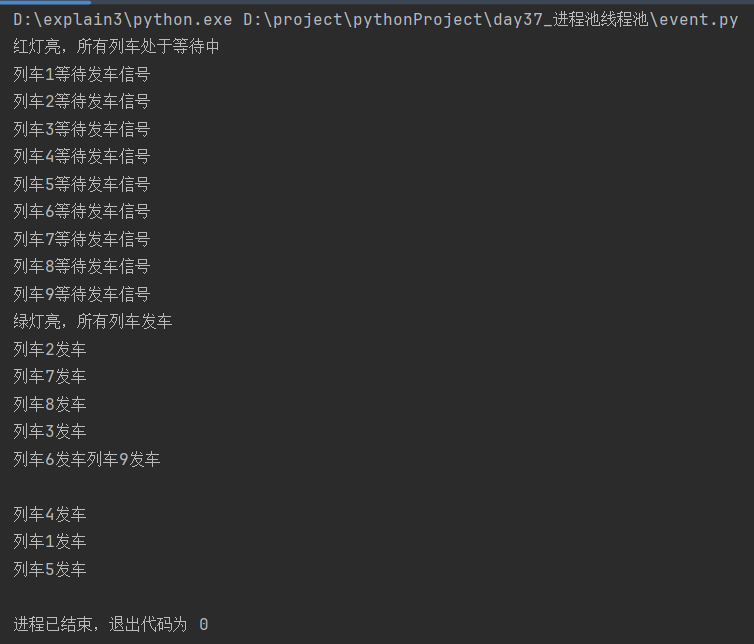
分析:
列车信号灯线程先启动,打印"红灯亮,所有列车处于等待中"
进入10秒休眠---切换到列车发车线程1---打印"列车1等待发车信号"---wait为默认值False---程序阻塞
线程启动耗时极短,在休眠结束前列车发车9个线程依次启动,运行到wait都阻塞
休眠结束---打印"绿灯亮,所有列车发车"---set将Event对象的"Flag"设置为True---wait在收到"Flag"由False改为True时取消阻塞---依次打印"列车发车"
6. 进程池与线程池
6.1 线程池
[1]概念
提前创建好固定数量的线程,后续反复使用这些线程
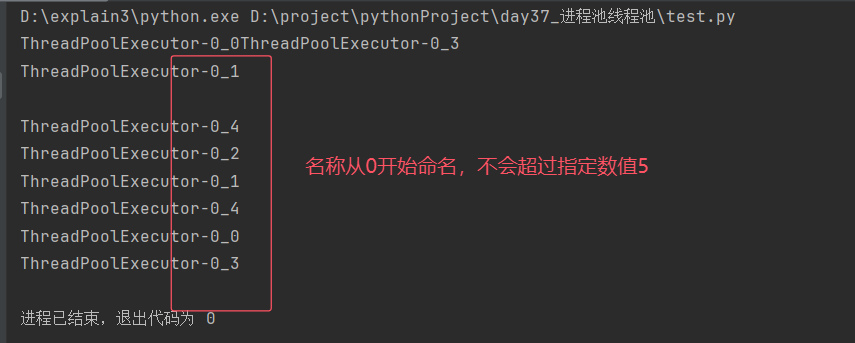
如果任务超出了线程池最大线程数,则等待
[2]线程名称不会超过指定线程的数值
import time
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程;默认:min(32, (os.cpucount() or 1) + 4)
def work():
time.sleep(0.001) # 休眠防止线程启动速度极快而导致都用一个线程名
print(current_thread().name) # ThreadPoolExecutor-0_?的名称不会超过5
for i in range(1, 10):
pool.submit(work) # 往线程池中添加任务
[3]任务的提交方式
同步提交:
在提交任务后,主进程会等待任务完成,才继续运行后续代码。
异步提交:
在提交任务后,主进程不会等待任务完成,而是继续运行后续代码。
任务的结果可以通过回调函数或者在需要结果的时候再获取。
这允许主进程同时处理多个任务。
[4]线程池提交任务的方式是异步
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程
def work(num):
print(f'{num}开始')
print(f'{num}结束')
for i in range(1, 10):
pool.submit(work, i) # 往线程池中提交任务
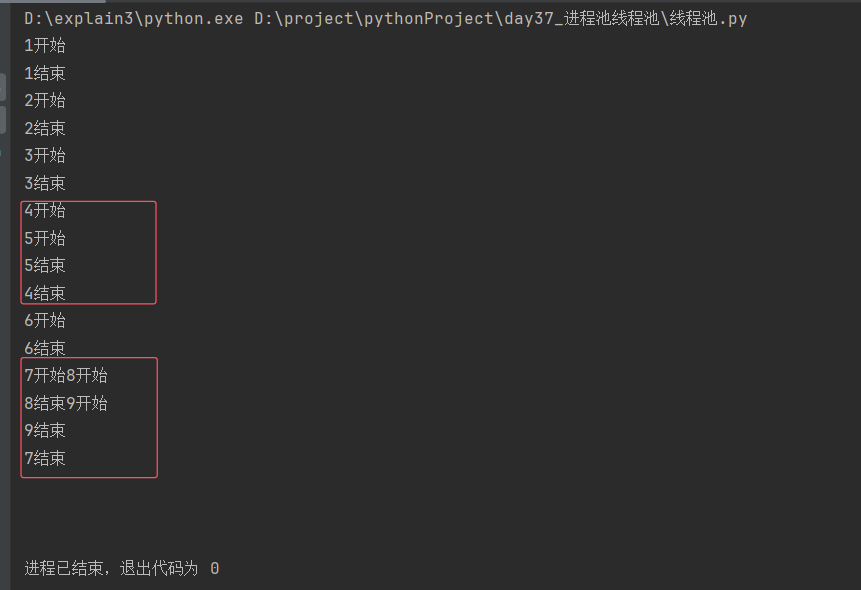
分析:
开始与结束之间无sleep,如果是同步提交,则下一个任务要等待上一个任务运行完成才能启动,类比串行来理解;
而以上代码在"开始"与"结束"之间没有休眠的情况为"乱序",不是"串行",因此线程池提交任务的方式是异步。
[5]获取任务返回结果的方式是同步提交
import time
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程
def work(num):
print(f'{num}开始')
time.sleep(0.1)
print(f'{num}结束')
return '---'
for i in range(1, 10):
res = pool.submit(work, i) # 往线程池中提交任务(异步提交)
print(res.result()) # 获取任务的返回结果的方式是同步提交,默认返回值是None
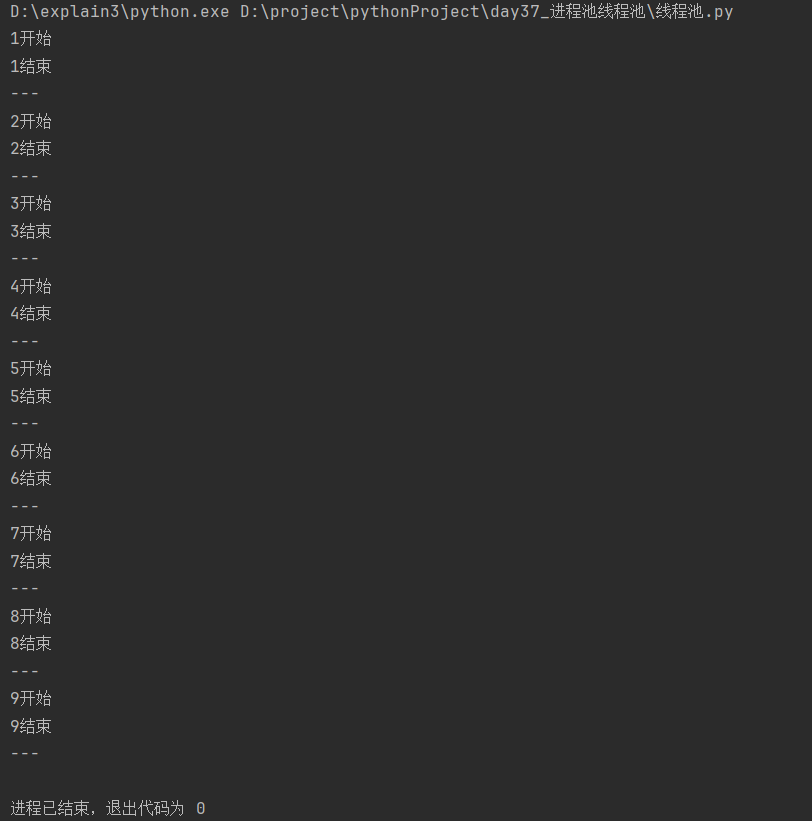
分析:
主进程往线程池异步提交任务,打印的顺序为步骤 [4] 中的"乱序";
在调用result( )函数之后打印顺序变为"串行",因此,获取任务返回结果的方式是同步提交。
[5]异步回调获取对象
为了解决步骤4中获取结果为同步提交而不是异步提交,导致主进程无法同时处理多个任务的问题,
采用异步回调机制add_done_callback( ),只要任务有结果,就会自动调用括号内的函数处理
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程
def work(num):
print(f'{num}开始')
print(f'{num}结束')
return '---'
def func(*args, **kwargs):
print(args, kwargs) # 这里的值与res=pool.submit(work, i)得到的结果是同一个对象,都可以调用result()拿到线程功能函数的返回值
for i in range(1, 10):
pool.submit(work, i).add_done_callback(func)
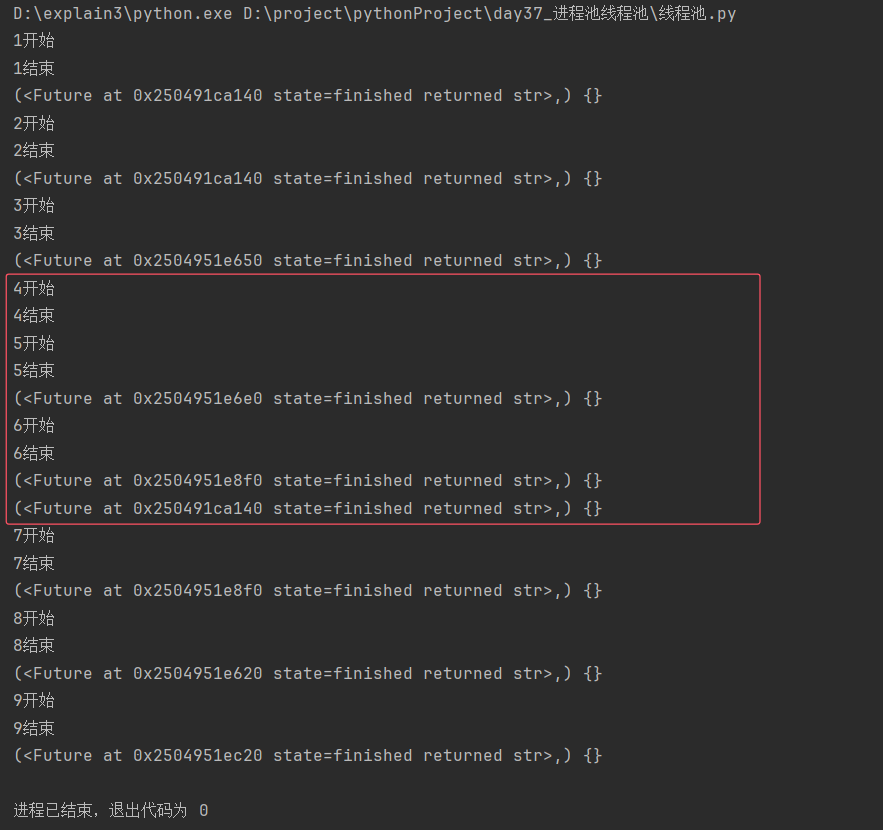
分析:
异步回调得到的值与res=pool.submit(work, i)的值是同一个对象,该对象都可以调用result( )获取线程功能函数的返回值;
提交任务和获取结果都为异步提交,允许主进程同时处理多个任务。
[6]异步回调获取返回值
在步骤5的基础上通过索引取值+调用函数方法获取线程功能函数的返回值
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程
def work(num):
print(f'{num}开始')
print(f'{num}结束')
return '---'
def func(*args, **kwargs):
print(args[0].result())
for i in range(1, 10):
pool.submit(work, i).add_done_callback(func)
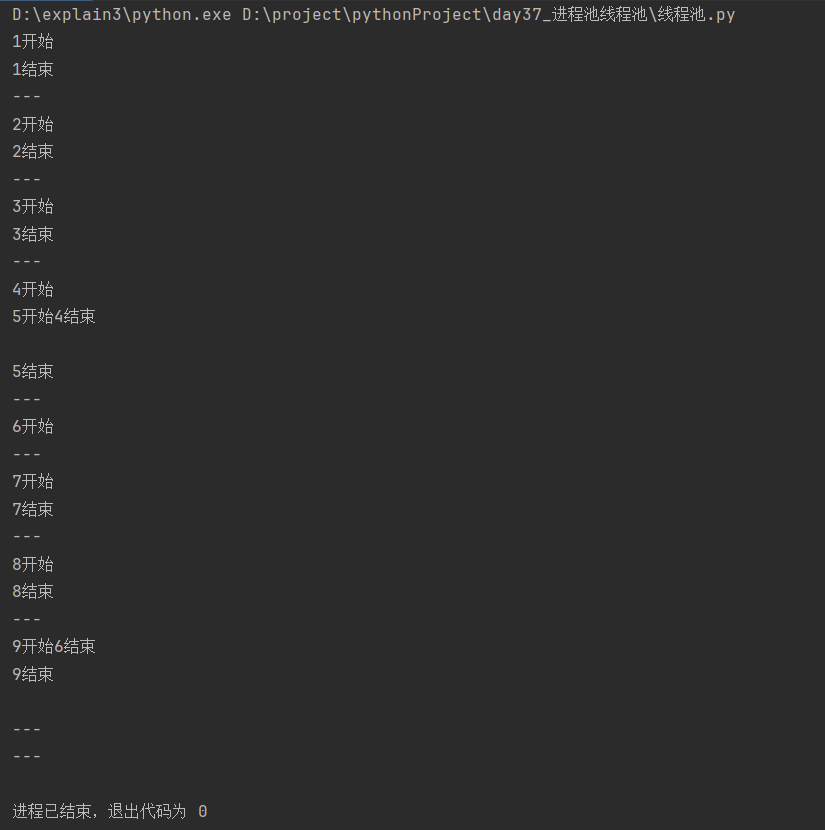
[7]shutdown的用法
shutdown函数用于控制线程池的关闭
shutdown(wait=True)
wait的默认值为True,等待所有线程完成正在运行的任务再关闭线程池
wait如果设置为False,立即关闭线程池,不再接收新任务,不等待正在运行的任务完成
用法类似于join:主进程等子线程结束再结束
没有shutdown
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程
def work(num):
print(f'{num}开始')
print(f'{num}结束')
if __name__ == '__main__':
print('主进程开始')
for i in range(1, 10):
pool.submit(work, i)
print('主进程结束')
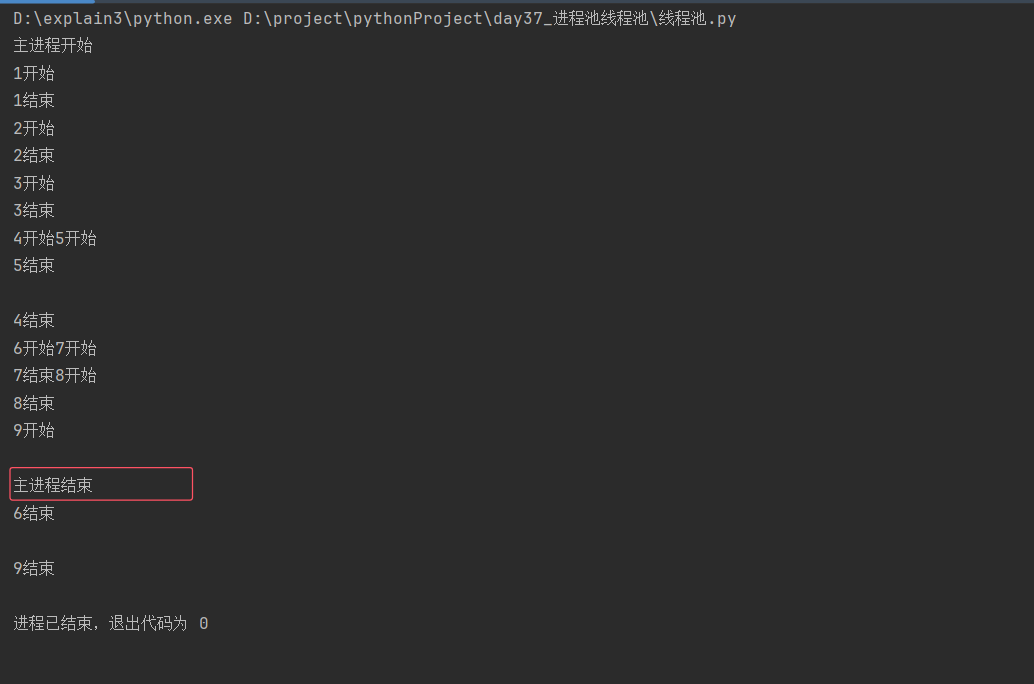
有shutdown
from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor(5) # 代码运行之后立刻产生5个等待工作的线程 def work(num): print(f'{num}开始') print(f'{num}结束') return '---' if __name__ == '__main__': print('主进程开始') for i in range(1, 10): pool.submit(work, i) pool.shutdown() print('主进程结束')
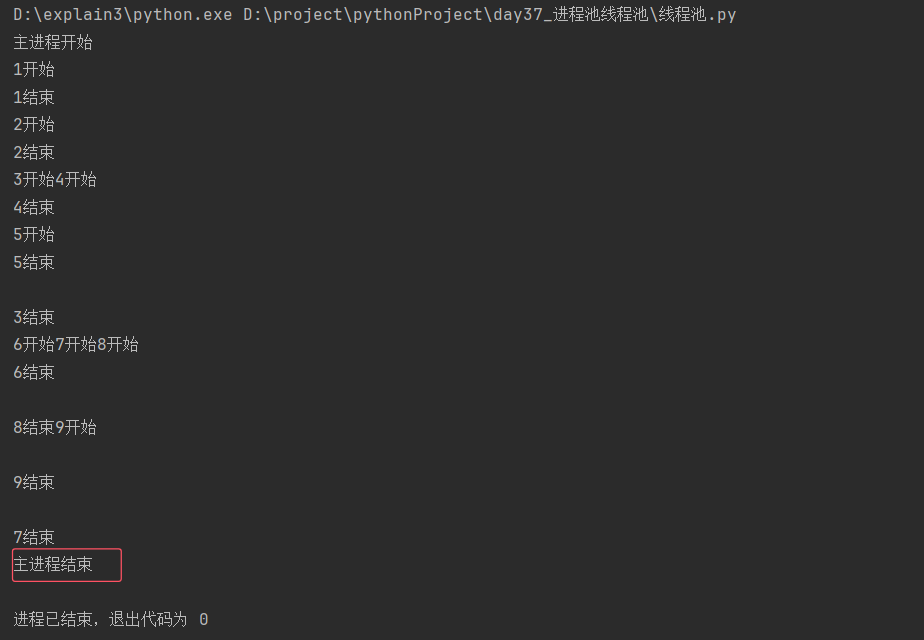
6.2 进程池
[1]概念
创建好固定数量的进程,后续反复使用这些进程
无需频繁创建进程,频繁销毁进程
[2]进程号取值范围个数不会超过指定进程号个数
import os
import time
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(5) # 默认os.cpu_count() or 1
def work(num):
time.sleep(0.001) # sleep的作用是切换进程,防止进程启动速度极快而使用同一个进程号
print(f'{num}开始')
print(f'进程号为:{os.getpid()}')
print(f'{num}结束')
if __name__ == '__main__': # 与产生线程不同,产生进程要放在主程序入口
for i in range(1, 10):
pool.submit(work, i)

分析:
打印结果仍然为"乱序",不是"串行",证明进程池提交任务也是异步提交
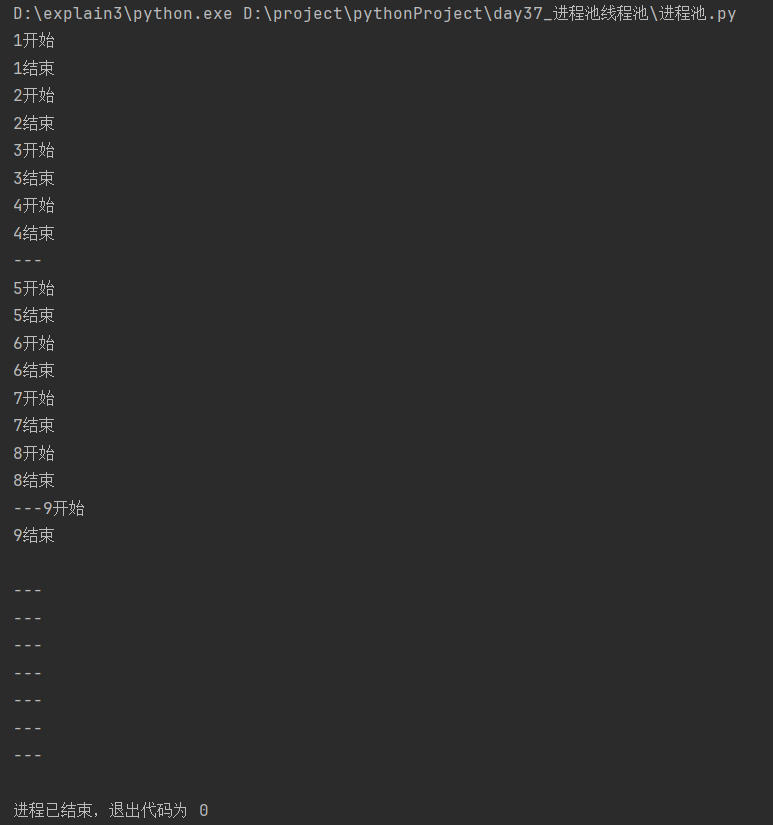
[3]异步回调获取对象
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(5) # 默认os.cpu_count() or 1
def work(num):
print(f'{num}开始')
print(f'{num}结束')
return '---'
def func(*args, **kwargs):
print(args, kwargs)
if __name__ == '__main__': # 与产生线程不同,产生进程要放在主程序入口
for i in range(1, 10):
pool.submit(work, i).add_done_callback(func)
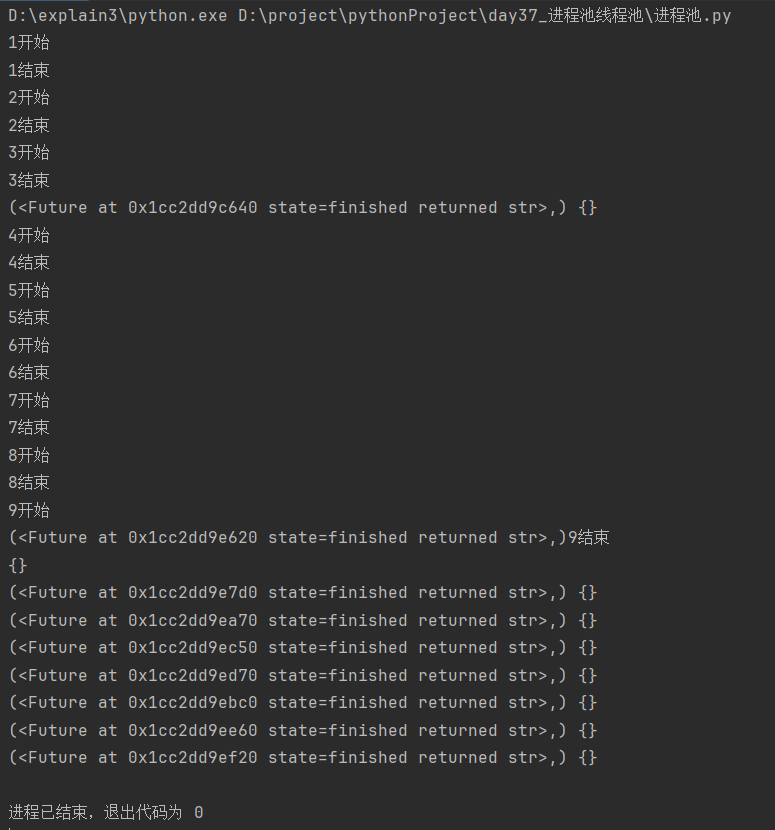
分析:
打印结果为"乱序",证明提交任务和获取结果都为异步提交;允许主进程同时处理多个任务。
[4]异步回调获取返回值
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(5) # 默认os.cpu_count() or 1
def work(num):
print(f'{num}开始')
print(f'{num}结束')
return '---'
def func(*args, **kwargs):
print(args[0].result())
if __name__ == '__main__': # 与产生线程不同,产生进程要放在主程序入口
for i in range(1, 10):
pool.submit(work, i).add_done_callback(func)