28. 多线程、互斥锁
1. 多线程理论
1.1 什么是线程
(1)概念
在操作系统中,每个进程都有一个内存空间地址。
而且默认每个进程都有一个控制线程,即自带一个主线程。
进程是用来把资源集中到一起(进程是一个资源单位,或者称资源集合),线程是CPU上的执行单位。
多线程(即多个控制线程)的概念:一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间。
相当于一个车间内有多条流水线,都共用一个车间的资源。
例如:上海地铁和广州地铁是不同的进程,而广州地铁的13号线是一个线程,广州地铁所有的线路共享广州地铁的资源。
(2)总结
进程:资源单位
启一个进程的含义是在内存中获得一块独立的空间
线程:执行单位
真正被CPU执行的是进程里面的线程
线程指的就是代码的执行过程,执行代码过程所需要的资源都找所在的进程获取
1.2 线程的创建开销
每一个进程都要划分内存中的地址,并且相互独立
线程的创建在进程之内,线程创建的开销更小
1.3 进程与进程、线程与线程之间的关系
不同的进程是竞争关系 例如:不同的程序抢占网速
同一个进程内的线程之间是合作关系
1.4 线程和进程的区别
线程共享创建它的进程的地址空间;进程具有自己的地址空间。
线程可以直接访问其进程的数据段;进程具有其父进程数据段的副本。
线程可以直接与其进程中的其它线程通信;进程必须使用进程间通信与同级进程进行通信。
新线程很容易创建;新进程需要复制父进程。
线程可以对同一进程的线程行使相当大的控制权;进程只能控制子进程。
对主线程的更改(取消、优先级更改等)可能会影响该进程其它线程的行为;对父进程的更改不会影响子进程。
2. 开启线程的两种方式
开启线程不需要在主程序入口下面执行代码,直接书写即可
一般习惯性地将启动命令写在主程序入口下
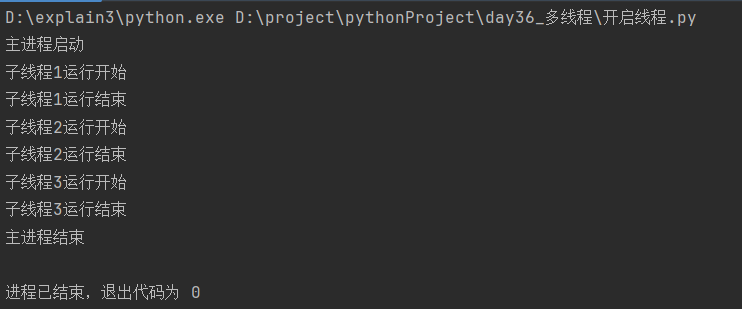
2.1 方式一:直接调用Thread函数
from threading import Thread
# 定义子线程功能函数
def work(name):
print(f'子线程{name}开始运行')
print(f'子线程{name}结束运行')
# 定义产生子线程函数
def create_thread():
st_list = [Thread(target=work, args=(i,)) for i in range(1, 4)]
[st.start() for st in st_list] # 将每一个子线程启动
[st.join() for st in st_list] # 主进程等子线程结束再结束
if __name__ == '__main__':
print('主进程启动')
create_thread()
print('主进程结束')

2.2 方式二:重写Thread的run方法
from threading import Thread
# 继承Thread重写run方法
class NewThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f'子线程{self.name}运行开始')
print(f'子线程{self.name}运行结束')
# 定义产生子线程函数
def create_thread():
st_list = [NewThread(name=f'{i}') for i in range(1, 4)]
[st.start() for st in st_list] # 将每一个子线程启动
[st.join() for st in st_list] # 主进程等子线程结束再结束
if __name__ == '__main__':
print('主进程启动')
create_thread()
print('主进程结束')
2.3 线程调用join函数与进程调用join函数的区别
(1)子线程不调用join无休眠
from threading import Thread
# 定义子线程功能函数
def work(name):
print(f'子线程{name}开始运行')
print(f'子线程{name}结束运行')
# 定义产生子线程函数
def create_thread():
st_list = [Thread(target=work, args=(i,)) for i in range(1, 4)]
[st.start() for st in st_list] # 将每一个子线程启动
if __name__ == '__main__':
print('主进程启动')
create_thread()
print('主进程结束')
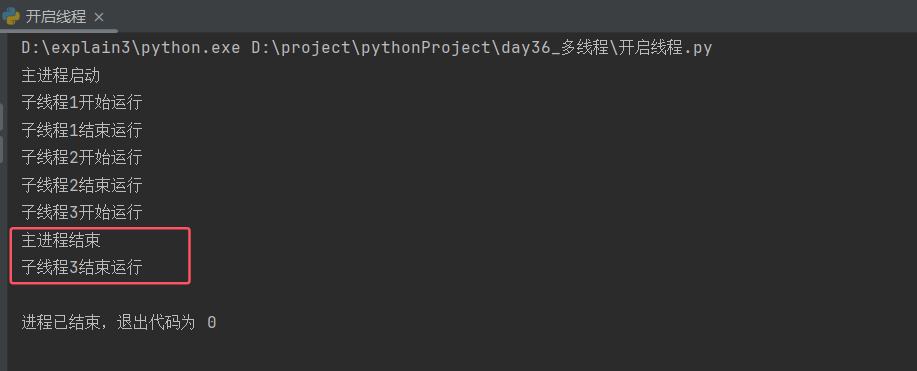
分析:
子线程不调用join与子进程调用join几乎无区别,都是主进程等待子进程(子线程)结束再结束
(2)子线程不调用join但有休眠
import time
from threading import Thread
# 定义子线程功能函数
def work(name):
print(f'子线程{name}开始运行')
time.sleep(0.01)
print(f'子线程{name}结束运行')
# 定义产生子线程函数
def create_thread():
st_list = [Thread(target=work, args=(i,)) for i in range(1, 4)]
[st.start() for st in st_list] # 将每一个子线程启动
if __name__ == '__main__':
print('主进程启动')
create_thread()
print('主进程结束')

分析:
子线程不调用join且有休眠与子进程不调用join有很大区别
子进程不调用join:主进程开始---主进程结束---子进程依次开始---子进程依次结束
子线程不调用join且有休眠:主进程开始---子线程依次开始---主进程结束---子线程依次结束
3. 多线程属性
查看线程名称:current_thread( ).name
统计存活的线程数:active_count( )
import time
import os
from threading import Thread, current_thread, active_count
# 定义子线程功能函数
def work(name):
print(f'子线程{current_thread().name}开始运行, 进程号为{os.getpid()},存活的线程数为{active_count()}')
time.sleep(0.01)
print(f'子线程{current_thread().name}结束运行, 进程号为{os.getpid()},子线程结束前存活的线程数为{active_count()}')
# 定义产生子线程函数
def create_thread():
st_list = [Thread(target=work, args=(i,)) for i in range(1, 4)]
[st.start() for st in st_list] # 将每一个子线程启动
if __name__ == '__main__':
print('主进程启动')
create_thread()
print('主进程结束')

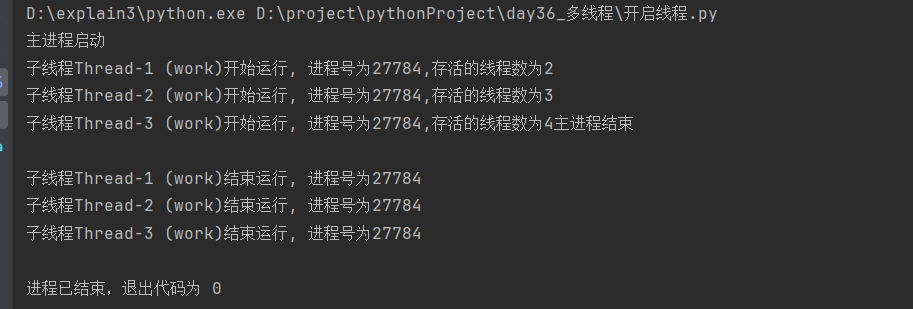
每一个子线程的进程号一致,证明了所有的子线程都是同一个进程开设的
为什么第一次启动子线程时存活的线程数是2?
每个进程都有一个控制线程,即自带一个主线程。
4. 多线程实现TCP服务端并发
# 服务端
from socket import socket, AF_INET, SOCK_STREAM, SOL_SOCKET, SO_REUSEADDR, SOL_SOCKET
from threading import Thread
# 定义子线程功能函数
def work(conn, addr):
while True:
info_from_client = conn.recv(1024)
print(f'客户端{addr}发来的信息为:{info_from_client.decode("utf-8")}')
conn.send(info_from_client.decode("utf-8").upper().encode('utf-8'))
# 定义产生子线程函数
def create_thread(cls, conn, addr):
task = cls(target=work, args=(conn, addr))
task.start()
# 如果这里调用join函数多进程和多线程都无法实现多个客户端与服务端通信,只有第一个客户端可以,之后的会产生阻塞
# 定义主函数
def main():
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 9002))
server.listen(3)
while True:
conn, addr = server.accept()
# 开启多线程
create_thread(cls=Thread, conn=conn, addr=addr)
if __name__ == '__main__':
main()
# 客户端
from socket import socket, AF_INET, SOCK_STREAM
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 9002))
while True:
info_to_server = input('请输入发给服务端的信息:')
client.send(info_to_server.encode('utf-8'))
info_from_server = client.recv(1024)
print(f"客户端返回的信息为:{info_from_server.decode('utf-8')}")

5. 互斥锁
5.1 理论
互斥锁是一种用于多线程编程中控制对共享资源访问的机制。
其作用是保证在同一时刻只有一个线程在访问共享资源,从而避免多个线程同时读写数据造成的问题。
互斥锁的基本原理是在对共享资源进行访问前加锁,使得其它线程无法访问该资源,当访问完成后再解锁,其它线程可以进行访问。
通过这种方式,可以保证同一时间只有一个线程在执行关键代码段,从而保证了数据的安全性。
需要注意的是,互斥锁会带来一些额外的开销。
5.2 子线程与子进程加锁代码示例
子线程加锁
import time
from threading import Thread, Lock
# 定义子线程功能函数
def work(name, lock):
lock.acquire() # 在数据改变之前加锁
print(f'子线程{name}开始运行')
time.sleep(1)
print(f'子线程{name}结束运行')
lock.release() # 结束释放锁
# 定义产生子线程函数
def create_thread(cls):
lock_obj = Lock() # 生成锁对象
task_list = []
for i in range(1, 4):
task = cls(target=work, args=(i, lock_obj))
task_list.append(task)
[task.start() for task in task_list] # 将每一个子线程启动
[task.join() for task in task_list] # 主进程等子线程结束再结束
# 加锁必须开启join,否则会报错
if __name__ == '__main__':
print('主进程开始')
create_thread(cls=Thread)
print('主进程结束')

分析:
如果不加锁,子进程功能函数在有休眠的情况下,代码运行顺序为:主进程开始---子进程依次开始---子进程依次结束---主进程结束
加了锁之后,有休眠,多线程也会变成串行,由原来的子线程依次开始、子线程依次结束,变成了等待上一个子线程结束下一个子线程才能开始
子进程加锁将以上代码中的cls=Thread改为cls=Process,Lock从multiprocessing中导入即可
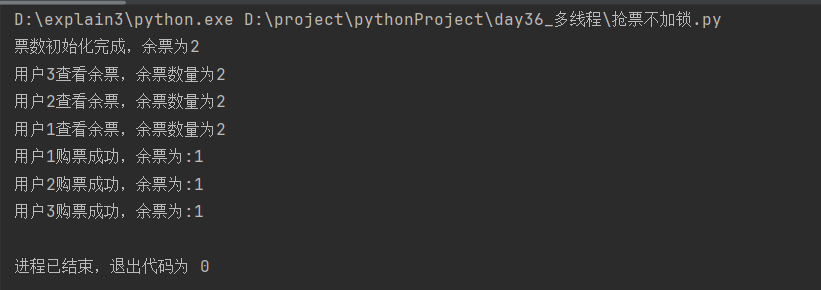
5.3 多进程抢票(不加锁)
import json
import os
import time
from multiprocessing import Process
# 将余票数据存放到本地文件中
db_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'ticket.json')
# 定义产生票数初始化的函数
def init_ticket():
ticket_dict = {'ticket_num': 2}
save_ticket(data=ticket_dict)
print('票数初始化完成,余票为2')
# 定义保存余票数量的函数
def save_ticket(data):
with open(db_path, 'w', encoding='utf-8') as f1:
json.dump(obj=data, fp=f1)
# 定义获取余票数量的函数
def read_ticket():
with open(db_path, 'r', encoding='utf-8') as f2:
ticket_dict = json.load(f2)
return ticket_dict
# 定义子进程功能函数
def buy_ticket(username):
ticket_dict = read_ticket() # 查票
print(f'用户{username}查看余票,余票数量为{ticket_dict.get("ticket_num")}')
time.sleep(0.1) # 模拟买票延迟,在进程与线程中,休眠的作用是切换进程/线程
rest = ticket_dict.get('ticket_num') # 获取数据库中的余票
if rest > 0:
ticket_dict['ticket_num'] -= 1
save_ticket(data=ticket_dict)
print(f'用户{username}购票成功,余票为:{ticket_dict.get("ticket_num")}')
else:
print('余票不足')
# 定义产生子进程函数
def create_process():
sp_list = [Process(target=buy_ticket, args=(f'{i}',)) for i in range(1, 4)]
[sp.start() for sp in sp_list]
[sp.join() for sp in sp_list]
if __name__ == '__main__':
init_ticket()
create_process()
5.4 多进程抢票(加锁)
import json
import os
import time
from multiprocessing import Process, Lock
# 将余票数据存放到本地文件中
db_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'ticket.json')
# 定义产生票数初始化的函数
def init_ticket():
ticket_dict = {'ticket_num': 2}
save_ticket(data=ticket_dict)
print('票数初始化完成,余票为2')
# 定义保存余票数量的函数
def save_ticket(data):
with open(db_path, 'w', encoding='utf-8') as f1:
json.dump(obj=data, fp=f1)
# 定义获取余票数量的函数
def read_ticket():
with open(db_path, 'r', encoding='utf-8') as f2:
ticket_dict = json.load(f2)
return ticket_dict
# 定义子进程功能函数
def buy_ticket(username, lock):
ticket_dict = read_ticket() # 查票
print(f'用户{username}查看余票,余票数量为{ticket_dict.get("ticket_num")}')
time.sleep(0.1) # 模拟买票延迟,在进程与线程中,延迟的作用是切换进程/线程
lock.acquire()
ticket_dict = read_ticket() # 查票
rest = ticket_dict.get('ticket_num') # 获取数据库中的余票
if rest > 0:
ticket_dict['ticket_num'] -= 1
save_ticket(data=ticket_dict)
print(f'用户{username}购票成功')
else:
print('购票失败,余票不足')
lock.release()
# 定义产生子进程函数
def create_process():
lock = Lock() # 生成锁对象
sp_list = [Process(target=buy_ticket, args=(f'{i}', lock)) for i in range(1, 4)]
[sp.start() for sp in sp_list]
[sp.join() for sp in sp_list]
if __name__ == '__main__':
init_ticket()
create_process()
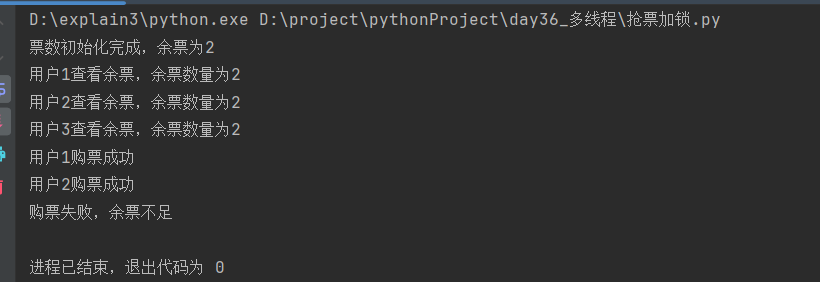
分析:
与5.3中的主要区别是查票的代码增加了一次,买票(数据改变)的过程加上了锁
程序第一个子进程运行到sleep时会休眠,切换到另一个子进程,再运行到sleep时再切换子进程
因此,第一次查票代码的作用是每个子进程查看系统余票(任何进程都没有购票)
子进程3休眠切换到子进程1,子进程1执行休眠之后的代码,再一次进行查票,并且购票,余票数量减少
子进程1购票完成,自动切换到子进程2,此时第二次查票的作用为每个子进程查看之前子进程购票之后的余票(已经有子进程购票,数据库中数量已发生变化)
子进程2购票完成,自动切换到子进程3,此时第二次查票发现已无余票,因此购票失败。
6. 线程的互斥锁
import time
from threading import Thread, Lock
from multiprocessing import Process, Lock
money = 99
def work(lock):
global money
lock.acquire()
temp = money
# time.sleep(0.01) # 进行进程/线程切换
money = temp - 1
lock.release()
def create_spst(cls):
lock = Lock()
print(f'修改之前{money}')
task_list = [cls(target=work, args=(i, lock)) for i in range(99)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后{money}')
if __name__ == '__main__':
create_spst(cls=Thread)
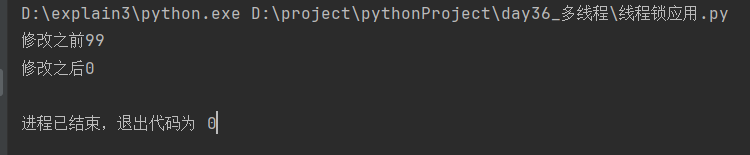
分析:
多线程共享的是同一个资源
给子线程加上锁之后sleep已经起不到切换线程的作用,数字会递减到0
7. 进程与线程其它不加锁的情况
(1)多线程不加锁运行顺序
import time
from threading import Thread
money = 99
def work1():
global money
temp = money
print(f'work1 sleep之前 :>>> {money}')
time.sleep(0.01)
print(f"work 1修改之前 :>>> {money}")
money = temp - 1
print(f'work1 sleep之后 :>>> {money}')
print(f'work1 修改之后 :>>> {money}')
def work2():
global money
temp = money
print(f'work2 修改之前 :>>> {money}')
money = temp + 2
print(f'work2 修改之后:>>> {money}')
def create_thread():
print(f"修改之前 :>>>> {money}")
task1 = Thread(target=work1)
task2 = Thread(target=work2)
task1.start()
task2.start()
task1.join()
task2.join()
print(f"修改之后 :>>>> {money}")
if __name__ == '__main__':
create_thread()

分析:
# 修改之前 :>>>> 99 主进程开始
# work1 sleep之前 :>>> 99 首先运行子线程1,此数据为全局的99
# work2 修改之前 :>>> 99 子线程1运行到sleep休眠,切换到子线程2,此数据为全局的99
# work2 修改之后:>>> 101 子线程2无休眠,继续运行,money为temp(99)+2=101,全局也为101;子线程2运行结束又去运行子线程1休眠后剩下的代码,因为join要等所有子线程结束主进程才能结束
# work 1修改之前 :>>> 101 接上一步全局为101
# work1 sleep之后 :>>> 98 money为temp-1,temp为最开始全局的99没变化,此时money提到全局
# work1 修改之后 :>>> 98 为上一步全局的值
# 修改之后 :>>>> 98 为上一步/上上一步全局的值
(2)多进程不加锁运行顺序
import time
from multiprocessing import Process
money = 99
def work1():
global money
temp = money
print(f'work1 sleep之前 :>>> {money}')
time.sleep(0.01)
print(f"work 1修改之前 :>>> {money}")
money = temp - 1
print(f'work1 sleep之后 :>>> {money}')
print(f'work1 修改之后 :>>> {money}')
def work2():
global money
temp = money
print(f'work2 修改之前 :>>> {money}')
money = temp + 2
print(f'work2 修改之后:>>> {money}')
def create_process():
print(f"修改之前 :>>>> {money}")
task1 = Process(target=work1)
task2 = Process(target=work2)
task1.start()
task2.start()
task1.join()
task2.join()
print(f"修改之后 :>>>> {money}")
if __name__ == '__main__':
create_process()

8. 线程重要知识点补充
8.1 概念
在多线程中,子线程功能函数中的sleep与互斥锁的作用都是切换到另一个线程
如果互斥锁放在子线程功能函数的开头,程序运行到第一个线程的互斥锁时照样会切换到第二个线程,而由于第二个线程拿不到互斥锁,将切换到第三个线程,以此类推,最后还是先运行第一个线程互斥锁里面的代码,再依次运行其它线程互斥锁里面的代码
如果子线程功能函数中互斥锁的前面还有代码,程序运行到第一个线程时先运行互斥锁之前的代码,运行到互斥锁时将切换到第二个线程,先运行第二个线程互斥锁之前的代码,运行到第二个线程的互斥锁切换到第三个线程,以此类推,当所有子线程中互斥锁之前的代码运行完毕,再运行第一个线程互斥锁里面的代码,依次往后面的子线程运行。
8.2 代码示例
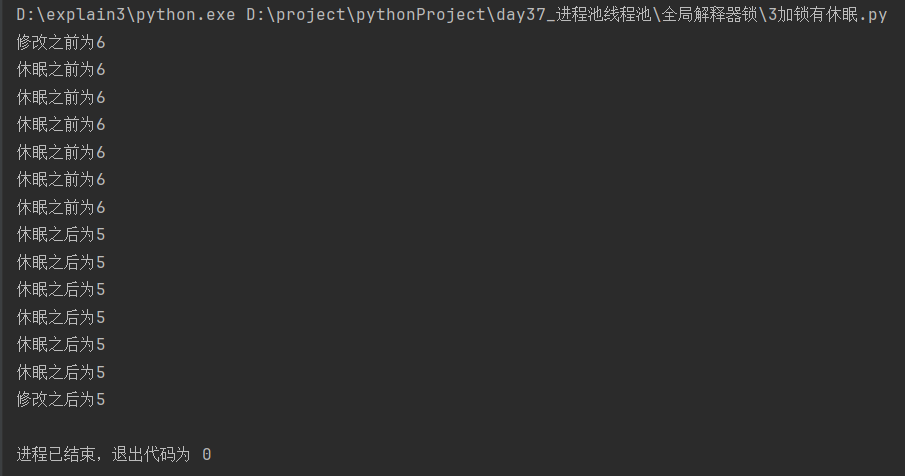
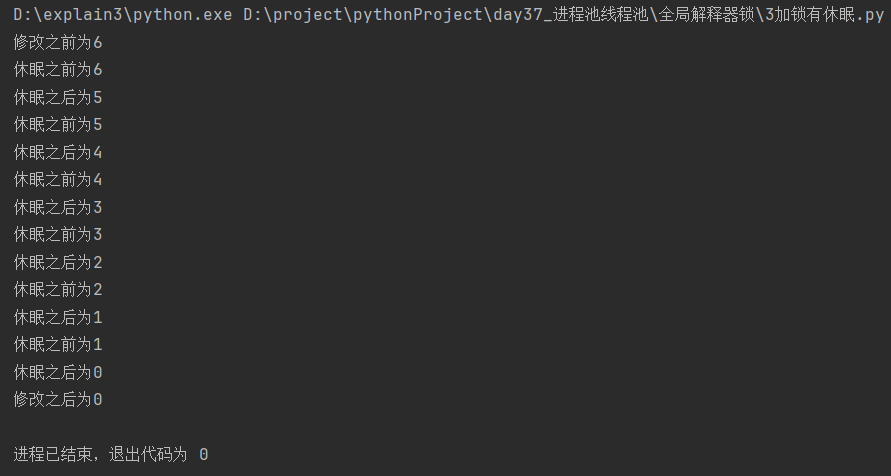
[1]锁放在打印休眠之前
import time
from threading import Thread, Lock
num = 6
def work(lock):
lock.acquire()
global num
temp = num
print(f'休眠之前为{num}')
time.sleep(0.001) # 1.休眠起到切换线程的作用;休眠放在互斥锁里面已经无法切换线程
num = temp - 1
print(f'休眠之后为{num}')
lock.release()
def create_thread():
lock = Lock()
print(f'修改之前为{num}')
task_list = [Thread(target=work, args=(lock,)) for i in range(6)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后为{num}')
if __name__ == '__main__':
create_thread()
[2]锁放在打印休眠之后
import time
from threading import Thread, Lock
num = 6
def work(lock):
global num
temp = num
print(f'休眠之前为{num}')
lock.acquire()
time.sleep(0.001) # 1.休眠起到切换线程的作用;休眠放在互斥锁里面已经无法切换线程
num = temp - 1
print(f'休眠之后为{num}')
lock.release()
def create_thread():
lock = Lock()
print(f'修改之前为{num}')
task_list = [Thread(target=work, args=(lock,)) for i in range(6)]
[task.start() for task in task_list]
[task.join() for task in task_list]
print(f'修改之后为{num}')
if __name__ == '__main__':
create_thread()