27. 守护进程、进程间通信
1. 僵尸进程与孤儿进程
1.1 前言
在unix中,所有的子进程都是由父进程创建的,子进程再创建新的子进程
子进程的结束和父进程的运行是一个异步的过程,即子进程运行完成时,父进程并不知道
当子进程运行完成时,父进程需要调用wait()或waitpid()来获取子进程的运行状态
1.2 僵尸进程
(1)概念
指子进程运行完成后,父进程没有进行管理,子进程的资源没有得到正确的释放从而占用系统资源
子进程仍然存在于进程列表中,但已停止了运行
这些僵尸进程会占用一定的系统内存,并在一定程度上影响系统性能
例如:有时即使关闭了pycharm但是打开任务管理器会发现pycharm进程仍然在运行
(2)解决办法
[1]主动停止父进程
[2]开启的子进程使用join,使用join后主进程会等待所有子进程结束再结束,不会产生僵尸进程
join函数的源码:
def join(self, timeout=None):
'''
Wait until child process terminates
'''
self._check_closed()
assert self._parent_pid == os.getpid(), 'can only join a child process'
assert self._popen is not None, 'can only join a started process'
res = self._popen.wait(timeout)
if res is not None:
_children.discard(self)
join函数调用了wait函数来获取子进程的运行状态,当运行完成时,discard会将子进程所占资源释放
[3]信号机制
http://blog.csdn.net/u010571844/article/details/50419798
from multiprocessing import Process
import os, time
def work():
print(f'子进程{os.getpid()}正在运行')
time.sleep(3)
if __name__ == '__main__':
p = Process(target=work)
p.start()
print(p.pid)
p.join() # 子进程p运行完成后,join函数内部会调用wait函数,通知操作系统回收子进程p的pid
print(p.pid) # 问题:此时能否看到子进程的pid?
print('主程序运行结束')
# 4196
# 子进程4196正在运行
# 4196
# 主程序运行结束
分析:
p.join( )是向操作系统发送通知,p的pid号不需要占用了,回收即可
此时主进程内还可以看到子进程p.pid,但此时的p.pid是一个无意义的pid号
1.3 孤儿进程
指父进程在子进程运行完成前就运行完成了,导致子进程与父进程之间的通信消失
孤儿进程会被init进程接管,init进程会等待子进程的状态信息并释放它所占的系统资源
1.4 危害性
僵尸进程的危害性更大,不会主动关闭子进程,导致占用系统资源
2. 守护进程
2.1 概念
守护进程(daemon)是在操作系统启动时就已经运行,并且一直在后台运行的一类特殊进程。
通常不与用户直接交互,也不接受标准输入和输出,而是在后台执行某种任务或提供某种服务。
守护进程可以由系统启动时自动启动,一直运行在后台,直到系统关闭或被停止;也可以由系统管理员手动启动。
常见的守护进程包括网络服务(如web服务器、邮件服务器、ftp服务器)、日志记录系统(如系统日志服务、应用程序日志服务)等。
守护进程通常在后台运行,不需要与用户交互,并且有较高的权限,因此编写守护进程需要特别注意安全性和稳定性。
2.2 主进程运行结束,子进程未运行结束
from multiprocessing import Process
# 定义子进程功能函数
def work(name):
print(f'子进程{name}开始运行')
print(f'子进程{name}运行结束')
# 定义产生子进程对象函数
def create_process():
p = Process(target=work, args=(1,))
p.start()
if __name__ == '__main__':
print('主进程开始运行')
create_process()
print('主进程运行结束')
主进程开始运行
主进程运行结束
子进程1开始运行
子进程1运行结束
2.3 主进程运行结束,子进程随之结束
2.3.1 正确用法1:在创建子进程时,就在子进程中增加守护进程
[1]主进程休眠,且休眠时间比子进程短from multiprocessing import Process
import time
# 定义子进程功能函数
def work(name):
print(f'子进程{name}开始运行')
time.sleep(3)
print(f'子进程{name}运行结束')
# 定义产生子进程对象函数
def create_process():
p = Process(target=work, args=(1,), daemon=True)
p.start()
if __name__ == '__main__':
print('主进程开始运行')
create_process()
time.sleep(2)
print('主进程运行结束')
主进程开始运行
子进程1开始运行
主进程运行结束
分析:
在没有守护进程的情况下:
如果主进程不休眠,代码执行顺序为:主进程开始---主进程结束---子进程开始---子进程结束
主进程休眠2秒,子进程休眠3秒,主进程休眠时间比子进程短,在主进程休眠期间可以去运行子进程的功能函数,而子进程休眠时间更长,所以主进程结束前打印子进程开始,主进程休眠结束后子进程再休眠结束打印子进程结束,因此代码执行顺序为:主进程开始---子进程开始---主进程结束---子进程结束
在有守护进程的情况下:
在上一步的基础上给子进程加上了守护进程,作用是主进程结束子进程随之结束,因此主进程休眠结束后的子进程结束不再打印
[2]主进程不休眠
from multiprocessing import Process
# 定义子进程功能函数
def work(name):
print(f'子进程{name}开始运行')
print(f'子进程{name}运行结束')
# 定义产生子进程对象函数
def create_process():
p = Process(target=work, args=(1,), daemon=True)
p.start()
if __name__ == '__main__':
print('主进程开始运行')
create_process()
print('主进程运行结束')
# 主进程开始运行
# 主进程运行结束
分析:
没有守护进程的情况下,代码执行顺序依次为:主进程开始---主进程结束---子进程开始---子进程结束
而守护进程的作用是主进程运行结束子进程随之结束,因此代码执行顺序依次为:主进程开始---主进程结束
2.3.2 正确用法2:先创建一个子进程对象,再给子进程对象加守护进程
from multiprocessing import Process
import time
# 定义子进程功能函数
def work(name):
print(f'子进程{name}开始运行')
time.sleep(3)
print(f'子进程{name}运行结束')
# 定义产生子进程对象函数
def create_process():
p = Process(target=work, args=(1,))
p.daemon = True
p.start()
if __name__ == '__main__':
print('主进程开始运行')
create_process()
time.sleep(2)
print('主进程运行结束')
# 主进程开始运行
# 子进程1开始运行
# 主进程运行结束
与上面第一种操作对比可知,daemon写在括号里和括号外效果一致
2.3.3 错误用法:子进程已经开始运行,给子进程加守护进程
from multiprocessing import Process
import time
# 定义子进程功能函数
def work(name):
print(f'子进程{name}开始运行')
time.sleep(3)
print(f'子进程{name}运行结束')
# 定义产生子进程对象函数
def create_process():
p = Process(target=work, args=(1,))
p.start()
p.daemon = True
if __name__ == '__main__':
print('主进程开始运行')
create_process()
time.sleep(2)
print('主进程运行结束')
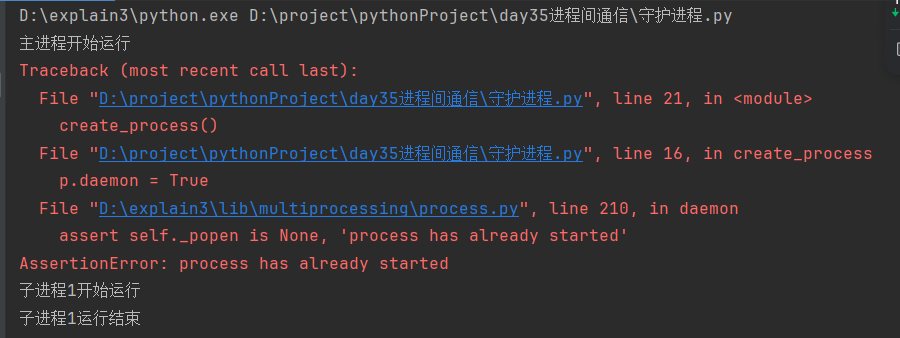
报错原因:进程已经开始无法重置进程状态
3. 进程间通信的理论
3.1 概念
进程间通信(IPC,Inter Process Communication)是指两个或多个进程之间进行信息交互的过程
3.2 如何实现进程间通信
使用消息队列,进程可以将消息放入队列中,另一个进程从队列中取出。
这种通信方式是非阻塞的,发送进程不需要等待接收进程的响应即可继续执行。
multiprocessing模块提供了两种方式来实现消息队列功能:队列、管道
3.3 什么是管道
管道是一种半双工的通信机制,只能在一个方向上进行数据传输
stdin、stdout和stderr是Python中的三个内置文件对象,它们分别代表标准输入、标准输出和标准错误,这些对象可以作为管道使用。
一个进程中使用read方法读取管道内的消息后,其它进程将无法获取该管道内的任何消息。
因此,需要使用锁或其它同步机制来确保多个进程能够正确的访问和修改共享资源。
3.4 什么是队列(管道+锁)
队列是一种线性安全的数据结构,支持在多线程环境中高效地实现生产者-消费者模型
队列的特性是先进先出(FIFO),即先进入队列的数据先被取出。
堆栈的特性是后进先出(LIFO),即后进入队列的数据先被取出。
4. 队列
4.1 创建队列对象
语法:
import queue
q = queue.Queue(maxsize)
maxsize是队列中允许最大项数,省略则无大小限制
4.2 队列操作方法:向队列中传入数据
q.put( )
put方法两个可选参数:blocked和timeout
如果blocked为True(默认值),并且timeout为正数,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,则抛出Queue.Full异常。
如果blocked为False,但该Queue已满,则立即抛出Queue.Full异常。
(1)放入最大项数
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')

(2)超过最大项数
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
q.put('d')

超过最大项数会导致阻塞
(3)超过最大项数时取出超过的数量
如何解决步骤(2)中阻塞问题?从队列中取出一个数据出来就能解决
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
print(q.get())
q.put('d')

(4)设置超时时间
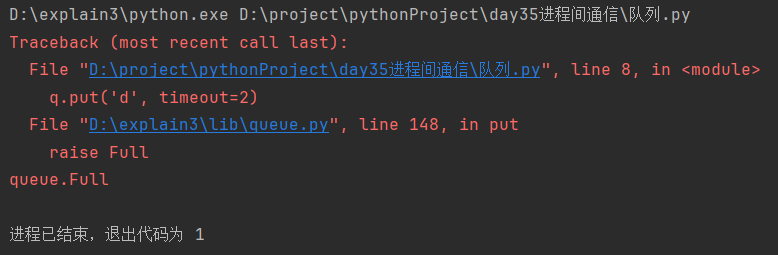
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
q.put('d', timeout=2)
超过最大项数时,超时抛出异常
4.3 队列操作方法:从队列中获取数据
q.get( )
可以从队列中读取并删除一个元素,同样,get方法也有两个可选参数:blocked和timeout
如果blocked为True(默认值),并且timeout为正值,在等待时间内没有获取到任何元素,则抛出Queue.Empty异常。
如果blocked为False,有两种情况,如果Queue有一个值可用,则返回该值;否则,如果队列为空,则抛出Queue.Empty异常。
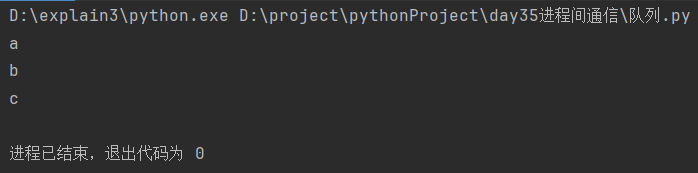
(1)不超过最大项数
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
print(q.get())
print(q.get())
print(q.get())
(2)设置超时时间
超过最大项数时,超时抛出队列为空的异常
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
print(q.get())
print(q.get())
print(q.get())
print(q.get(timeout=1))
4.4 队列的其它操作方法
q.empty( ) 判断队列是否为空
q.full( ) 判断队列是否已满
import queue
q = queue.Queue(3)
q.put('a')
q.put('b')
q.put('c')
print(q.empty(), q.full()) # False True
print(q.get()) # a
print(q.get()) # b
print(q.get()) # c
print(q.empty(), q.full()) # True False
q.get_nowait( ) 同q.get(False)
q.put_nowait( ) 同q.put(False)
5. 使用队列实现进程间通信
5.1 子进程与主进程通信:将打印来自子进程的数据写在join之前
from multiprocessing import Process, Queue
# 定义子进程功能函数
def work(name):
print(f'接收到主进程的数据为:{name.get()}')
name.put('子进程subprocess')
# 定义创建子进程的函数
def create_sp():
q = Queue() # 1.创建一个队列对象用来存储数据
q.put('主进程mainprocess') # 2.向子进程传入数据
p = Process(target=work, args=(q,)) # 3.创建一个子进程
p.start() # 4.启动子进程
print(f'来自子进程的数据为{q.get()}')
p.join() # 5.并行转为串行,主进程等待子进程结束再结束
if __name__ == '__main__':
create_sp()

分析:
在join之前,调度方式为并行,即主进程代码运行完成后再去运行子进程代码
因此,start与join中间的get直接将队列中唯一的数据"主进程mainprocess"取出来,打印的结果为"来自子进程的数据为主进程mainprocess"
代码运行到join时,调度方式由并行改为串行,即主进程等待子进程结束再结束
因此,在主进程完成之前,要去运行子进程代码,而队列中唯一的数据已经被获取,子进程功能函数中的get函数无法获取到数据,就会阻塞
为了实现主进程与子进程之间通信,要将"打印来自子进程的数据"写在join之后
5.2 子进程与主进程通信:将打印来自子进程的数据写在join之后
from multiprocessing import Process, Queue
# 定义子进程功能函数
def work(name):
print(f'来自主进程的数据为:{name.get()}')
name.put('子进程subprocess')
# 定义创建子进程的函数
def create_sp():
q = Queue() # 1.创建一个队列对象用来存储数据
q.put('主进程mainprocess') # 2.向子进程传入数据
p = Process(target=work, args=(q,)) # 3.创建一个子进程
p.start() # 4.启动子进程
p.join() # 5.并行转为串行,主进程等待子进程结束再结束
print(f'来自子进程的数据为:{q.get()}')
if __name__ == '__main__':
create_sp()
分析:
调用join函数,主进程等待子进程结束再结束,子进程中的代码能获取到队列中的数据
5.3 子进程与子进程通信
from multiprocessing import Queue, Process
# 定义第一个子进程功能函数:负责向队列传数据
def produce(q1, name):
print(f'这是子进程{name}')
q1.put('abcdefg')
# 定义第二个子进程功能函数:负责从队列获取数据
def receive(q2, name2):
print(f'这是子进程{name2}')
print(q2.get())
# 定义产生子进程的函数
def create_process():
q = Queue() # 1.生成队列对象
p1 = Process(target=produce, args=(q, 'one')) # 2.生成两个子进程
p2 = Process(target=receive, args=(q, 'two'))
p1.start() # 3.依次启动子进程
p2.start()
p1.join() # 4.并行改串行,主进程等待子进程结束再结束
p2.join()
if __name__ == '__main__':
create_process()
6. 生产者消费者模型
6.1 理论
(1)生产者模型
生产者负责将数据传入到共享队列中
生产者和消费者之间都通过共享这个队列来进行信息的交流
(2)消费者模型
消费者从队列中取出数据或任务
6.2 生产者生产指定数量而消费者一直消费
(1)消费者子进程功能函数循环消费,且无间隔
from multiprocessing import Queue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
print(f'消费者{name2}消费了{food}')
# 定义产生子进程函数
def create_process():
q = Queue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
[sp.join() for sp in subprocess_list] # 5.主进程等子进程结束再结束
if __name__ == '__main__':
create_process()
分析:
生产者依次生产,而第一个消费者子进程启动时直接循环消费,将队列中的数据消费完毕
队列数据消费完毕消费者一直处于get状态,所以产生阻塞
(2)消费者子进程功能函数循环消费,但有时间间隔
import time
from multiprocessing import Queue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
print(f'消费者{name2}消费了{food}')
time.sleep(0.000000001)
# 定义产生子进程函数
def create_process():
q = Queue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
[sp.join() for sp in subprocess_list] # 5.主进程等子进程结束再结束
if __name__ == '__main__':
create_process()
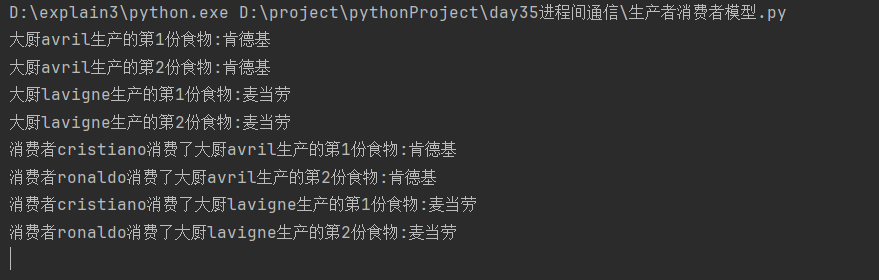
分析:
消费者子进程功能函数循环消费有休眠时,无论休眠时间多短,第一个消费者休眠期间第二个消费者立刻调用子进程功能函数,获取队列中的数据
而第二个消费者一样会进入休眠,第一个消费者在第二个消费者休眠期间进入第二次循环
依次交替运行,直到将队列中的数据获取完毕而阻塞
6.3 生产者添加结束状态
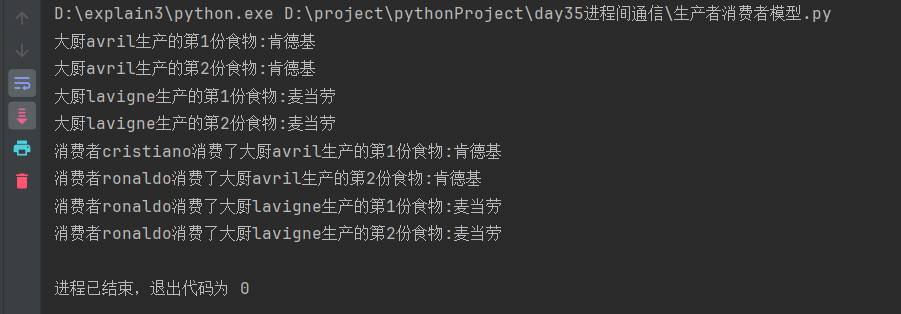
为了解决6.2中的阻塞问题,生产者在生产完数据后再往队列中传入一个结束状态,当消费者从队列中获取到结束状态时,终止循环,避免一直从队列中get,主进程可以正常结束。
import time
from multiprocessing import Queue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
q1.put('finish') # 当生产者生产完所有的数据后添加一个结束状态
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
if food == 'finish': # 从队列中获取到结束状态时,结束循环
break
print(f'消费者{name2}消费了{food}')
time.sleep(1)
# 定义产生子进程函数
def create_process():
q = Queue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
[sp.join() for sp in subprocess_list] # 5.主进程等子进程结束再结束
if __name__ == '__main__':
create_process()
6.4 JoinableQueue模块
(1)概念
JoinableQueue的用法与Queue用法类似,都是用来生成队列对象
JoinableQueue生成的队列对象允许消费者通知生产者队列中的数据或项目被成功处理。
(2)用法
JoinableQueue([maxsize])
maxsize是队列中允许的最大项数,省略则无大小限制
from multiprocessing import JoinableQueue
q = JoinableQueue()
q.task_done( )
消费者使用此方法发出信号,表示q.get( )获得的项目已被处理。
如果调用task_done( )方法的次数大于从队列中删除项目的数量,则引发ValueError异常
q.join( )
生产者调用此方法进行(阻塞),直到队列中所有的项目均被处理,阻塞将持续到队列中的每个项目均调用q.task_done( )方法为止
(3)解读
Join是等待某个任务完成
able可以
Queue队列
JoinableQueue:队列等待任务完成
(4)代码示例
from multiprocessing import JoinableQueue
q = JoinableQueue() # 1.创建队列对象
q.put('a') # 2.向队列中传入数据
q.put('b')
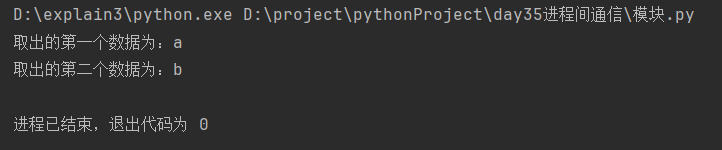
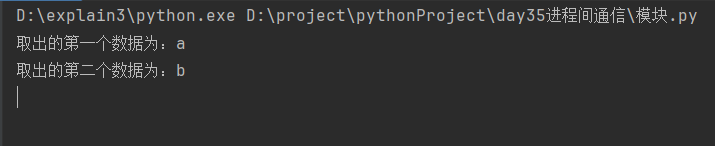
print(f'取出的第一个数据为:{q.get()}') # 3.取出第一个数据
q.task_done() # 4.增加一个状态:表示取走了一个数据
# task_done:通知队列这个数据已经处理完成,需要注意的是,这里的处理完成并不是指任务全部处理完成,而指的是当前取出的数据已经处理完成
# 所以每一个get都需要对应一个task_done,task_done不能超过get的次数,否则会报错
print(f'取出的第二个数据为:{q.get()}') # 5.取出第二个数据
q.task_done() # 6.增加一个状态:表示取走了一个数据
from multiprocessing import JoinableQueue
q = JoinableQueue() # 1.创建队列对象
q.put('a') # 2.向队列中传入数据
q.put('b')
print(f'取出的第一个数据为:{q.get()}') # 3.取出第一个数据
q.task_done() # 4.增加一个状态:表示取走了一个数据
# task_done:通知队列这个数据已经处理完成,需要注意的是,这里的处理完成并不是指任务全部处理完成,而指的是当前取出的数据已经处理完成
# 所以每一个get都需要对应一个task_done,task_done不能超过get的次数,否则会报错
print(f'取出的第二个数据为:{q.get()}') # 5.取出第二个数据
q.task_done() # 6.增加一个状态:表示取走了一个数据
print(f'取出的第三个数据为:{q.get()}') # 7.队列中的数据已被取空,再次get会阻塞
from multiprocessing import JoinableQueue
q = JoinableQueue() # 1.创建队列对象
q.put('a') # 2.向队列中传入数据
q.put('b')
print(f'取出的第一个数据为:{q.get()}') # 3.取出第一个数据
q.task_done() # 4.增加一个状态:表示取走了一个数据
# task_done:通知队列这个数据已经处理完成,需要注意的是,这里的处理完成并不是指任务全部处理完成,而指的是当前取出的数据已经处理完成
# 所以每一个get都需要对应一个task_done,task_done不能超过get的次数,否则会报错
print(f'取出的第二个数据为:{q.get()}') # 5.取出第二个数据
q.task_done() # 6.增加一个状态:表示取走了一个数据
q.task_done() # 7.task_done次数超过队列项目处理次数时会报错
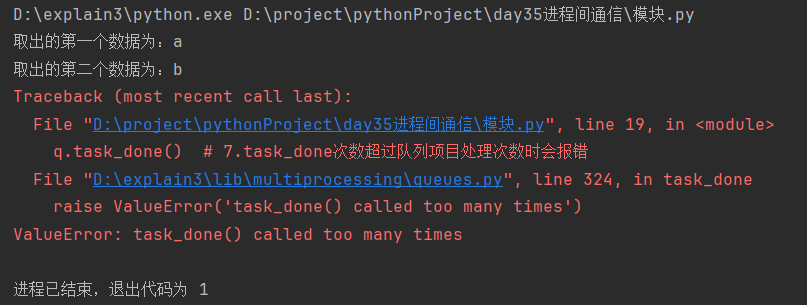
join:等待队列中的数据被处理完毕
from multiprocessing import JoinableQueue
q = JoinableQueue() # 1.创建队列对象
q.put('a') # 2.向队列中传入数据
q.put('b')
print(f'取出的第一个数据为:{q.get()}') # 3.取出第一个数据
q.task_done() # 4.增加一个状态:表示取走了一个数据
q.join() # 5.队列中数据未被处理完毕时,进程无法结束而阻塞
print('进程结束')

from multiprocessing import JoinableQueue
q = JoinableQueue() # 1.创建队列对象
q.put('a') # 2.向队列中传入数据
q.put('b')
print(f'取出的第一个数据为:{q.get()}') # 3.取出第一个数据
q.task_done() # 4.增加一个状态:表示取走了一个数据
print(f'取出的第二个数据为:{q.get()}') # 4.取出第二个数据
q.task_done() # 5.增加一个状态:表示取走了一个数据
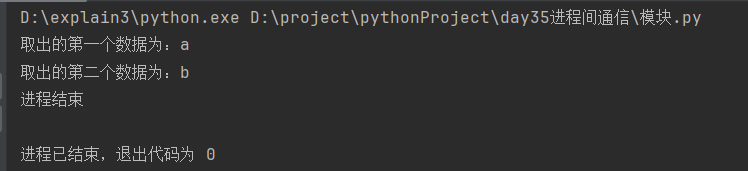
q.join() # 6.join等到队列中数据处理完毕,停止阻塞
print('进程结束')
6.5 使用JoinableQueue模块改写生产者添加结束状态代码
(1)正确用法:生产者调用join,消费者加守护进程
import time
from multiprocessing import JoinableQueue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
q1.join() # join方法等队列中的数据被处理完毕,才能结束阻塞状态
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
print(f'消费者{name2}消费了{food}')
time.sleep(0.001) # 循环+休眠的作用是多个消费者交替取出队列中所有的数据
q2.task_done() # 每从队列中获取一次数据处理一次,给队列中发一个信号
# 定义产生子进程函数
def create_process():
q = JoinableQueue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
consume1.daemon = True # 给消费者子进程加上守护进程,消费者进程随主进程结束而结束
consume2.daemon = True
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
produce1.join() # 5.主进程等子进程结束再结束
produce2.join()
if __name__ == '__main__':
create_process()
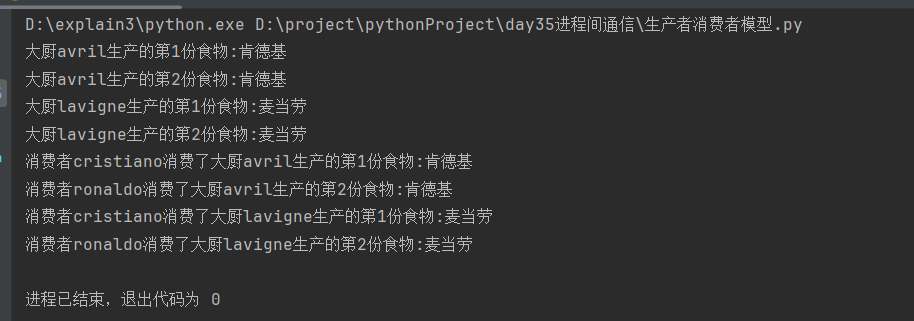
分析:
调用主函数入口中的产生子进程函数, 函数将以极快速度运行到produce1.join之前,此时主进程需要等待生产者子进程结束再结束,程序会暂时阻塞在join;
生产者1、生产者2、消费者1、消费者2子进程依次启动,生产者1和生产者2产生两个数据并传入队列,由于生产者调用了JoinableQueue中的join,需要等待队列中的所有数据处理完成才能结束当前生产者子进程,又处于阻塞状态;
阻塞时消费者子进程得以运行,循环+休眠实现了多个消费者交替取出队列中的数据,并且每取一次数据task_done就给队列发送一个数据处理完成的信号,当队列中的数据处理完毕时,生产者JoinableQueue的join会取消阻塞状态,生产者子进程函数运行完成,主进程中的produce1.join( )与produce2.join( )收到生产者子进程运行结束的信号随之将主进程结束;
此时队列已为空,消费者子进程还在循环地获取队列中的数据,处于阻塞状态,给消费者子进程加上守护进程后,子进程会随主进程结束立即结束,整个程序得以运行完毕而非阻塞态。
(2)错误用法:生产者不调用join方法,消费者不加守护进程
import time
from multiprocessing import JoinableQueue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
q1.join() # join方法等队列中的数据被处理完毕,才能结束阻塞状态
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
print(f'消费者{name2}消费了{food}')
time.sleep(0.001)
q2.task_done() # 每从队列中获取一次数据处理一次,给队列中发一个信号
# 定义产生子进程函数
def create_process():
q = JoinableQueue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
if __name__ == '__main__':
create_process()
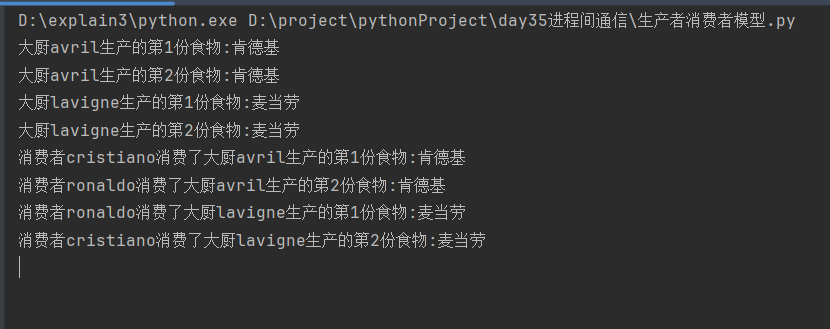
分析:
由于主函数中没有join方法,主进程以极快的速度运行结束,再依次启动各个子进程,队列中处理完成时生产者子进程可以运行结束,而消费者子进程循环获取空的队列导致阻塞
(3)错误用法:消费者加守护进程,生产者和消费者都调用join方法
import time
from multiprocessing import JoinableQueue, Process
# 定义生产者子进程功能函数
def produce(name1, food1, q1):
"""
:param name1:生产者名称
:param food1: 生产的食物
:param q1: 队列
:return:
"""
for i in range(1, 3):
data = f'大厨{name1}生产的第{i}份食物:{food1}' # 生产数据
q1.put(data) # 向队列中添加数据
print(data)
q1.join() # join方法等队列中的数据被处理完毕,才能结束阻塞状态
# 定义消费者子进程功能函数
def consume(name2, q2):
"""
:param name2:消费者名称
:param q2: 队列
:return:
"""
while True:
food = q2.get() # 取出数据
print(f'消费者{name2}消费了{food}')
time.sleep(0.001)
q2.task_done() # 每从队列中获取一次数据处理一次,给队列中发一个信号
# 定义产生子进程函数
def create_process():
q = JoinableQueue() # 1.建立通信媒介---创建队列对象
produce1 = Process(target=produce, args=('avril', '肯德基', q)) # 2.创建生产者模型子进程
produce2 = Process(target=produce, args=('lavigne', '麦当劳', q))
consume1 = Process(target=consume, args=('cristiano', q)) # 3.创建消费者模型子进程
consume2 = Process(target=consume, args=('ronaldo', q))
consume1.daemon = True # 给消费者子进程加上守护进程,消费者进程随主进程结束而结束
consume2.daemon = True
subprocess_list = [produce1, produce2, consume1, consume2]
[sp.start() for sp in subprocess_list] # 4.启动生产者消费者子进程
produce1.join() # 5.主进程等子进程结束再结束
produce2.join()
consume1.join()
consume2.join()
if __name__ == '__main__':
create_process()
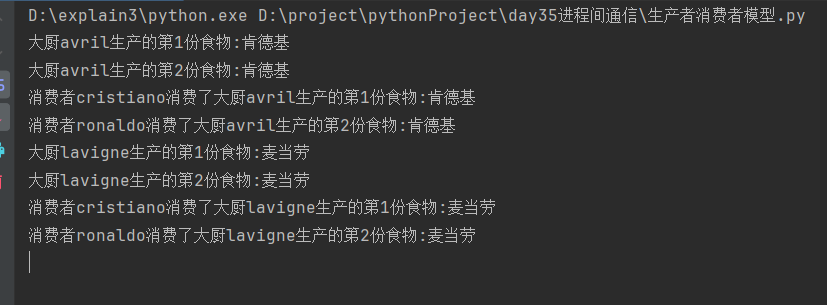
分析:
消费者即加守护进程,又调用join方法是矛盾的
守护进程的含义:子进程等待主进程结束随之结束
join方法含义:主进程等待子进程结束再结束
生产者子进程可以运行结束,消费者调用join方法后会循环获取空队列而导致阻塞
总结:
一个子进程不能既添加守护进程,又调用join方法
7. 进程间通信:管道(了解)
如果生产者中关闭管道的右端,在消费者中就关闭管道的左端
import time
from multiprocessing import Pipe, Process
# 定义生产者子进程函数
def produce(name, conn):
"""
:param name:生产者名称
:param conn: 管道对象
:return:
"""
left_obj, right_obj = conn
right_obj.close() # 将右侧管道关闭
for i in range(1, 3):
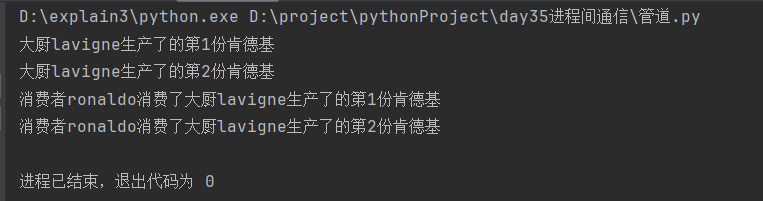
data = f'大厨{name}生产了的第{i}份肯德基' # 生产数据
left_obj.send(data) # 从左侧向管道中传入数据
print(data)
left_obj.close()
# 定义消费者子进程函数
def consume(name, conn):
"""
:param name:消费者名称
:param conn: 管道对象
:return:
"""
left_obj, right_obj = conn
left_obj.close() # 将左侧管道关闭
while True:
try:
food = right_obj.recv() # 取出数据
print(f'消费者{name}消费了{food}')
time.sleep(0.1) # 休眠使多个消费者交替调用消费者子进程函数
except:
right_obj.close()
break
# 定义产生子进程的函数
def create_process():
left_conn, right_conn = Pipe() # 1.建立通信媒介---创建管道
# 2.创建消费者子进程并启动
consume1 = Process(target=consume, args=('ronaldo', (left_conn, right_conn)))
consume1.start()
# 3.创建生产者子进程并启动
producer1 = Process(target=produce, args=('lavigne', (left_conn, right_conn)))
producer1.start()
left_conn.close()
right_conn.close()
consume1.join()
producer1.join()
if __name__ == '__main__':
create_process()