对模型的评估是指对模型泛化能力的评估,主要通过具体的性能度量指标来完成。在对比不同模型的能力时,使用不同的性能度量指标可能会导致不同的评判结果,因此也就意味着,模型的好坏只是相对的,什么样的模型是较好的,不仅取决于数据和算法,还取决于任务需求。本文主要对分类模型的性能度量指标(方法)进行总结。
本文以二分类为例进行介绍。
1.混淆矩阵
1.1 混淆矩阵
对于二分类问题,将模型预测的结果(正例、反例)与实际类别(正例、反例)进行比较,就会产生四种情况:
真正例(true positive, TP):将实际正例预测为正例
假正例(false positive, FP):将实际反例预测为正例
真反例(true negative, TN):将实例反例预测为反例
假反例(false negative, FN):将实际正例预测为反例
TP+FP+TN+FN 为全部样例数,并得到如下矩阵:
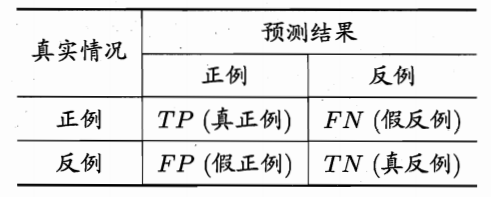
称这个矩阵为混淆矩阵(confusion matrix)。
1.2 错误率
错误率(errorRate)是指预测错误的样例占比,即:
\[errorRate = \frac{FP+FN}{TP+FP+TN+FN}
\]
引用周志华老师书中的例子,错误率就是预测出的结果中,将好瓜预测成了坏瓜、将坏瓜预测成了好瓜的比例。
1.3 正确率(精度)
正确率(acuracy),又称为精度,就是与错误率相对的指标,即1-错误率,
\[accuracy = \frac{TP+TN}{TP+FP+TN+FN}=1-errorRate
\]
仍然是西瓜这个例子,正确率是预测出的结果中,将好瓜预测成了好瓜、将坏瓜预测成了坏瓜的比例。
错误率和正确率是一对从整体上去度量模型预测能力的指标,它无法评估模型对正例(或者反例)的预测能力强弱。这时候就需要使用查准率和查全率。
1.4 查准率(命中率)
查准率(precision),又称为命中率,是指模型预测的正例(或反例)中正确的比例。
\[precision = \frac{TP}{TP+FP}
\]
查准率就是预测出的好瓜中,实际是好瓜的比例。
1.5 查全率(召回率、覆盖率)
查全率(recall),又称为召回率、覆盖率,是指模型预测正确的正例(或反例)占全部实际正例(或反例)的比例。
\[recall = \frac{TP}{TP+FN}
\]
查全率就是预测出的好瓜中,实际为好瓜的数量占全部好瓜的比例。
1.6 F1值
查全率和查准率是一对相矛盾的指标。以西瓜分类为例,为了将更多的好瓜识别出来(即提高查全率),那么就需要去识别更多的西瓜,但是这样就会影响命中率(即查准率)可能使查准率降低;反过来如果希望选出的瓜中真实的好瓜比例尽可能高(即提高查准率),那么就需要尽量选择最优把握的瓜,那么就可能会漏掉不少好瓜,即影响了查全率。
因此,尝试定义查准率(precision)、查全率(recall)的复合指标。
这里介绍常用的复合指标它们的加权调和平均数\(F_1\)以及它的一般形式\(F_{\beta}\):
\[F_1=\frac{2*precision*recall}{precision+recall}
$$\]
F_{\beta}=\frac{(1+{\beta}2)*precision*recall}{{\beta}2*precision+recall}
\[$F_1$认为查全率和查准率重要程度相同,而$F_{\beta}$则使用一个参数$\beta>0$度量二者之间的相对重要程度,$\beta=1$时,$F_{\beta}$即为$F_1$,代表二者重要程度相同;$\beta>1$时,代表查全率更重要;$\beta<1$时,代表查准率更重要。
当一个模型进行了多次训练和预测,就会得到多个混淆矩阵,那又将如何计算这些指标?
有两种思路:
1)先计算各个混淆矩阵的指标,然后计算其平均值;
2)先计算混淆矩阵的平均值,再计算各个指标;
<br/>
##2.PR曲线
模型对测试样本的预测一般会产生一个实值或者概率,同时设定一个**阈值(threshold)**作为正例的判别标准,将预测值与这个阈值进行比较,大于这个阈值的认为是正例,小于这个阈值的认为是反例。对于同一个模型来说,设定不同的阈值,就会产生不同的预测结果。以**查准率(precision)作为纵轴,查全率(recall)作为横轴**,调整这个阈值,就会得到一条变化曲线,称这条曲线为**PR曲线**。
通过PR曲线不仅可以直观地反映模型在不同阈值下的查全率和查准率,而且也可以用来比较两个不同模型的学习性能。
如下是几种PR曲线示例:
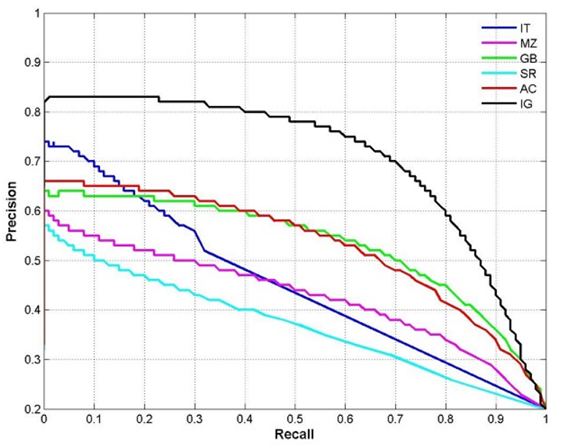
PR曲线有以下几点**特征**:
1)查准率(precision)、查全率(recall)都是0-1之间的指标,因此,横纵轴区间为[0,1];
2)曲线必经原点(0,0),因为当查全率为0时,查准率必然为0;
3)随着查全率的增加,查准率可能下降,也可能上升;
4)曲线不可能经过(1,0),因为当查全率为1时,查准率必然不为0;
5)当一个模型的PR曲线完全包住另一个模型的PR曲线,说明前一个模型的性能优于后一个模型。比如,当查全率相同时,后者的查准率必然大于前者;当查准率相同时,后者的查全率必然大于前者。
6)当一个模型的PR曲线与另一个模型的PR曲线发生交叉时,很难比较二者的性能优劣。有一种简单的比较方式,即做出P=R直线与两条PR曲线相交,交点即为查全率与查准率相等的点,这个点称为**平衡点(Break-Event Point,即BEP)**,比较这个平衡点的高低即可,认为BEP大的曲线,模型性能更好。
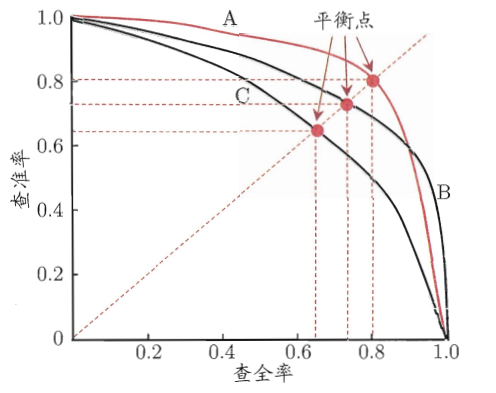
还有一种比较准确的方式,即通过计算PR曲线下方的面积来比较两个模型的性能优劣,称这个面积为AUC-PR(Area Under ROC Curve)。
<br/>
##3.ROC曲线
**ROC曲线(Receiver Operating Characteristic),受试者工作特征曲线**,与PR曲线类似,通过调整正例的判别阈值绘制出来的。不同的是,ROC曲线**以“真正例率(True Positive Rate,TPR)”作为纵轴,以“假正例率(False Positive Rate,TPR)”作为横轴**。TPR和FPR的定义如下:
\]
TPR=\frac{TP}{TP+FN}
\[\]
FPR=\frac{FP}{TN+FP}
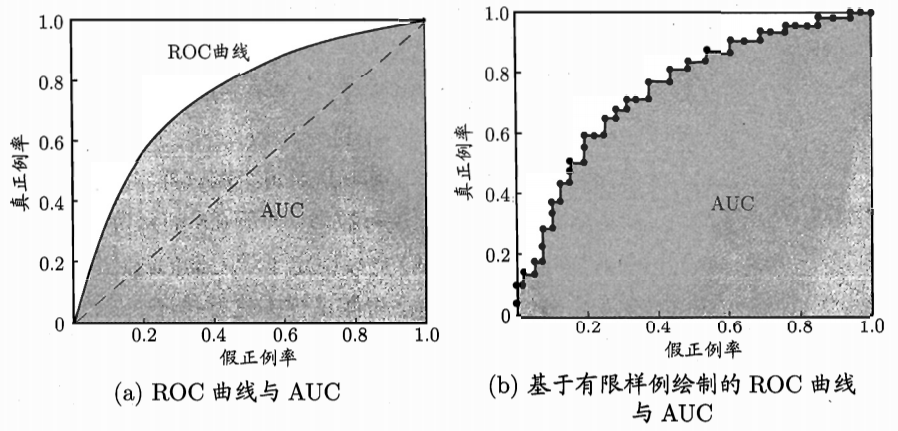
\[如下是几种ROC曲线示例:
ROC曲线的定义来源于医学诊断,如果从“真正例率(True Positive Rate,TPR)”、“假正例率(False Positive Rate,TPR)”上来解释可能不太直观,我们直接回到医学领域理解可能要更容易。
在医学诊断中,我们要识别病人是否有病,以阴阳为例,判断有病,即为找到阳例,判断无病,即为找到阴例。我们的任务是要尽可能地有病的人找出来,也尽量不要把没有病的人诊断为有病,所以要关注两个指标,即真阳性的样例中识别为阳性的比例、真阴性的样例中识别为阳性的比例,也就是上文中提到的TPR和FPR,第一个指标要尽可能大,第二个指标要尽可能小。但是,这两个指标类似于查全率和查准率,是相互制约的,要想识别出更多有病的人,就需要去诊断更多的人,那么就有可能误伤更多没有病的人。以这两个指标为横纵轴,不断调整阳例的识别标准,就绘制出了ROC曲线。
ROC曲线有以下几点**特征**:
1)正对角线,代表随机猜想预测,一半预测正确,一半预测错误。
2)点(0,1)是理想状态,代表全部正例都被预测为正例,同时没有反例被预测为正例。因此,越接近(0,1)点,预测能力越好。
3)如果一个模型的ROC曲线完全包住另一个模型的ROC曲线,说明第一条曲线更接近于(0,1)点,其模型性能更好。
4)如果两个模型的ROC曲线出现相交的情况,同样可以通过曲线下方与坐标轴围成的面积大小来比较二者的性能优劣,面积大的说明性能更好。这个面积指标被称作ROC-AUC(Area Under ROC Curve)。
假设ROC曲线是由点$(x_1,y_1),(x_2,y_2)……(x_m,y_m)$连成折线围成了,那么ROC-AUC的取值为下方各个小梯形面积之和:
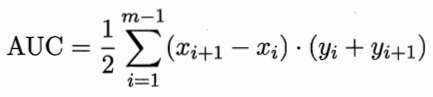
一般来说,我们说的AUC都是指ROC-AUC。
<br/>
##4.参考与感谢
\[1] [统计学习方法](https://book.douban.com/subject/10590856/)
\[2] [机器学习](https://book.douban.com/subject/26708119/)
\[3] [ROC曲线与AUC值](https://www.cnblogs.com/gatherstars/p/6084696.html)
<br/>
<br/>\]


