

启发式搜索
启发式搜索
1. 相关概念
- 在宽度优先和深度优先搜索里面,我们都是根据搜索的顺序依次进行搜索,可以称为盲目搜索,搜索效率非常低。
- 而启发式搜索则大大提高了搜索效率,由这两张图可以看出它们的差别:
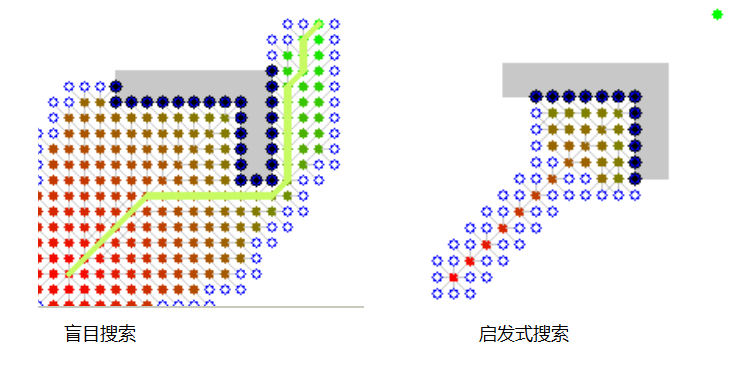
-
什么是启发式搜索(
heuristic search)- 用当前与问题有关的信息作为启发式信息,这些信息是能够提升查找效率以及减少查找次数的。
- 我们定义了一个估价函数
h(x)。h(x)是对当前状态x的一个估计,表示x状态到目标状态的距离。h(x) >= 0;h(x)越小表示x越接近目标状态;- 如果
h(x) ==0,说明达到目标状态。
- 有了启发式信息还不行,还需要起始状态到
x状态所花的代价,我们称为g(x)。g(x)就是我们实际要求解的问题。- 比如在走迷宫问题、八数码问题,我们的
g(x)就是从起点到x位置花的步数 ,h(x)就是与目标状态的曼哈顿距离或者相差的数目;在最短路径中,我们的g(x)就是起点到x点的最短距离,h(x)就是x点到目标结点的最短路或直线距离。
- 令
F(x)=g(x)+h(x),作为我们的搜索依据。- 当
F(x) = g(x)的时候就是一个等代价搜索,完全是按照花了多少代价去搜索。比如bfs,我们每次都是从离得近的层开始搜索,一层一层搜 ;以及dijkstra算法,也是依据每条边的代价开始选择搜索方向。 - 当
F(x) = h(x)的时候就相当于一个贪婪优先搜索。每次都是向最靠近目标的状态靠近。
- 当
- 人们发现,等代价搜索虽然具有完备性,能找到最优解,但是效率太低。贪婪优先搜索不具有完备性,不一定能找到解,最坏的情况下类似于
dfs。 - 这时候,有人提出了
A算法。令F(x) = g(x) + h(x)。(这里的h(x)没有限制)。虽然提高了算法效率,但是不能保证找到最优解,不适合的h(x)定义会导致算法找不到解。不具有完备性和最优性。 - 几年后有人提出了
A*算法。该算法仅仅对A算法进行了小小的修改。并证明了当估价函数满足一定条件,算法一定能找到最优解。估价函数满足一定条件的算法称为A*算法。 - 它的限制条件是
F(x) = g(x) + h(x)。 代价函数g(x) >0;h(x)的值不大于x到目标的实际代价h*(x)。即定义的h(x)是可纳的,是乐观的。
-
怎么理解第二个条件呢?
- 打个比方:你要从
x走到目的地,那么h(x)就是你感觉或者目测大概要走的距离,h*(x)则是你到达目的地后,发现你实际走了的距离。你预想的距离一定是比实际距离短,或者刚好等于实际距离的值。这样我们称你的h(x)是可纳的,是乐观的。 - 不同的估价函数对算法的效率可能产生极大的影响。尤其是
h(x)的选定,比如在接下来的八数码问题中,我们选择了曼哈顿距离之和作为h(x),你也可以选择相差的格子作为h(x),只不过搜索的次数会不同。当 h(x) 越接近 h*(x) ,那么扩展的结点越少!
- 打个比方:你要从
2. A*算法流程
- 将初始节点放入到
open列表中。 - 判断
open列表。如果为空,则搜索失败。如果open列表中存在目标节点,则搜索成功。 - 从
open列表中取出F值最小的节点作为当前节点,并将其加入到close列表中。 - 计算当前节点的相邻的所有可到达节点,生成一组子节点。对于每一个子节点:
- 如果该节点在
close列表中,则丢弃它 - 如果该节点在
open列表中,则检查其通过当前节点计算得到的F值是否更小,如果更小则更新其F值,并将其父节点设置为当前节点。 - 如果该节点不在
open列表中,则将其加入到open列表,并计算F值,设置其父节点为当前节点。
- 如果该节点在
- 转到
2步骤。
3. 图示过程
-
方格左下角为
G(x)为起点到x的步数,右下角为H(x)为x到终点的预估值,这里选的是曼哈顿距离,右上角为F(x)=G(x)+H(x)估价函数。绿色点为起点,黑点为墙,红点为终点。起点相邻四个点进open表,并计算出F值。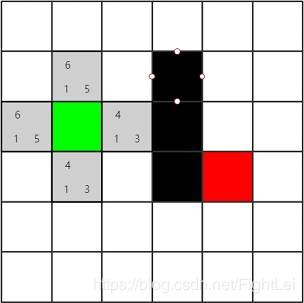
-
继续选择
open列表中F值最小的节点,此时最小节点有两个,都为4。这种情况下选取哪一个都是一样的,不会影响搜索算法的效率。因为启发式相同。这个例子中按照右下左上的顺序选取。先选择绿色节点右边的节点为当前节点,并将其加入close列表。其相邻4个节点中,有1个是黑色节点不可达,绿色节点已经被加入close列表,还剩下上下两个相邻节点,分别计算其F值,并设置他们的父节点为黄色节点。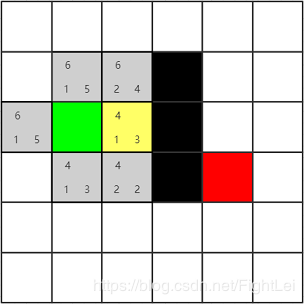
-
此时
open列表中F值最小为4,继续选取下方节点,计算其相邻节点。其右侧是黑色节点,上方1号节点在close列表。下方节点是新扩展的。主要来看下左侧节点,它已经在open列表中了。根据算法我们要重新计算它的F值,按经过2号节点计算G(n) = 3,H(n)不变,所以F(n) = 6相比于原值反而变大了,所以什么也不做。(后面的步骤中重新计算F值都不会更小,不再赘述)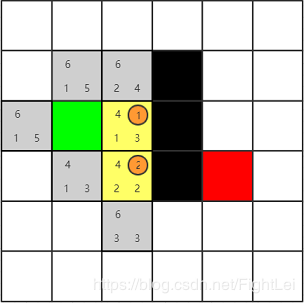
-
此时
open列表中F值最小仍为4,继续选取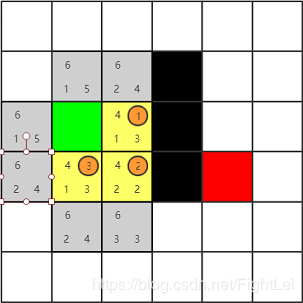
-
此时
open列表中F值最小为6,优先选取下方节点。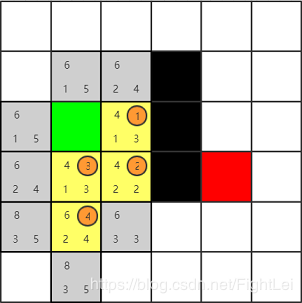
-
此时
open列表中F值最小为6,优先选取右方节点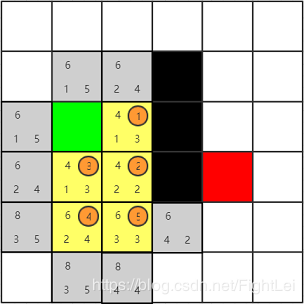
-
此时
open列表中F值最小为6,优先选取右方节点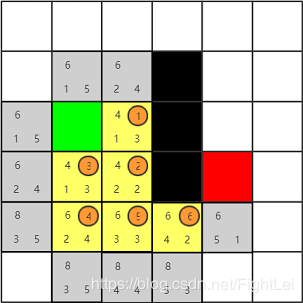
-
此时
open列表中F值最小为6,优先选取右方节点。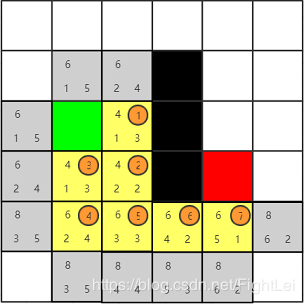
-
此时我们发现红色节点已经被添加到
open列表中,算法结束。从红色节点开始逆推,其父节点为7号,7号父节点为6号,6号父节点为5号,5号父节点为2号(注意这里5号的父节点是2号,因为5号是被2号加入到open列表中的,且一直未被更新),2号父节点为1号,最终得到检索路径为:绿色-1-2-5-6-7-红色。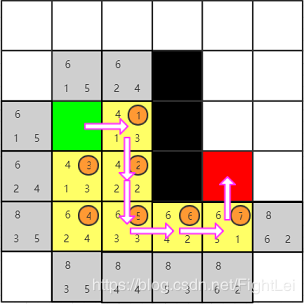
Code
#include <bits/stdc++.h>
const int maxn=100+5;
struct Node{
int x,y,fx;
Node(){}
Node(int a,int b,int c){x=a;y=b;fx=c;}
bool operator <(const Node &a)const{
return fx>a.fx;
}
};
int dx[]={0,-1,0,1},
dy[]={-1,0,1,0};
int a[maxn][maxn],f[maxn],g[maxn][maxn],vis[maxn][maxn];
int n,m,k,sx,sy,ex,ey;
int h(int x,int y){//估价函数,曼哈顿距离
return abs(x-ex)+abs(y-ey);
}
void Astar(){
memset(g,0x3f,sizeof(g));
g[sx][sy]=0;//g函数,起点到当前点的步数也是曼哈顿距离
std::priority_queue<Node> q;
q.push(Node(sx,sy,0));
while(!q.empty()){
Node t=q.top();q.pop();vis[t.x][t.y]=1;//堆顶进入closed列表
for(int i=0;i<4;++i){
int x=t.x+dx[i],y=t.y+dy[i];
if(x<1 || y<1 || x>m || y>n || vis[x][y] || a[x][y])continue;
if(g[x][y]>g[t.x][t.y]+1)//(x,y)到起点的曼哈顿距离变小,可以重复进堆
g[x][y]=g[t.x][t.y]+1;
else continue;//否则(x,y)到起点的距离比当前小且已经在堆,不需要处理
if(x==ex && y==ey){
printf("%d\n",g[x][y]);return;
}
q.push(Node(x,y,g[x][y]+h(x,y)));
}
}
}
void Solve(){
scanf("%d%d%d",&m,&n,&k);
scanf("%d%d%d%d",&sx,&sy,&ex,&ey);
for(int i=1;i<=k;++i){
int x,y;scanf("%d%d",&x,&y);
a[x][y]=1;
}
Astar();
}
int main(){
Solve();
Astar();
return 0;
}
/*
8 7 11
4 1 3 5
2 2
2 3
2 4
2 5
2 6
3 2
3 6
4 2
5 2
6 2
7 6
*/

