

简化OpenCL类
以上一篇《封装OpenCL类》为基础,简化类结构,方便后续使用。
#include <cstdlib>
#include <iostream>
#include <iomanip>
#include <cstring>
#include <cassert>
#include <windows.h>
#define CL_USE_DEPRECATED_OPENCL_1_2_APIS // 定义使用OpenCL 1.2
#include <CL/cl.h>
using namespace std;
// 全局变量
_LARGE_INTEGER g_iSysFrequency,// 系统频率
iStartTestTime; // 开始测试时间
void StartTestTime(void)// 开始测量耗时
{
QueryPerformanceCounter(&iStartTestTime);//开始计时
}
double StopTestTime(int iTimeUnit)// 测量耗时
{
_LARGE_INTEGER iStopTime; double fRetTime;
QueryPerformanceCounter(&iStopTime);// 读停止时间
switch (iTimeUnit)
{
case 0: fRetTime = (double)(iStopTime.QuadPart - iStartTestTime.QuadPart); // ns
break;
case 1: fRetTime = (double)((iStopTime.QuadPart - iStartTestTime.QuadPart) / (g_iSysFrequency.QuadPart / 1000000)); // us
break;
case 2: fRetTime = (double)((iStopTime.QuadPart - iStartTestTime.QuadPart) / (g_iSysFrequency.QuadPart / 1000)); // ms
break;
case 3: fRetTime = (double)((iStopTime.QuadPart - iStartTestTime.QuadPart) / g_iSysFrequency.QuadPart); // S
break;
}
return fRetTime;
}
class COpenCL
{
public:
void Init(void); // 初始化
void Close(void);// 关闭,释放资源
cl_mem CreateBuffer(void *mem, size_t mem_size, cl_mem_flags mem_flag);// 创建缓冲区
void CreateProgramSource(const char *pProgramSource);// 创建异构源代码
void RunGPU(void);// 运行GPU
void RunAsCpu(const float *nums1, const float *nums2, float* sum, const int num);// CPU运行函数
void SetKernelArg(cl_int MemSum, cl_mem Mem_Device);// 输入核参数
void SetupData(void);// 初始化数据
void CheckErr(cl_int Err, const char *pPrintStr);// 错误检查
private:
cl_device_id DevicesID; // 设备ID
cl_context Context = 0; // 设备管理
cl_command_queue CommandQueue = 0; // 命令队列
cl_program Program = 0; // 核对象
cl_kernel RunAsGpu = 0; // 核函数
};
//---------------------------------------------------------------------------
const int Size = 2073600;//一帧高清点数
const int mem_size = sizeof(float) * Size;//计算设备所需存储器
// 主机端
float nums1_h[Size],
nums2_h[Size],
sum_h[Size],
gpu_sum[Size];
// 设备端
cl_mem nums1_d = 0;
cl_mem nums2_d = 0;
cl_mem sum_d = 0;
size_t global_work_size = Size;//设备需要工作项(线程)
// 核函数源码字符串
const char *RunAsGpu_Source =
"__kernel void RunAsGpu_Source(__global const float *nums1, __global const float *nums2, __global float* sum)\n"
"{\n"
"int id = get_global_id(0);\n"
"sum[id] = nums1[id] + nums2[id];\n"
"}\n";
//---------------------------------------------------------------------------
void COpenCL::RunAsCpu(const float *nums1, const float *nums2, float* sum, const int num)// CPU运行函数
{
for (int i = 0; i < num; i++)
{
sum[i] = nums1[i] + nums2[i];
}
}
//---------------------------------------------------------------------------
void COpenCL::CheckErr(cl_int Err, const char *pPrintStr)// 错误检查
{
if (Err != CL_SUCCESS)
{
printf("\n");
printf(pPrintStr);
printf("\n\n");
system("pause");
Close();
exit(1);
}
}
void COpenCL::Init(void)// 初始化
{
cl_int Err;
cl_platform_id PlatformID; // 平台的ID
Err = clGetPlatformIDs(1, &PlatformID, NULL);//获取第一个平台(ID)
CheckErr(Err, "错误:OpenCL获取平台失败!程序即将退出。");
Err = clGetDeviceIDs(PlatformID, CL_DEVICE_TYPE_GPU, 1, &DevicesID, NULL);//获得设备(ID)
CheckErr(Err, "错误:OpenCL获去设备失败!程序即将退出。");
Context = clCreateContext(0, 1, &DevicesID, NULL, NULL, &Err);//创建设备环境
CheckErr(Err, "错误:OpenCL创建设备环境失败!程序即将退出。");
CommandQueue = clCreateCommandQueue(Context, DevicesID, 0, &Err);//创建命令队列
CheckErr(Err, "错误:OpenCL创建命令队列失败!程序即将退出。");
}
void COpenCL::SetupData(void)// 初始化数据
{
for (int i = 0; i < Size; i++)//初始化测试数据
{
nums1_h[i] = nums2_h[i] = (float)i;
}
}
cl_mem COpenCL::CreateBuffer(void *mem, size_t mem_size, cl_mem_flags mem_flag)// 创建缓冲区
{
cl_int Err; cl_mem Ret;
Ret = clCreateBuffer(Context, mem_flag, mem_size, mem, &Err);
CheckErr(Err, "错误:OpenCL创建缓冲区失败!程序即将退出。");
return Ret;
}
void COpenCL::CreateProgramSource(const char *pProgramSource)// 创建异构源代码
{
cl_int Err;
size_t Src_size[] = { strlen(pProgramSource) };//读入源代码数组
Program = clCreateProgramWithSource(Context, 1, &pProgramSource, Src_size, &Err);// 输入设备源程序
CheckErr(Err, "错误:OpenCL输入设备源程序失败!程序即将退出。");
Err = clBuildProgram(Program, 1, &DevicesID, NULL, NULL, NULL);// 编译设备源程序
CheckErr(Err, "错误:OpenCL编译设备源程序失败!程序即将退出。");
RunAsGpu = clCreateKernel(Program, "RunAsGpu_Source", &Err);// 创建核函数
CheckErr(Err, "错误:OpenCL创建核函数 RunAsGpu 失败!程序即将退出。");
}
void COpenCL::SetKernelArg(cl_int MemSum, cl_mem Mem_Device)// 输入核参数
{
cl_int Err;
StartTestTime();
Err = clSetKernelArg(RunAsGpu, MemSum, sizeof(cl_mem), &Mem_Device);
CheckErr(Err, "错误:OpenCL输入设备核函数 RunAsGpu 形参1失败!程序即将退出。");
cout << "CPU 写入设备耗时: " << StopTestTime(1) << " us" << endl;
}
void COpenCL::RunGPU(void)// 运行GPU,并读回结果
{
cl_int Err;
StartTestTime();
Err = clEnqueueNDRangeKernel(CommandQueue, RunAsGpu, 1, NULL, &global_work_size, NULL, 0, NULL, NULL);//运行核函数
CheckErr(Err, "错误:OpenCL核运算失败!程序即将退出。");
cout << "GPU 计算耗时: " << StopTestTime(0) << " ns" << endl;
StartTestTime();
clEnqueueReadBuffer(CommandQueue, sum_d, CL_TRUE, 0, mem_size, gpu_sum, 0, NULL, NULL);//读设备缓冲区
cout << "CPU 读回数据耗时: " << StopTestTime(2) << " ms" << endl;
}
void COpenCL::Close(void)// 关闭,释放资源
{
if (sum_d != 0)
{
clReleaseMemObject(sum_d);
sum_d = 0;
}
if (nums2_d != 0)
{
clReleaseMemObject(nums2_d);
nums2_d = 0;
}
if (nums1_d != 0)
{
clReleaseMemObject(nums1_d);
nums1_d = 0;
}
if (RunAsGpu != 0)
{
clReleaseKernel(RunAsGpu);
RunAsGpu = 0;
}
if (Program != 0)
{
clReleaseProgram(Program);
Program = 0;
}
if (CommandQueue != 0)
{
clReleaseCommandQueue(CommandQueue);
CommandQueue = 0;
}
if (Context != 0)
{
clReleaseContext(Context);
Context = 0;
}
}
//---------------------------------------------------------------------------
int main()
{
COpenCL OpenCL;
QueryPerformanceFrequency(&g_iSysFrequency);//读系统频率
OpenCL.Init();
printf("第一次运行\n\n");
OpenCL.SetupData();
nums1_d = OpenCL.CreateBuffer(nums1_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
nums2_d = OpenCL.CreateBuffer(nums2_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
sum_d = OpenCL.CreateBuffer(NULL, mem_size, CL_MEM_WRITE_ONLY);
OpenCL.CreateProgramSource(RunAsGpu_Source);
//OpenCL.SetKernelArg();// 输入核参数
OpenCL.SetKernelArg(0, nums1_d);// 输入核参数
OpenCL.SetKernelArg(1, nums2_d);
OpenCL.SetKernelArg(2, sum_d);
OpenCL.RunGPU();
printf("\n");
printf("第二次运行\n\n");
OpenCL.SetupData();
nums1_d = OpenCL.CreateBuffer(nums1_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
nums2_d = OpenCL.CreateBuffer(nums2_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
sum_d = OpenCL.CreateBuffer(NULL, mem_size, CL_MEM_WRITE_ONLY);
//OpenCL.CreateProgramSource(RunAsGpu_Source);
OpenCL.SetKernelArg(0, nums1_d);// 输入核参数
OpenCL.SetKernelArg(1, nums2_d);
OpenCL.SetKernelArg(2, sum_d);
OpenCL.RunGPU();
printf("\n");
printf("第三次运行\n\n");
OpenCL.SetupData();
nums1_d = OpenCL.CreateBuffer(nums1_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
nums2_d = OpenCL.CreateBuffer(nums2_h, mem_size, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR);
sum_d = OpenCL.CreateBuffer(NULL, mem_size, CL_MEM_WRITE_ONLY);
//OpenCL.CreateProgramSource(RunAsGpu_Source);
OpenCL.SetKernelArg(0, nums1_d);// 输入核参数
OpenCL.SetKernelArg(1, nums2_d);
OpenCL.SetKernelArg(2, sum_d);
OpenCL.RunGPU();
printf("\n");
StartTestTime();
OpenCL.RunAsCpu(nums1_h, nums2_h, sum_h, Size);// 运行CPU函数
cout << "\nCPU 计算耗时:" << StopTestTime(2) << " ms" << endl;
if (memcmp(sum_h, gpu_sum, Size * sizeof(float)) == 0)// 比较结果,数值比较
{
printf("\n比较GPU和CPU计算数值正确。\n");
}
else
{
printf("\n错误:比较GPU和CPU计算数值错误!程序即将退出。\n");
system("pause");
exit(1);//退出
}
OpenCL.Close();// 关闭,释放资源
// 殿后处理
printf("\n运行成功!\n\n");
system("pause");
}
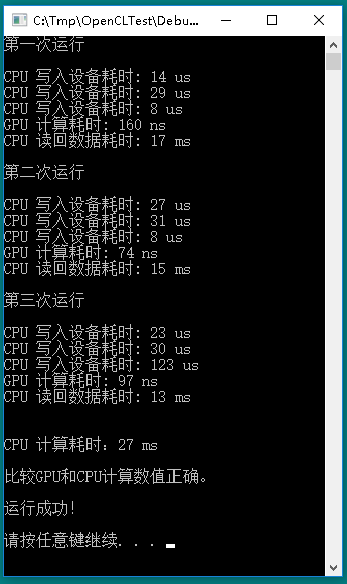
从结果可以看出,第一次运行略慢,后续加快。读回结果异常慢,也有逐步加快的趋势。第一次需要建立、编译“核”函数,后续不需要。
在 Microsoft Visual C++ 2017 控制台调试通过。
