第24章 录放音频
第24章 录放音频
1. 录制音频
录制音频程序默认的执行时间是15秒,需要更长时间可以在main函数调用对应函数时修改传入的参数,也就是调用record_audio函数的第二个参数:duration。
import os
from media.media import * #导入media模块,用于初始化vb buffer
from media.pyaudio import * #导入pyaudio模块,用于采集和播放音频
import media.wave as wave #导入wav模块,用于保存和加载wav音频文件
def exit_check():
try:
os.exitpoint()
except KeyboardInterrupt as e:
print("user stop: ", e)
return True
return False
def record_audio(filename, duration):
CHUNK = int(44100/25) #设置音频chunk值
FORMAT = paInt16 #设置采样精度
CHANNELS = 1 #设置声道数
RATE = 44100 #设置采样率
try:
p = PyAudio()
p.initialize(CHUNK) #初始化PyAudio对象
MediaManager.init() #vb buffer初始化
#创建音频输入流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
#采集音频数据并存入列表
for i in range(0, int(RATE / CHUNK * duration)):
data = stream.read()
frames.append(data)
if exit_check():
break
#将列表中的数据保存到wav文件中
wf = wave.open(filename, 'wb') #创建wav 文件
wf.set_channels(CHANNELS) #设置wav 声道数
wf.set_sampwidth(p.get_sample_size(FORMAT)) #设置wav 采样精度
wf.set_framerate(RATE) #设置wav 采样率
wf.write_frames(b''.join(frames)) #存储wav音频数据
wf.close() #关闭wav文件
except BaseException as e:
print(f"Exception {e}")
finally:
stream.stop_stream() #停止采集音频数据
stream.close()#关闭音频输入流
p.terminate()#释放音频对象
MediaManager.deinit() #释放vb buffer
if __name__ == "__main__":
os.exitpoint(os.EXITPOINT_ENABLE)
print("record_audio sample start")
record_audio('/data/test.wav', 15) #录制wav文件
print("record_audio sample done")
在程序开始时,首先用 PyAudio 库来处理音频输入和输出。
FORMAT = paInt16表示采样精度为16位,通常用于大多数音频采集。CHANNELS = 1表示单声道录音,因为我们庐山派板子上只有一个麦克风,所以无法录制双声道的音频文件,CHANNELS = 1时会把单声道的声音同时填充进左右两个声道。RATE = 44100是目前常见的音频采样率,就是说每秒采集44100次。
在接下来的 for 循环中,程序不断地从麦克风输入流中读取音频数据,将其保存在 frames 列表中。最后,使用 wave 模块将这些数据保存成 .wav 格式的音频文件。
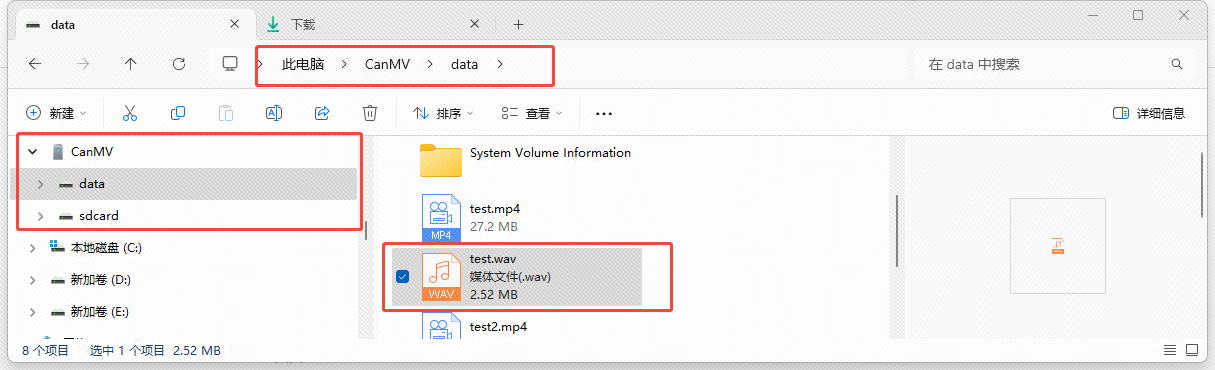
执行以上程序,当程序结束后,会在/data目录中出现一个test.wav文件,你可以把他复制到电脑中播放:
2. 播放音频
import os
from media.media import * #导入media模块,用于初始化vb buffer
from media.pyaudio import * #导入pyaudio模块,用于采集和播放音频
import media.wave as wave #导入wav模块,用于保存和加载wav音频文件
def exit_check():
try:
os.exitpoint()
except KeyboardInterrupt as e:
print("user stop: ", e)
return True
return False
def play_audio(filename):
try:
wf = wave.open(filename, 'rb')#打开wav文件
CHUNK = int(wf.get_framerate()/25)#设置音频chunk值
p = PyAudio()
p.initialize(CHUNK) #初始化PyAudio对象
MediaManager.init() #vb buffer初始化
#创建音频输出流,设置的音频参数均为wave中获取到的参数
stream = p.open(format=p.get_format_from_width(wf.get_sampwidth()),
channels=wf.get_channels(),
rate=wf.get_framerate(),
output=True,frames_per_buffer=CHUNK)
data = wf.read_frames(CHUNK)#从wav文件中读取数一帧数据
while data:
stream.write(data) #将帧数据写入到音频输出流中
data = wf.read_frames(CHUNK) #从wav文件中读取数一帧数据
if exit_check():
break
except BaseException as e:
print(f"Exception {e}")
finally:
stream.stop_stream() #停止音频输出流
stream.close()#关闭音频输出流
p.terminate()#释放音频对象
wf.close()#关闭wav文件
MediaManager.deinit() #释放vb buffer
if __name__ == "__main__":
os.exitpoint(os.EXITPOINT_ENABLE)
print("play_audio sample start")
play_audio('/data/test.wav') #播放wav文件
print("play_audio sample done")
这个程序首先使用wave.open() 打开录制好的 .wav 文件。然后通过 p.open() 创建音频输出流,传入音频格式、声道数、采样率等参数。最后就是不断的从wav文件中来读取数据,通过 stream.write(data) 方法将音频数据写入输出流,实现播放。
在运行以上程序前,首先要确保/data这个目录中有这个文件,如果没有就需要先运行record_audio来录制音频;其二就是要确保你已经插入(只要有铜片露出就是没有完整插入)3.5mm耳机并带到了你的耳机上。
3. 同时录播
录制声音的同时在3.5mm耳机口同时播放音频,要记得先正确插入你的耳机并带到耳朵上,就相当于是用我们的耳朵去听庐山拍上的麦克风听到的声音。
下面程序的默认执行时间是15秒,需要更长时间可以在main函数调用对应函数时修改传入的参数,也就是调用loop_audio函数时的参数:duration。
import os
from media.media import * #导入media模块,用于初始化vb buffer
from media.pyaudio import * #导入pyaudio模块,用于采集和播放音频
import media.wave as wave #导入wav模块,用于保存和加载wav音频文件
def exit_check():
try:
os.exitpoint()
except KeyboardInterrupt as e:
print("user stop: ", e)
return True
return False
def loop_audio(duration):
CHUNK = int(44100/25)#设置音频chunck
FORMAT = paInt16 #设置音频采样精度
CHANNELS = 1 #设置音频声道数
RATE = 44100 #设置音频采样率
try:
p = PyAudio()
p.initialize(CHUNK)#初始化PyAudio对象
MediaManager.init() #vb buffer初始化
#创建音频输入流
input_stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
#创建音频输出流
output_stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
output=True,frames_per_buffer=CHUNK)
#从音频输入流中获取数据写入到音频输出流中
for i in range(0, int(RATE / CHUNK * duration)):
output_stream.write(input_stream.read())
if exit_check():
break
except BaseException as e:
print(f"Exception {e}")
finally:
input_stream.stop_stream()#停止音频输入流
output_stream.stop_stream()#停止音频输出流
input_stream.close() #关闭音频输入流
output_stream.close() #关闭音频输出流
p.terminate() #释放音频对象
MediaManager.deinit() #释放vb buffer
if __name__ == "__main__":
os.exitpoint(os.EXITPOINT_ENABLE)
print("loop_audio sample start")
loop_audio(15) #采集音频并输出
print("loop_audio sample done")
这个程序是开头两个程序的结合,创建两个音频流,一个用于输入(录制),一个用于输出(播放)。将采集到的音频数据实时传递到输出流进行播放。
input_stream 是音频输入流;output_stream 是音频输出流,他们就第四个参数不一致,input=True表示是输入流,output=True表示是输出流。frames_per_buffer=CHUNK指定了每次读取或写入的数据块大小。
下面的for循环,就是从音频输入流中获取数据写入到音频输出流中是该程序的核心部分。通过input_stream.read()从音频输入流中读取音频数据,并通过output_stream.write()将读取的数据写入到音频输出流中,实现音频的实时播放。
循环的次数是根据duration(音频的持续时间)和CHUNK(数据块大小)计算的。每次读取的数据块大小为CHUNK,音频总持续时间为duration秒。
在IDE中实际运行起来后,你可以对着板子上的麦克风说话,如果之前连接正常的话,你就能听到耳机传来你自己的声音了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号