
[Python][爬虫]利用OCR技术识别图形验证码
ocr图片识别通常可以利用tesserocr模块,将图片中内容识别出来并转换为text并输出
Tesserocr是python的一个OCR识别库,是对tesseract做的一层python APT封装。在安装Tesserocr前,需要先安装tesseract
tessrtact文件:
https://digi.bib.uni-mannheim.de/tesseract/
python安装tessocr: 下载对应的.whl文件安装(这个包pip方式容易出错)
tesseract 与对应的tesserocr:
https://github.com/simonflueckiger/tesserocr-windows_build/releases
实现代码如下:
from PIL import Image
import tesserocr
#tesserocr识别图片的2种方法
img = Image.open("code.jpg")
verify_code1 = tesserocr.image_to_text(img)
#print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")
#print(verify_code2)
但是,当图片中干扰部分较多,如验证码内多余的线条干扰图片的识别,识别后的内容不是很准确,就需要做一下处理,如转灰度,二值化操作。
可以利用Image对象的convert()方法,传入“L”,将图片转为灰度图像;传入1则对图像进行二值处理(默认阈值127)
原验证码:

img = Image.open("code.jpg")
img_L = img.convert("L")
img_L.show()

也可以自己设置阈值
threshold = 100 #设置二值的阈值100
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
#point()返回给定查找表对应的图像像素值的拷贝,变量table为图像的每个通道设置256个值,为输出图像指定一个新的模式,模式为“L”和“P”的图像进一步转换为模式为“1”的图像
image = img_L.point(table, "1")
image.show()
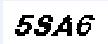
img_1 = tesserocr.image_to_text(image)
print(img_1)
>>5SA6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号