
[原创]Python+selenium+Chrome爬取excel网站
最近要写一个水利网站的爬虫脚本,将网页中2个excel的数据,爬到一个excel表里
恩,就是下面的网页截图,一左一右两张表。左边日期控件,输入对应日期查询相应日期的数据。
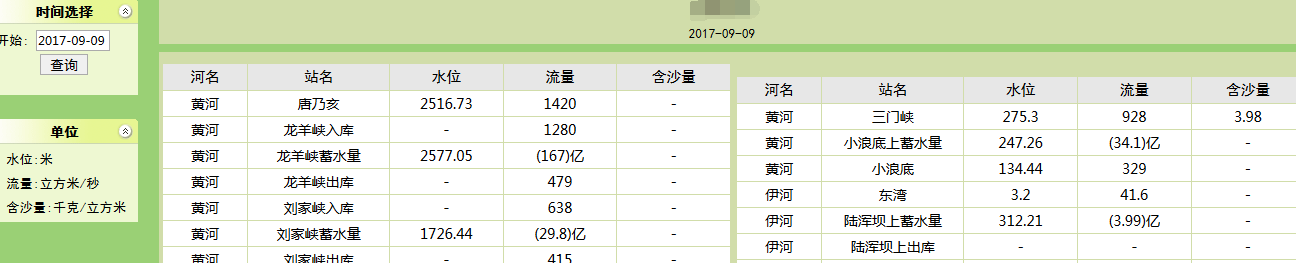
看到这么简单的网页,真是好开心,分分钟就给你数据
用requests库,发post请求,使用fiddler或者Burpsuite抓包测试都正常,但是用脚本,始终获取不到page_source
终于,发现日期输入框的属性是 readonly,于是果断使用selenium删除掉readonly属性,然后获取page_source,用BeautifulSoup处理数据




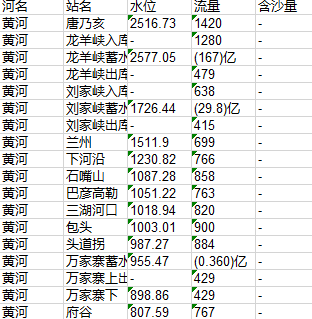
同样方法把右表的数据提取出来,最后结果截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号