
Python+selenium+PhantomJS爬取异步加载的网站
一个网站的爬虫脚本,在调试的时候发现问题:
脚本跑:content-type用text/xml 可以post成功,但post中body的内容没有生效,所有的响应都是当前日期;用application,post不成功(即没有返回数据)
工具发:content-type用text/xml 可以post成功,但post中body的内容没有生效,所有的响应都是当前日期;用application,post成功且body中日期修改有效
即用脚本根本就没有收到返回的数据,但是用工具fiddler或者Burpsuite都可以正常的使用查看包的内容,很奇怪。直到后来才发现,原来我爬的这个网站是动态的==
动态网页(参考百度百科:https://baike.baidu.com/item/%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050)
--------------------------------------------------------------------
所谓的动态网页,是指跟静态网页相对的一种网页编程技术。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
值得强调的是,不要将动态网页和页面内容是否有动感混为一谈。这里说的动态网页,与网页上的各种动画、滚动字幕等视觉上的动态效果没有直接关系,动态网页也可以是纯文字内容的,也可以是包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,只要是采用了动态网站技术生成的网页都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理。因此,从这个意义上来讲,凡是结合了HTML以外的高级程序设计语言和数据库技术进行的网页编程技术生成的网页都是动态网页。
--------------------------------------------------------------------
也可以解释为,动态网页没有执行javascript,仅仅使用data = response.read()得到的静态html是没有所想爬取内容
在网上查到用Python 解决这个问题只有两种途径:直接从JavaScript 代码里采集内容,或者用Python 的第三方库运行JavaScript,直接采集你在浏览器里看到的页面。曾经用selenium做过web自动化,就用第二种(其实selenium+PhantomJS就是模拟浏览器访问url,然后将动态网页所有内容转化为静态html返回,这样速度会很慢)
安装PhantomJS :第三方库下载并放到python\scripts下
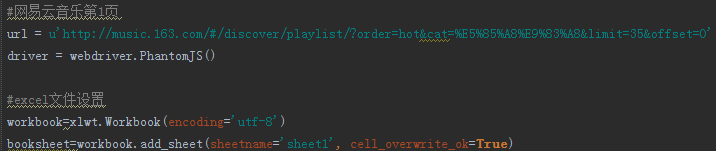
爬虫网易歌单中,播放量超过1000万的歌曲名及链接,保存至excel
Chrome 按F12查看网页源代码
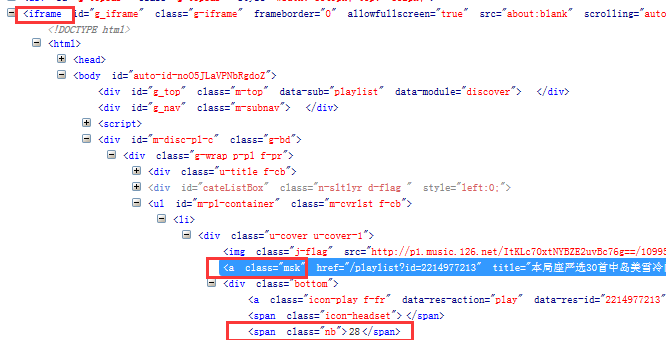
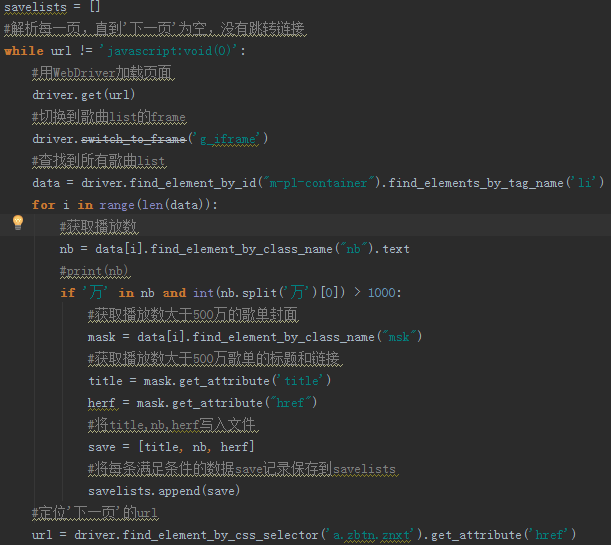
页面查元素,先切换frame到id='g_iframe'
播放量nb及对应的标题和链接
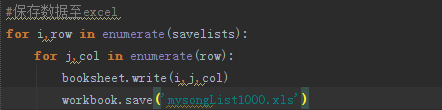
mysongList1000.xls结果截图
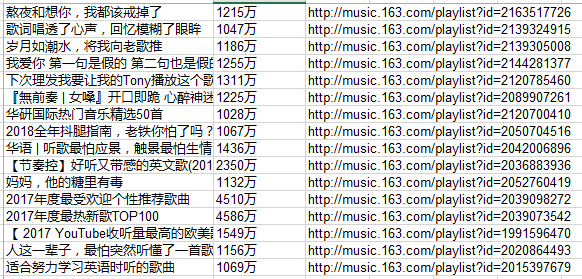
灵感来源:http://www.cnblogs.com/tuohai666/p/8718107.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号