

Verse Scansion Program
Problem:
Scansion involves discerning stressed and unstressed syllables in English, posing challenges for non-native speakers, including myself, my schoolmates, and beginners. While dictionaries and online resources can identify syllables and stresses for individual words, existing programs merely count the number of syllables in a line, neglecting specific syllable identification and stress patterns. The tedious process of determining the meter necessitates frequent word look-ups for their syllables and stresses. Consequently, I sought to develop a program that automatically outputs the scansion for each line of poetry, streamlining the entire process.
The Python module Prosodic can perform scansion, representing stressed and unstressed syllables with upper- and lower-case letters. However, it removes all spaces and punctuation, except apostrophes, in its output. Additionally, given Prosodic’s specialized nature, users must familiarize themselves with its array of functions to utilize it effectively.
Method:
First, my program dissects each line into individual words, capturing any associated punctuation at the end of each word. I then implemented a web crawler to extract the root form of each word from Merriam-Webster.com and retrieve its syllabic structure, including its primary stress, from HowManySyllables.com. Recognizing potential discrepancies between a word and its root form, I re-analyzed the original word, accommodating any variations and appending suffixes and punctuation. Additionally, by acknowledging frequent metrical patterns such as the prevalence of iambs, the program proposes scansion for each line.
Result:
My program offers three output “modes”: the first divides words into syllables, the second highlights the primary stress of each word in bold, and the third generates suggestions for each line's scansion. Unlike the Prosodic module, all three modes maintain the text's original format, preserving spaces, punctuation and upper- and lower-case letters, thus facilitating user readability and analysis.
What I did:
Problems with Prosodic:
1. the original format is lost:

• upper- and lower- case represent stressed and unstressed syllables
• no spaces and no punctuation (apart from apostrophes)
2. the user has to learn how to use its various functions

My improved program:
Three “modes” available using different tools:
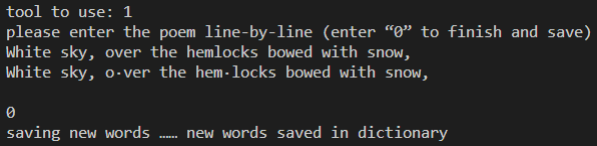
Tool 1 (determining the syllables in the first line of “The Buck in the Snow” by Edna St. Vincent Millay):
Tool 2 (showing the syllables and primary stresses in this line from “Who in One Lifetime” by Muriel Rukeyser):

Tool 3 (giving the suggested scansion of the same line by considering common metrical patterns such as iambs):

My code in Python:
from bs4 import BeautifulSoup
import requests # web crawler
import openpyxl # Python and Excel
workbook = openpyxl.load_workbook('C:\\Users\\hongz\\Desktop\\CS\\wordata.xlsx')
worksheet = workbook.active # a database of words and their syllables
wordict = dict() # a currently-empty dictionary
def Dictionary(): # to set up the dictionary
print("loading dictionary ……", end = " ")
for i in range(2, worksheet.max_row + 1):
row = worksheet[i] # the word and its syllables
text = [syl.value for syl in row if syl.value is not None]
word = text[0]; text.remove(word)
wordict[word] = text # the word's syllables
print("dictionary loaded"); print("")
def Showords():
print("words in the dictionary")
for word in wordict.keys():
print(word, end = ", ")
print("") # to check the dictionary
def Showordict():
print("dictionary of base words and their syllables")
for i in range(2, worksheet.max_row + 1):
word = worksheet.cell(row = i, column = 1).value
print(word, end = ": "); print(wordict[word])
print("") # to check the dictionary is updated
def Store(bswd): # to process the base word
response = requests.get('https://www.howmanysyllables.com/syllables/' + bswd)
soup = BeautifulSoup(response.text, 'html.parser')
# print(soup.prettify()) # to format the page's source code
meter = soup.find('span',{'class':'no_b'})
if meter != None: # howmanysyllables.com has its meter
meter = str(meter) # to convert the meter from class Tag to class string
meter = meter.replace('<span class="no_b" data-nosnippet="">', "")
meter = meter.replace('</span>', "") # delete other HTML tags
meter = meter.replace('<span class="Ans_st">', "*") # “*”s mark stressed syllables
syllables = meter.split("-") # to split the text into a list of the word's syllables
else: # the word is a monosyllable or howmanysyllables.com does not have its meter
meter = soup.find_all('span',class_='Answer_Red')[1]
syllables = meter.text.split("-") # a list of the word's syllables
# monosyllables, apart from common exceptions such as "the", are usually stressed
if len(syllables) == 1: syllables[0] = "*" + syllables[0]
wordict[bswd] = syllables # to store the word's syllables in the dictionary
# to add this word and its syllables to the spreadsheet
wdsyl = syllables.copy(); wdsyl.insert(0, bswd); worksheet.append(wdsyl)
'''
the NLTK module's Porter stemmer and Snowball stemmer have some inaccuacies,
and lemmatization is slower than directly crawling Merriam-Webster.com
'''
def Simplify(word):
# to get the base word of each word (e.g. "flowers" → "flower")
# in Merriam-Webster.com, single/plural and and upper/lower-case do not matter
response = requests.get('https://www.merriam-webster.com/dictionary/' + word)
soup = BeautifulSoup(response.text, 'html.parser')
bswd = soup.find('meta',property='og:aria-text')['content'].split()[4]
if wordict.get(bswd) == None: Store(bswd) # to create a new datum
return bswd # to compare with the original word (to find its suffix)
def Verse(line):
# to adjust spaces adjacent to hyphens and dashes
for bar in ["-", "–", "—"]:
line = line.replace(" " + bar, bar)
line = line.replace(bar, bar + " ")
# print(line) # to check that this works
text = line.split() # to store the still largely original formatting of the line
syllables = list() # a currently-empty list of syllables
for i in range(0, len(text)):
word = text[i] # to compare the processed word with the original word
# to wipe off any suffixes with apostrophes
apostrophes = ["n't", "'ve", "'re", "'ll", "'t", "'s", "'m", "'d"]
for apos in apostrophes: word = word.replace(apos, "")
punc = "" # to store punctuation marks at the end
while word[-1] in (""",;.:'"(-)[–]{—}?!"""):
punc = word[-1] + punc; word = word[:-1] # ; print(punc)
# to wipe off punctuation marks at the front
if word[0] in ("""('"[{"""): word = word[1:]
bswd = Simplify(word) # to find the base word
# print(bswd, end = ": "); print(wordict[bswd])
char_index = 0 # a pointer to iterate through the word's characters
for j in range(0, len(wordict[bswd])):
bsyl = wordict[bswd][j] # a syllable
if bsyl[0] == "*": syl = "*"
else: # this syllable is not stressed
syl = word[char_index]
char_index = char_index + 1
for k in range(1, len(bsyl)):
syl = syl + word[char_index]
char_index = char_index + 1
syllables.append(syl)
if text[i][0] in ("""('"[{"""):
suffix = text[i][len(bswd) + 1:len(text[i]) - len(punc)]
if wordict[bswd][0][0] == "*":
syllables[-len(wordict[bswd])] = "*" + text[i][0] + syllables[-len(wordict[bswd])][1:]
else:
syllables[-len(wordict[bswd])] = text[i][0] + syllables[-len(wordict[bswd])]
else: suffix = text[i][len(bswd):len(text[i]) - len(punc)]
if len(suffix) == 0 or suffix[0] == "'":
syllables[-1] = syllables[-1] + suffix
elif suffix[-1] in ["d", "s"]:
syllables[-1] = syllables[-1] + suffix
else:
syllables.append(suffix)
if text[i][-1] in ["-", "–", "—"]:
syllables[-1] = syllables[-1] + punc
else:
syllables[-1] = syllables[-1] + punc + " "
# print(syllables)
return syllables
def Sylscan(syllables): # only showing syllables
for i in range(0, len(syllables)):
if syllables[i][0] == "*":
syl = syllables[i][1:]
else:
syl = syllables[i]
if syl[-1] in [" ", "-", "–", "—"]:
print(syl, end = "")
else:
print(syl + "·", end = "")
def Scansion(syllables): # showing syllables and stresses
for i in range(0, len(syllables)):
if syllables[i][0] == "*":
syl = syllables[i][1:]
syl = "\033[1m" + syl + "\033[0m"
else:
syl = syllables[i]
if syllables[i][-1] in [" ", "-", "–", "—"]:
print(syl, end = "")
else:
print(syl + "·", end = "")
def Write(syllable, stress):
syl = syllable # to remove the “*”
if syl[0] == "*": syl = syl[1:]
if stress == 0: # this syllable is stressed
syl = "\033[1m" + syl + "\033[0m"
if syllable[-1] in [" ", "-", "–", "—"]:
print(syl, end = "")
else:
print(syl + "·", end = "")
def Suggestions(syls):
# list of indices of stressed syllables
stressed = list()
for i in range(0, len(syls)):
if syls[i][0] == "*":
stressed.append(i)
if len(stressed) == 0:
stressed.append(1)
for i in range(0, stressed[0]):
Write(syls[i], (i + stressed[0]) % 2)
for j in range(1, len(stressed)):
for i in range(stressed[j-1], stressed[j]):
Write(syls[i], (i + stressed[j-1]) % 2)
for i in range (stressed[-1], len(syls)):
Write(syls[i], (i + stressed[-1]) % 2)
# main 函数
Dictionary() # ; Showords()
print("Directions for using this scansion tool: please enter")
print(" — “1” to show only the syllables of each word in the poem")
print(" — “2” to show the syllables and the primary stress of each word")
print(" — “3” to show the suggested scansion (with syllables and stresses)")
tool = str(input("tool to use: ")) # to input which tool to use
if tool != "1" and tool != "2" and tool != "3":
tool = "2"; print("sorry, using tool 2 as the default")
print("please enter the poem line-by-line (enter “0” to finish and save)")
line = str(input())
while(line != "0"):
syllables = Verse(line)
if tool == "1": Sylscan(syllables)
if tool == "2": Scansion(syllables)
if tool == "3": Suggestions(syllables)
print(""); print("")
# Showordict()
line = str(input())
print("saving new words ……", end = " ")
workbook.save(filename = 'wordata.xlsx')
print("new words saved in dictionary")
'''
the Prosodic module is pretty good, but it has several disadvantages:
1. it represents stressed syllables using capital letters
2. it deletes all spaces and punctuation apart from apostrophes in its output
3. the user has to be familiar with the various functions used
in contrast, my program has a much simpler user interface and
its output is more legible, preserving most of the original formatting
'''
Poems analysed
I ran this program on set poems from the AL English Literature 9695 anthology, leading to this analysis.
Example: "The Road" by Nancy Fotheringham Cato
I made the ris·ing moon go back
be·hind the shoul·der·ing hill,
I raced a·long the east·ern track
till time it·self stood still.
The stars swarmed on be·hind the trees,
but I sped fast at they,
I could have made the sun a·rise,
and night turn back to day.
And like a long black car·pet
be·hind the wheels, the night
un·rolled a·cross the coun·try·side,
but all a·head was bright.
The fence-posts whizzed a·long wires
like days that fly too fast,
and tel·e·phone poles loomed up like years
and slipped in·to the past.
And light and move·ment, sky and road
and life and time were one,
while through the night I rushed and sped,
I drove to·wards the sun.
