

研发规范系列(四):架构分层
前言:好的架构分层,可以让代码逻辑更清晰,扩展性更好;架构分层统一,与团队来说,也可以使得团队内代码更容易理解和维护;
系列文章:
研发规范系列(一):故障复盘
研发规范系列(二):方案评审
研发规范系列(三):日志上报
研发规范系列(四):架构分层
研发规范系列(五):监控上报
研发规范系列(六):代码Review
研发规范系列(七):API设计
研发规范系列(八):服务发布
研发规范系列(九):数据库变更
研发规范系列(十):方案设计
规范开源仓库地址:https://github.com/xianfengyi/specifications
为何要分层?
为什么要架构分层了?
一把梭,虽然快,但是随着业务越来越复杂,会出现逻辑不清晰,模块相互依赖,代码扩展性差等问题,因此需要架构分层;
那为什么又要架构分层规范了?
架构分层有很多种方案,如果团队中成员A用X分层方案,成员B用Y分层方案,那么就不统一,修改维护以及理解成本都回比较高
业界架构分层
经典三层架构
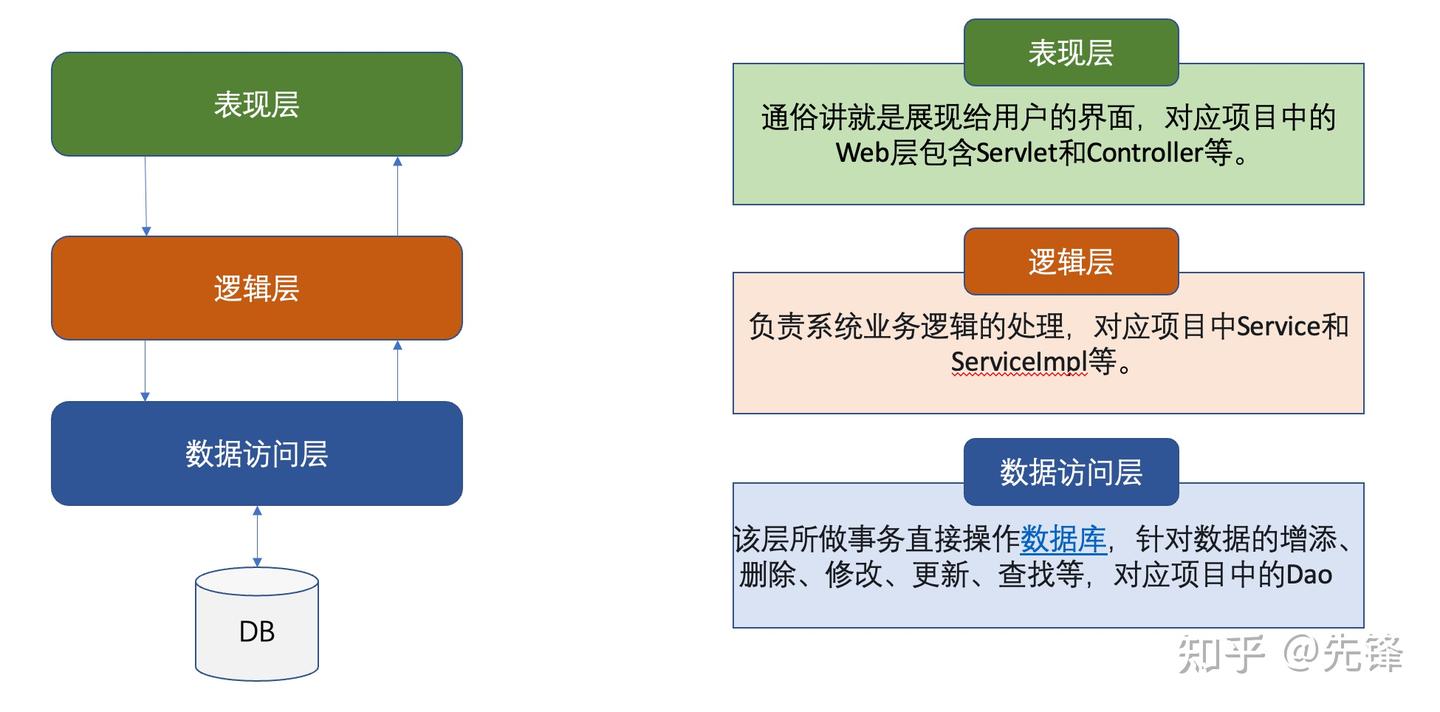
- 表现层(Controller),通俗讲就是展现给用户的界面,对应项目中的Web层包含Servlet和Controller等。
- 业务逻辑层(Service):负责系统业务逻辑的处理,对应项目中Service和ServiceImpl等。
- 数据访问层(DAO):该层所做事务直接操作数据库,针对数据的增添、删除、修改、更新、查找等,对应项目中的Dao。
在提出该分层架构的时代,多数系统往往较为简单,它有效地隔离了业务逻辑与数据访问逻辑,使得这两个不同关注点能够相对自由和独立地演化。
阿里四层架构
三层架构实现比较简单,很多朋友可能觉得项目分层就应该如此,结果就是往往会出现一大堆的业务逻辑都堆砌在Service层中。而在《阿里巴巴 Java 开发手册 》中将原来的三层架构进一步细化,添加了Manager通用业务处理层。
Manager层可以将原Service层的一些通用能力进行下沉,比如与缓存和存储交互策略,中间件的接入;还可以封装对第三方接口的调用,比如调用支付服务,调用审核服务等RPC接口。
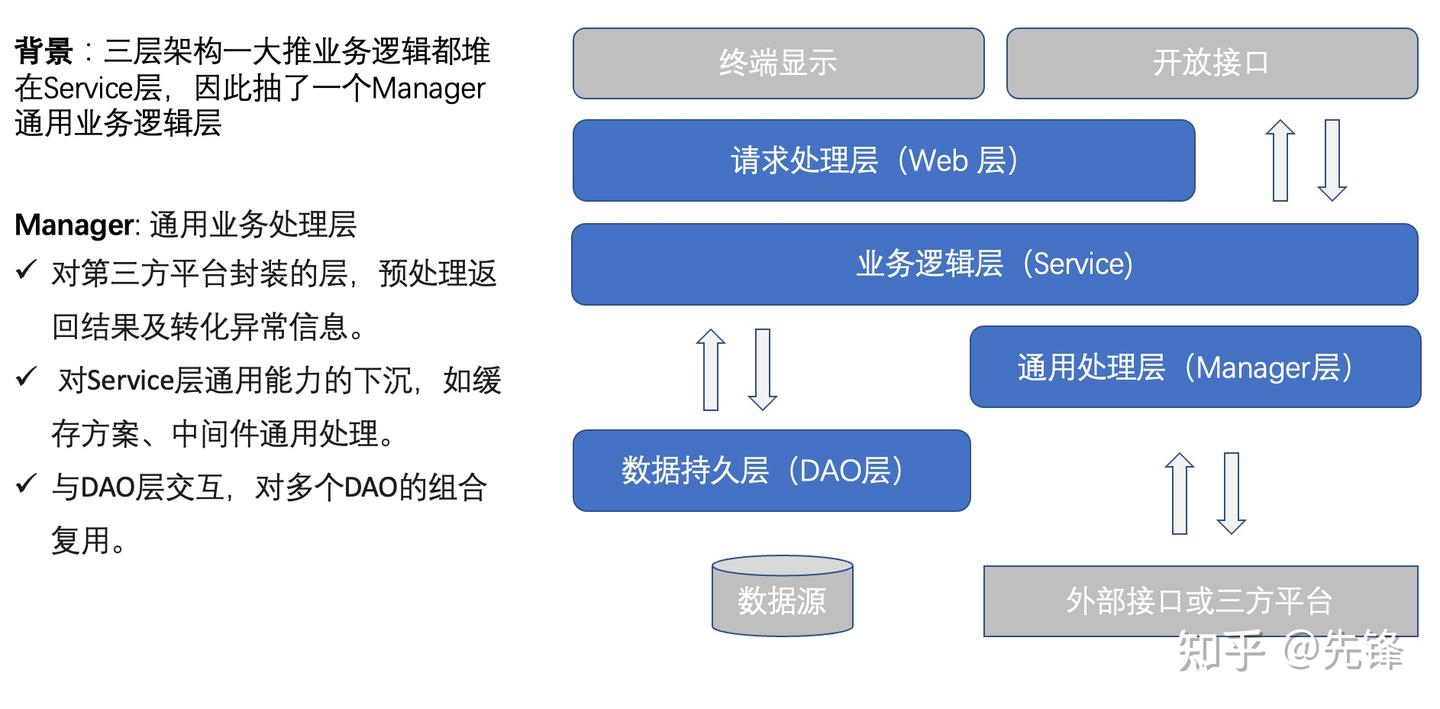
- Web层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service层:业务逻辑层。
- Manager层:通用业务处理层。
1)对第三方平台封装的层,预处理返回结果及转化异常信息。
2) 对Service层通用能力的下沉,如缓存方案、中间件通用处理。
3)与DAO层交互,对多个DAO的组合复用。 - DAO层:数据访问层,与底层 MySQL、Oracle、HBase 等进行数据交互。
DDD分层架构
DDD分层架构抽离了领域层,负责核心业务逻辑处理,领域层调用外部依赖全部通过接口,以保证领域层的100%单测覆盖率;应用层聚合多个领域层的能力,只做功能的组合、转发,不负责具体业务逻辑。
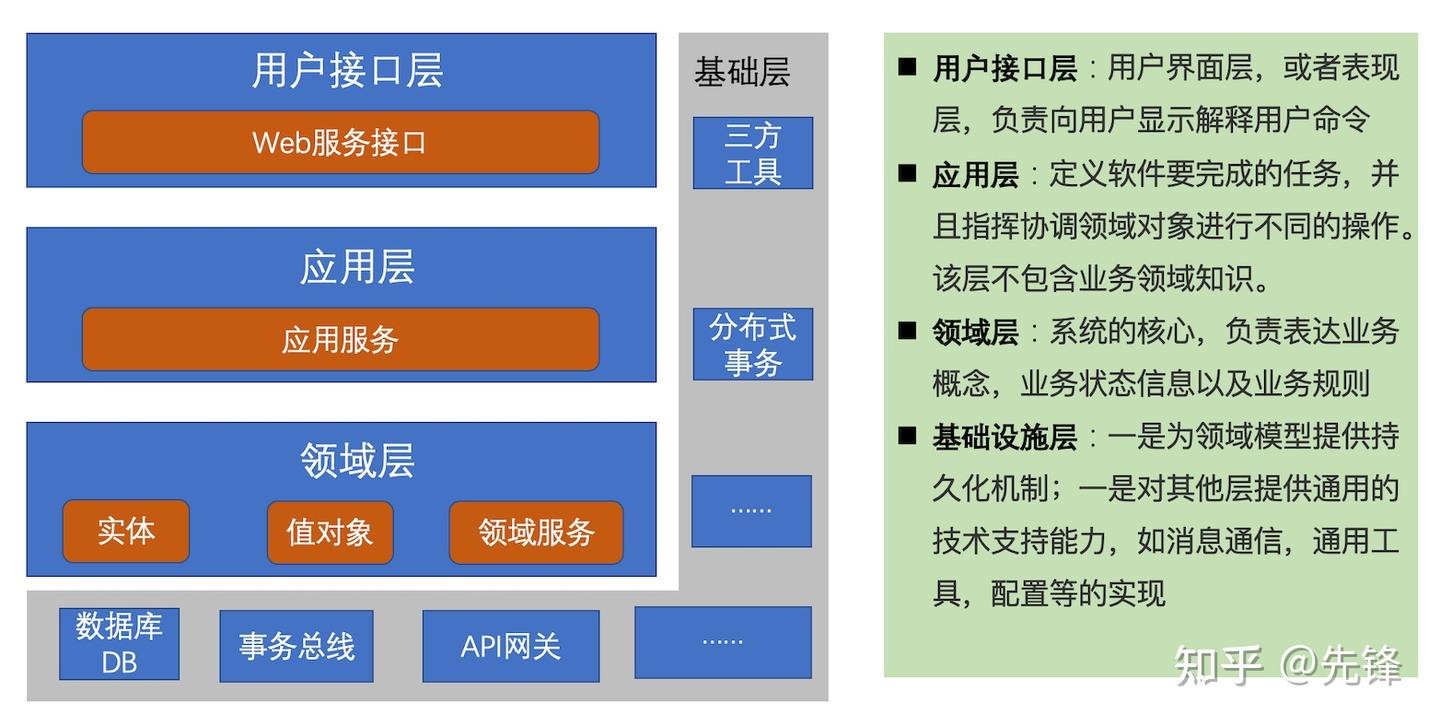
1. 用户接口层
它负责向用户显示信息和解释用户命令,完成前端界面逻辑。这里的用户不一定是使用用户界面的人,也可以是另一个计算机系统。
2. 应用层
它是很薄的一层,负责展现层与领域层之间的协调,也是与其它系统应用层进行交互的必要渠道。它主要负责服务的组合、编排和转发,负责处理业务用例的执行顺序以及结果的拼装,拼装完领域服务后以粗粒度的服务通过 API 网关向前台应用发布。通过这样一种方式,隐藏了领域层的复杂性及其内部实现机制。 应用层除了定义应用服务之外,在这层还可以进行安全认证,权限校验,持久化事务控制或向其他系统发送基于事件的消息通知。本层代码主要通过调用领域层服务,完成服务组合和编排形成粗粒度的服务,为前台提供API 服务。本层代码可进行业务逻辑数据的校验、权限认证、服务组合和编排、分布式事务管理等工作。
3. 领域层
它是业务软件的核心所在,包含了业务所涉及的领域对象(实体、值对象)、领域服务以及它们之间的关系,负责表达业务概念、业务状态信息以及业务规则,具体表现形式就是领域模型。领域驱动设计提倡富领域模型,即尽量将业务逻辑归属到领域对象上,实在无法归属的部分则以领域服务的形式进行定义。本层代码主要实现核心的业务领域逻辑,需要做好领域代码的分层以及聚合之间代码的逻辑隔离
4.基础设施层
一个系统的基础不仅仅限于对数据库的访问,还包括访问诸如网络、文件、消息队列或者其他硬件设施,因此本层更名为“基础设施层”是非常合理的。它向其他层提供通用的技术能力,为应用层传递消息(API 网关等),为领域层提供持久化机制(如数据库资源)等。
根据依赖倒置原则,封装基础资源服务,实现资源层与应用层和领域层的调用依赖反转,为应用层和领域层提供基础资源服务(如数据库、缓存等基础资源),实现各层的解耦,降低外部资源的变化对核心业务逻辑的影响。
本层主要包括两类适配代码:主动适配和被动适配。主动适配代码主要面向前端应用提供 API 网关服务,进行简单的前端数据校验、协议以及格式转换适配等工作。被动适配主要面向后端基础资源(如数据库、缓存等),通过依赖反转为应用层和领域层提供数据持久化和数据访问支持,实现资源层的解耦。
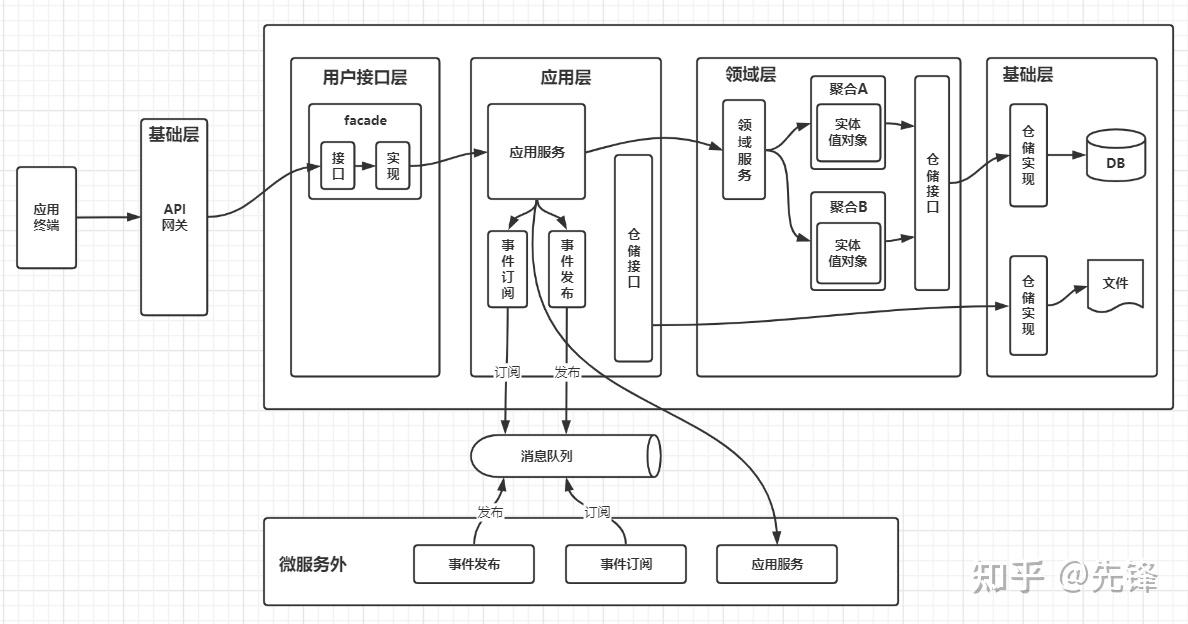
DDD各层的主要职责和怎么分工协作如下图:
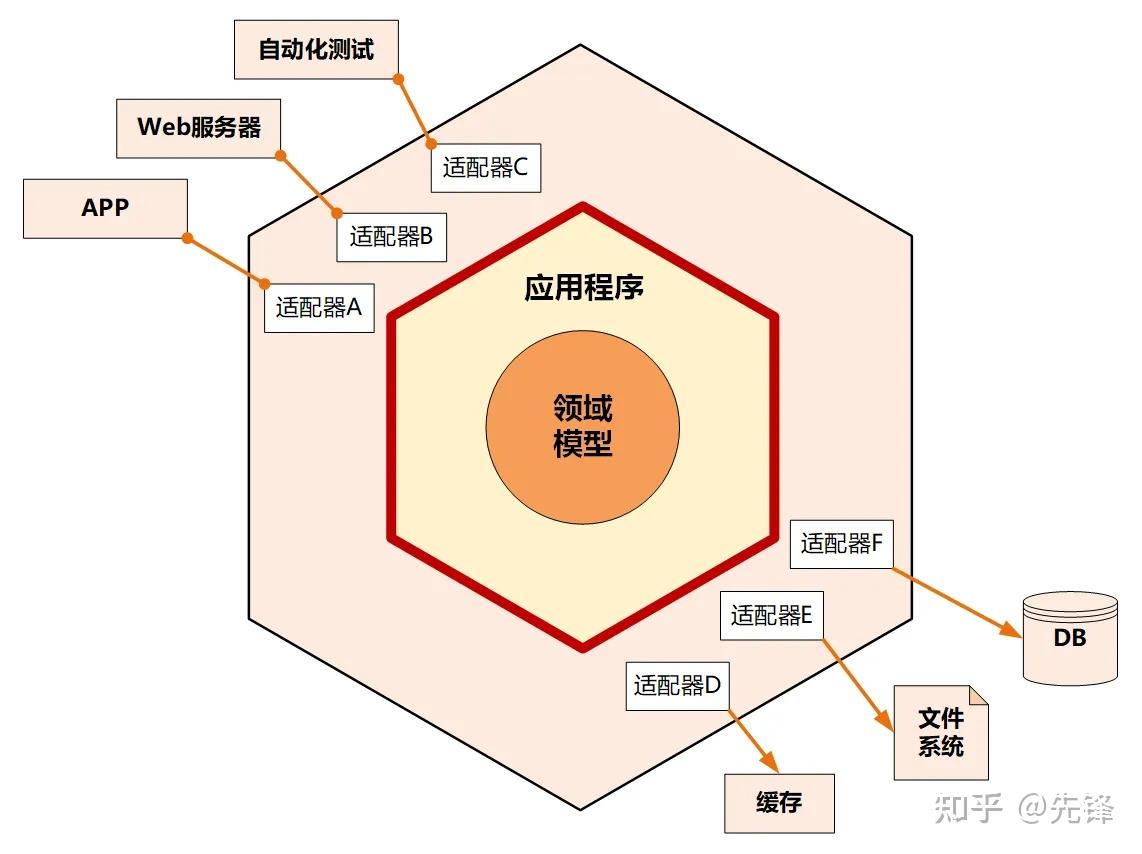
六边形架构
六边形架构将系统分为内部和外部两层六边形,内部六边形代表了应用的核心业务逻辑,外部六边形代表外部应用、驱动和基础资源等。内部通过端口和适配器与外部通信,对应用以API主动适配的方式提供服务,对资源通过依赖反转被动适配资源的形式呈现。一个端口可能对应多个外部系统,不同的外部系统使用不同的适配器,适配器负责对协议进行转换。这就使得应用程序能够以一致的方式被用户、程序、自动化测试、批处理脚本所驱动。
服务分层目录
每个项目的目录结构并不是有规定模板的,也有很多优秀的项目并不是常规的项目布局,还是要依据项目类型、大小及灵活程度做调整,但一定要保证结构清晰!一般要求:
- 命名清晰:目录命名要清晰、简介,不宜过长或过短。目录名要求能清晰表达出该目录所要实现的功能,在清晰表达的基础上最好用单数,避免单复混用的情况。
- 功能明确:一个目录所要实现的功能应该是明确的、并且在整个项目目录中具有高辨识度。
- 全面性:目录结构应该尽可能全面地包含研发过程中需要的功能,例如文档、脚本、源码管理、API 实现、工具包、第三方包、测试、编译产物等。
- 可预测性:项目规模一般是从小到大的,所以一个好的目录结构应该能够在项目变大时,仍然保持之前的目录结构。
- 可扩展性:每个目录下存放了同类的功能,在项目变大时,这些目录应该可以存放更多同类功能
上面的集中架构,体现在服务目录分层也会有一些差距,这里我只说明下,如果采用DDD分层架构,可能的目录分层是是怎样的:
├── README.md
├── application //应用层
│ ├── assembler //数据转换器
│ ├── dto //数据传输对象,application 的入参出参在这里定义
│ ├── port //六边形的端口,里面是 interface
│ └── service //application service,业务编排在这里进行
├── domain
│ ├── entity //实体和聚合实体在这里,业务逻辑也在这里
│ └── port //六边形的端口,里面是 interface
├── go.mod
├── go.sum
├── infrastructure //基础设施层
│ ├── adapter //六边形的适配器
│ ├── assembler //数据转换器
│ ├── persistence //持久化存储
│ └── remote //第三方调用
├── main.go
├── test
│ └── GetById.json
└── user_interface //用户接口层
├── port //六边形的端口,里面是 interface
├── kafka //kafka
├── rabbit //rabbitMQ
└── rpc //rpc