PostgreSQL内核学习笔记(索引1)
Index Scan涉及到两部分的内容Heap Only Tuple和index-only-scan。
什么是Heap Only Tuple(HOT)?
例如:Update a Row Without HOT
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
假设更新一条数据
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;
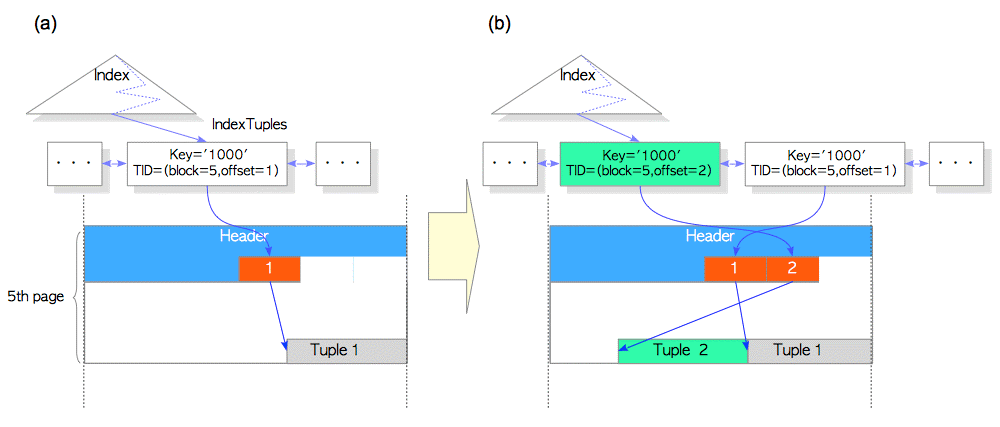
如果没有HOT机制,则不仅仅增加一个新的元组Tuple2,而且还增加了一个Index元组,如下图所示
如果Update a Row With HOT,那么更新后会怎样?
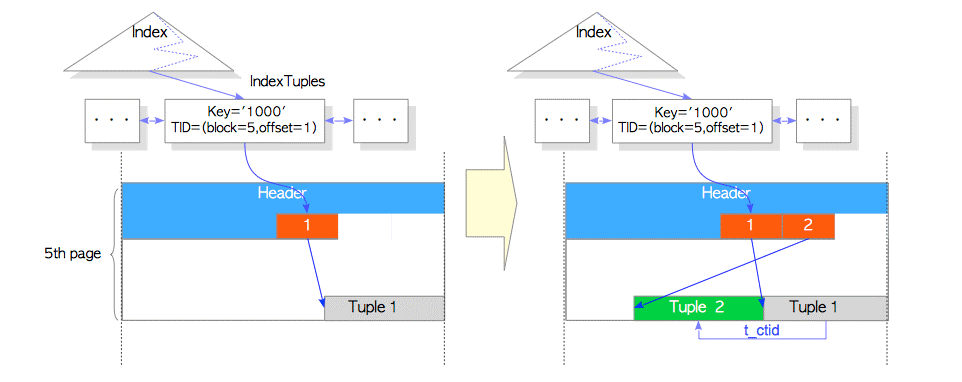
根据上图仅仅增加一个新的元组Tuple2。
同时Tuple1被设置了HEAP_HOT_UPDATED, Tuple2被设置了HEAP_ONLY_TUPLE.
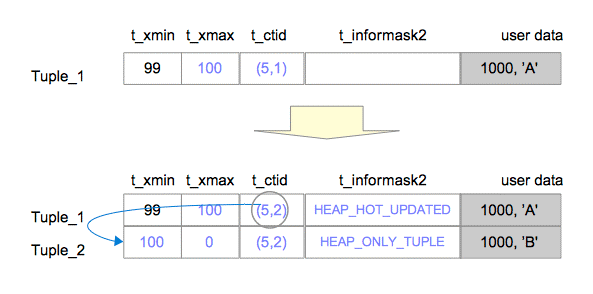
更新后数据是怎么通过Index检索到的?
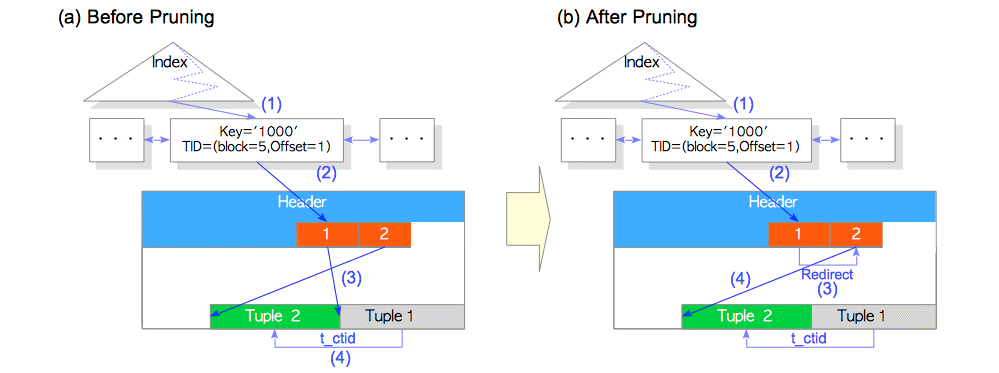
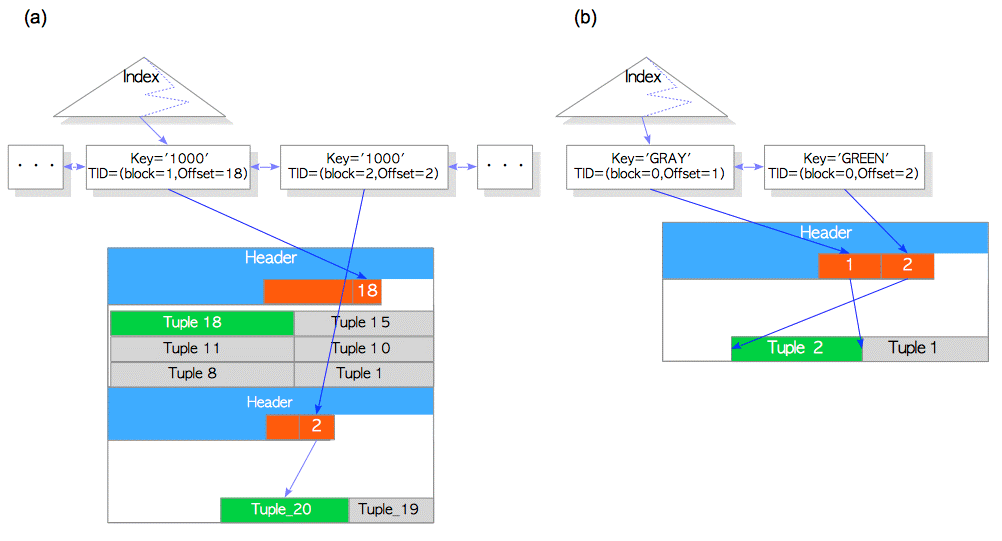
根据图(a)Before Pruning ,通过Index找到Tuple1,再根据Tuple1中的t_ctid找到Tupe2。此时会读取到两个元组Tuple1和Tuple2,根据MVCC机制决定读取Tupel1还是Tuple2.
上述的查找过程会带来问题:如果dead Tuple被删除了如:Tuple1,此时通过index就无法找到Tuple2.
为了解决这个问题,在合适的时候,PostgreSQL会像图(b)After Pruning中所示的现将Header中“1”指向“2”,再将“2”指向Tuple2. 这就被称为“Pruning”。
具体的执行时间可参考
https://github.com/postgres/postgres/blob/master/src/backend/access/heap/README.HOT
SELECT, UPDATE, INSERT and DELETE文被执行的时候,会进行pruning 处理。
![avatar]https://img2018.cnblogs.com/blog/1922961/202001/1922961-20200117160110815-2048897544.png)
在适当的时候,PostgreSQL会删除dead Tuple。PostgreSQL中被称为“Defragmentation”
注意:Defragmentation 的花费比VACUUM的花费要小,因为Defragmentation处理并不删除Index Tuple
下面的两个场景不适用于HOT
(1) 更新的元组和旧的原组不在一个page上,比如下图的图a此时需要增加一个新的Index Tuple指向新的Tuple
(2) 如果Index值被更新了,这时需在Index page中新增一个Index Tuple
HOT相关的统计信息可参考统计表pg_stat_all_tables
什么是Index-Only Scan?
为了降低I/O(Input/Output)的花费,当SELECT的目标列就是index 列时,直接使用Index key不去使用Table page。
例如下表
testdb=# \d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
name | text |
data | text |
Indexes:
"tbl_idx" btree (id, name)
表中已经插入的两个元组:
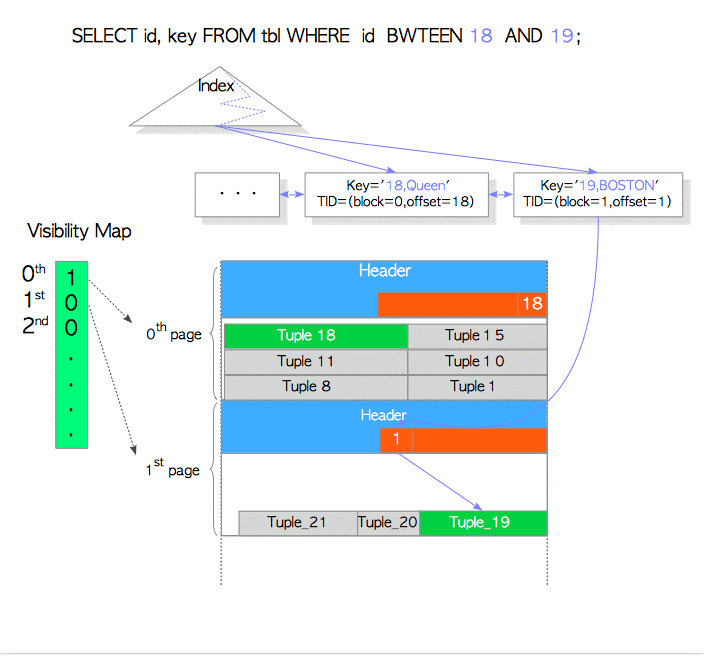
‘Tuple_18’, id的值是 ‘18’,name 的值是 ‘Queen’,这个元组存储在第0个 page.
‘Tuple_19’, id的值是‘19’, name 的值是 ‘BOSTON’, 这个元组存储在第1个 page
执行下面的SELECT文
testdb=# SELECT id, name FROM tbl WHERE id BETWEEN 18 and 19;
id | name
----+--------
18 | Queen
19 | Boston
(2 rows)
具体的过程如下:
这个查询要获取id, name这两列的值,并且"tbl_idx"是由这两列组成的。所以使用index scan。
咋看下是不需要获取table page的,因为index tuple已经包含需要的值了。
但是由于PostgreSQL还需要check元组的可见性visibility,index tuple中并不含有可见性visibility的信息(heap Tuple中才有的t_xmin and t_xmax 信息)。所以PostgreSQL不得不去使用table data。
为了解决这个问题,PostgreSQL使用了visibility map记录表的可见性,如下图。
如果所有tuple存储的page是可见的,PostgreSQL就直使用index key不去使用table page。否则的话,就去读table page检查其可见性。
在本例中Tuple_18直接使用index key,Tuple_19则需要使用table page检查其可见性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号