文献摘要热词统计及进阶需求
文献摘要热词统计进阶
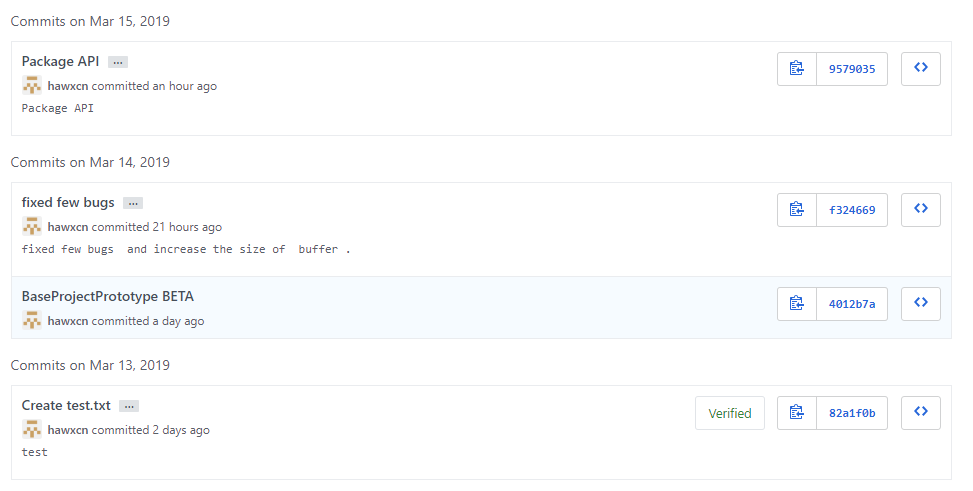
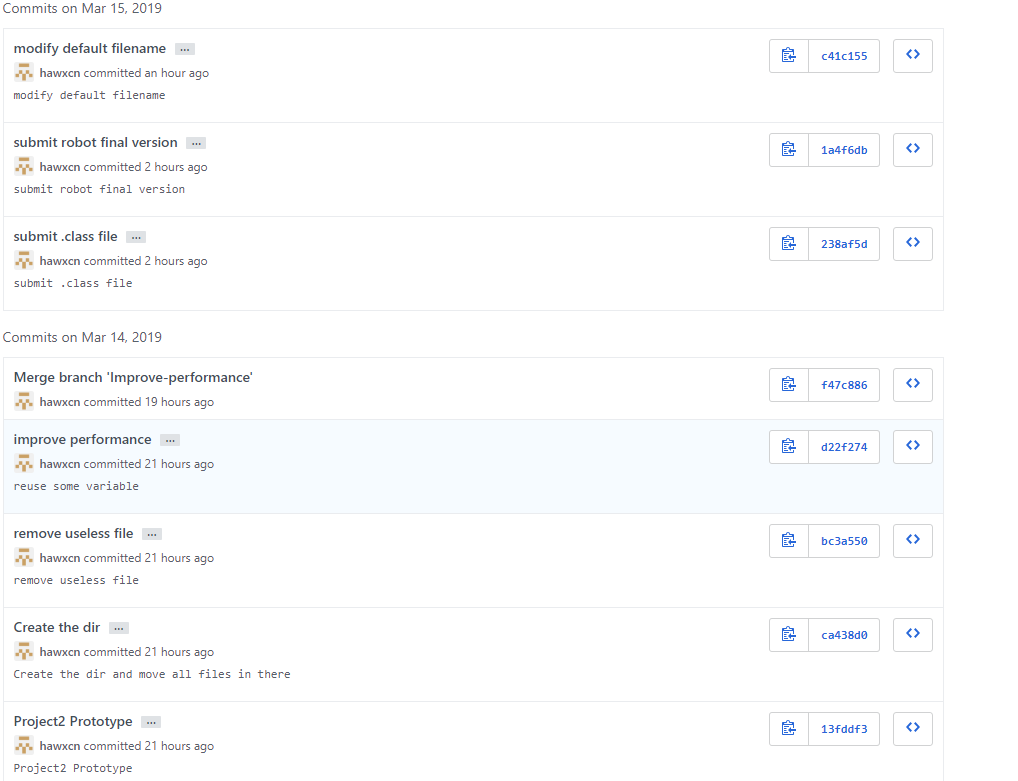
Github代码签入记录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| - Estimate | 估计这个任务需要多少时间 | 1275 | 2145 |
| Development | 开发 | ||
| - Analysis | 需求分析 (包括学习新技术) | 180 | 210 |
| - Design Spec | 生成设计文档 | 100 | 150 |
| - Design Review | 设计复审 | 60 | 40 |
| - Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| - Design | 具体设计 | 30 | 40 |
| - Coding | 具体编码 | 600 | 520 |
| - Code Review | 代码复审 | 60 | 70 |
| - Test | 测试(自我测试,修改代码,提交修改) | 120 | 980 |
| Reporting | 报告 | ||
| - Test Report | 测试报告 | 45 | 60 |
| - Size Measurement | 计算工作量 | 20 | 25 |
| - Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1275 | 2145 |
解题思路
需求分析
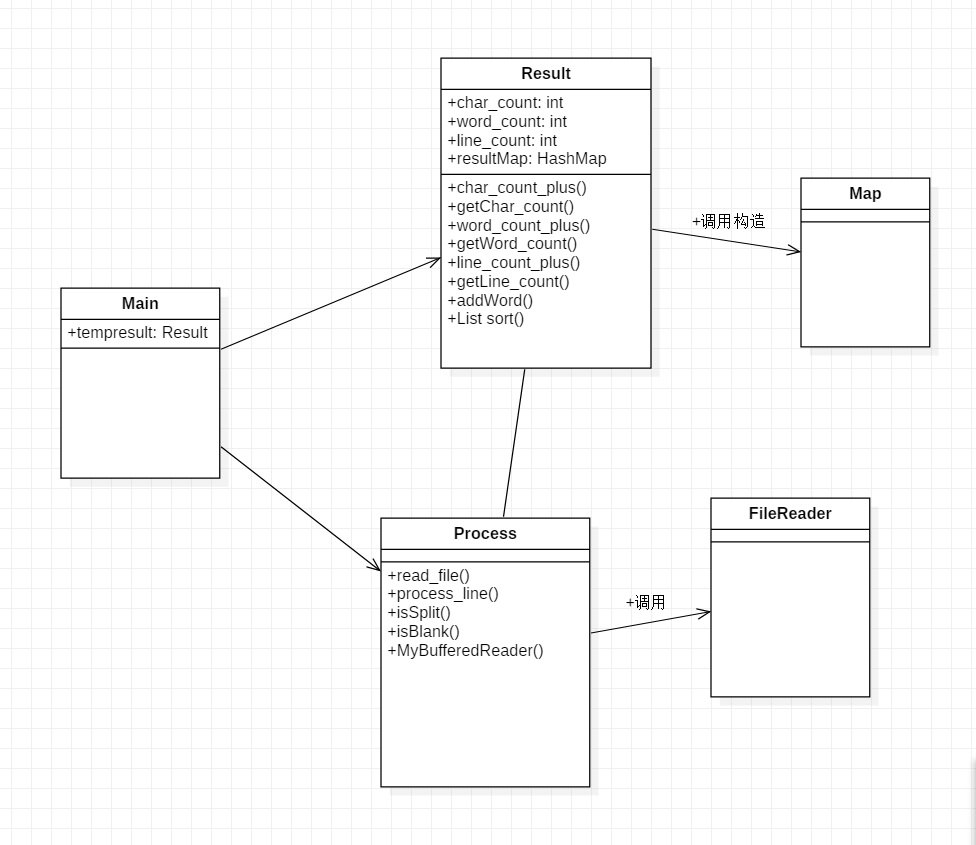
首先对任务需求进行分析,结合之前的代码经验,将问题划分为两大步骤。第一是对文件进行读取,获得文件内容。第二是对读取到文件内容进行分析及统计。于是创建出Main、Process、Result三个类,作用分别Main是程序入口、Process对读取到的文件内容进行分析统计、Result做为结构记录相应字符数、行数和单词及其频数。然后在Process类中统计字符数用String类的Length()算出字符数并记录,统计行数时通过按行读取文件计算出行数并记录,统计单词时依靠正则表达式匹配单词、统计频次并记录到Map结构中。并作出相应的类图使需求在类图都有对应的方法得到实现
最后设计比较刁钻的测试数据测试代码正确性、并且在代码中用时相对较长的部分进行力所能及的代码优化。
设计实现过程
类图展示
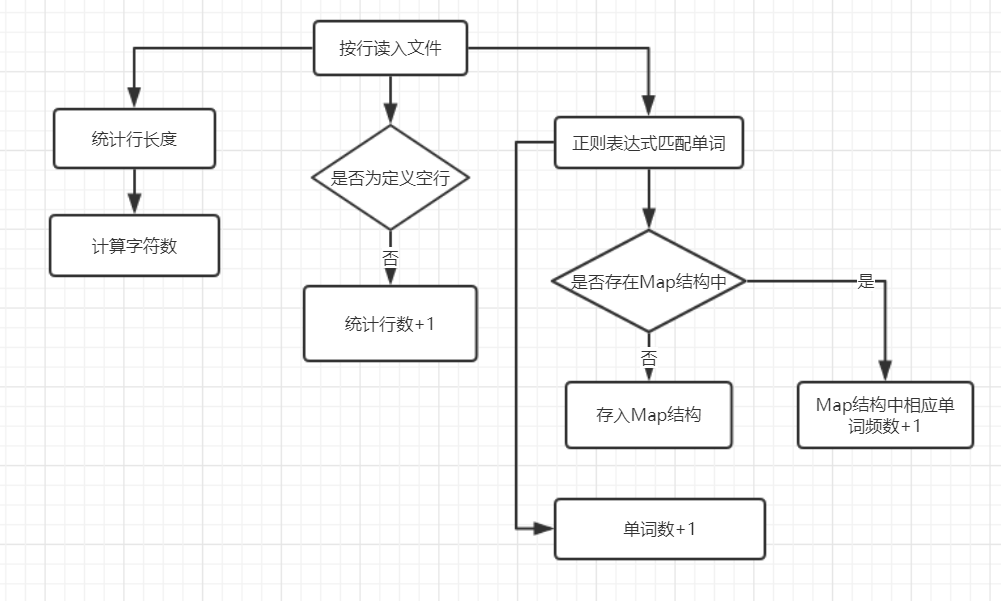
算法关键及流程图
-字符、行数、单词统计
程序性能改进及思路
基础及进阶需求均使用工具JProfiler监控处理随机生成的约700m大小文件分析内存,处理器占用。
通用优化部分
在此次程序编写的过程中,主要处理程序迭代了两次.在第一个原型程序时因为采用了按行读取再按字处理的方式导致效率较为低下,一个字符通常要用几个IF语句判断是否符合需求的要求,再加上不利于后续功能扩展便将其重新编写,采用正则表达式按行处理文件.
不论在基础还是进阶功能的编写中发现程序运行时要反复调用几个方法,而在方法中要不断创建数个Pattern类来构建正则表达式,因此在优化的过程中首先考虑将方法设置为静态类型,并将几个Pattern类的正则表达式在Process类构造的时候便进行编译,提高效率.
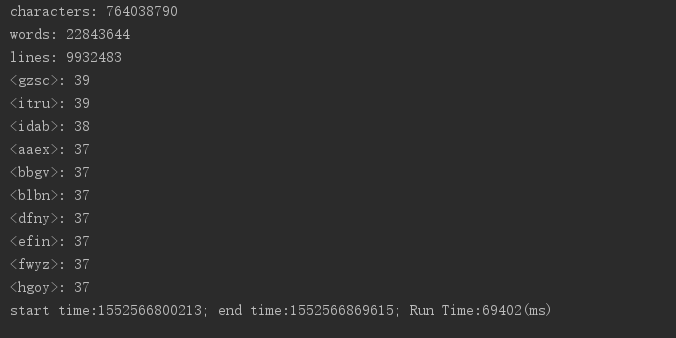
测试效果采用一个21M大小左右文件进行
基础未优化前
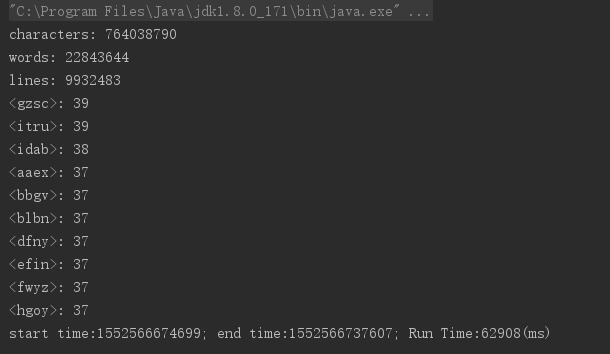
基础优化后:
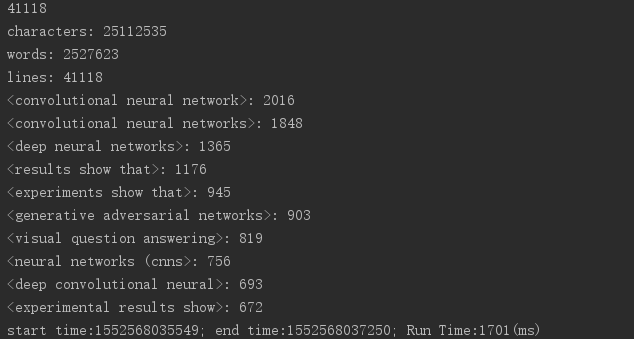
进阶需求采用一个约22M大小文件测试
优化前:
优化后
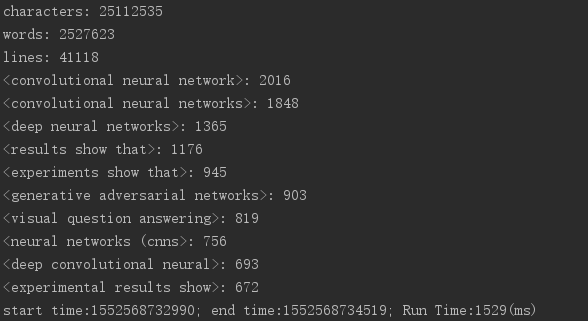
有一定效果但并不是十分明显
基础需求部分改进思路
各方法耗时:
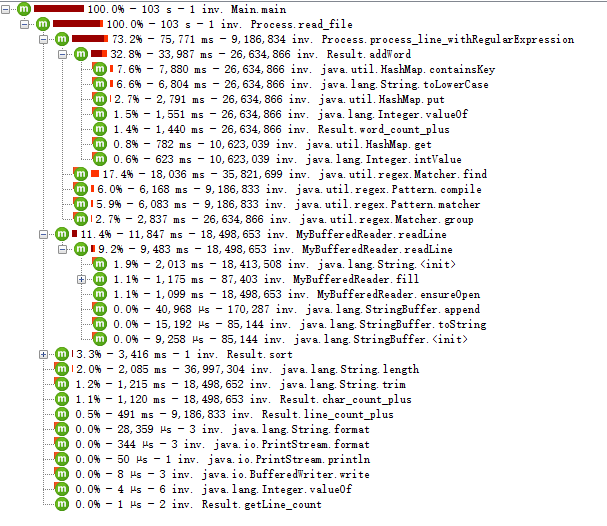
可以发现在哈希表处理的时候耗时占比较多.在程序中为了节约时间我们便直接使用JAVA提供的map结构储存单词,数量的键值对,但是JAVA本身提供的方法不能很好的满足我们的需求比如说单词数量排序的问题,目前解决方案是将MAP导出为一个list表,对此进行排序.在我们规划中是采用一个类似于treemap的顺序结构来进行有序插入,在节约排序时间的同时节约大量为了排序重复储存的内存空间.但是自定义结构需要花费大量时间测试可靠性,并且完成此类型超大文件所需的时间在一分钟左右,不算太过离谱,于是便计划在完成所有任务后最后进行.
此外由于前期分析得当,提前采用了Bufferedreader以带缓冲的方式读取文件,节约了大量的IO时间,使得即便在机械硬盘上文件读取部分花费时间占比不到10%,没有进一步优化的必要.
进阶需求部分改进思路
各方法耗时:
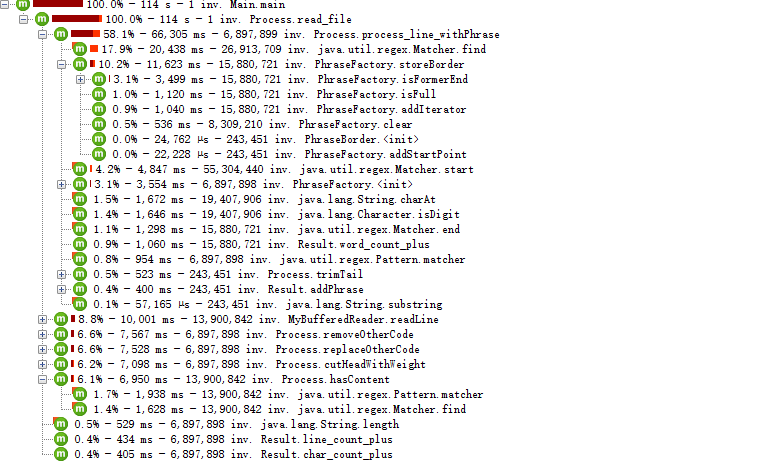
从图中可以得出在使用正则表达式完成需求的耗时占比较多,但考虑到需求并未明确提及只处理特定格式的文件,不能使用取巧办法忽略需求中提及的无关信息,此外考虑到主要处理文件需求为CVPR论文信息,在此类文件通常不大的情况下考虑到紧迫的时间安排不再进一步优化.
爬虫部分
爬虫部分程序主要由两部分组成,首先爬取位于 http://openaccess.thecvf.com/CVPR2018.py 的论文链接列表,将其中的论文URL添加到带爬取URL表中,再从URL列表取出URL不断爬取论文信息
最开始的原型实现使用单线程进行,由于该网站服务器位于境外,再加上带爬取URL有千条之多,因此速度十分缓慢.
采用JProfiler分析时间占用,经过团队团队讨论后发现,第二部分为大量独立任务构成,十分适合进行多线程优化,并且因为各个结果之间相互独立,不需要太多的多线程同步处理,还利于程序编写.因此我们首先对此进行了优化.
优化前:
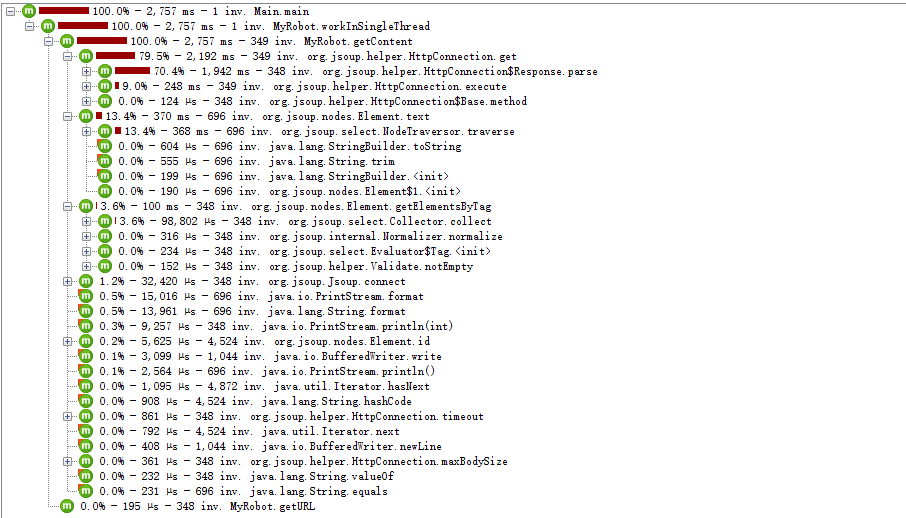

大约花费293秒
优化后:
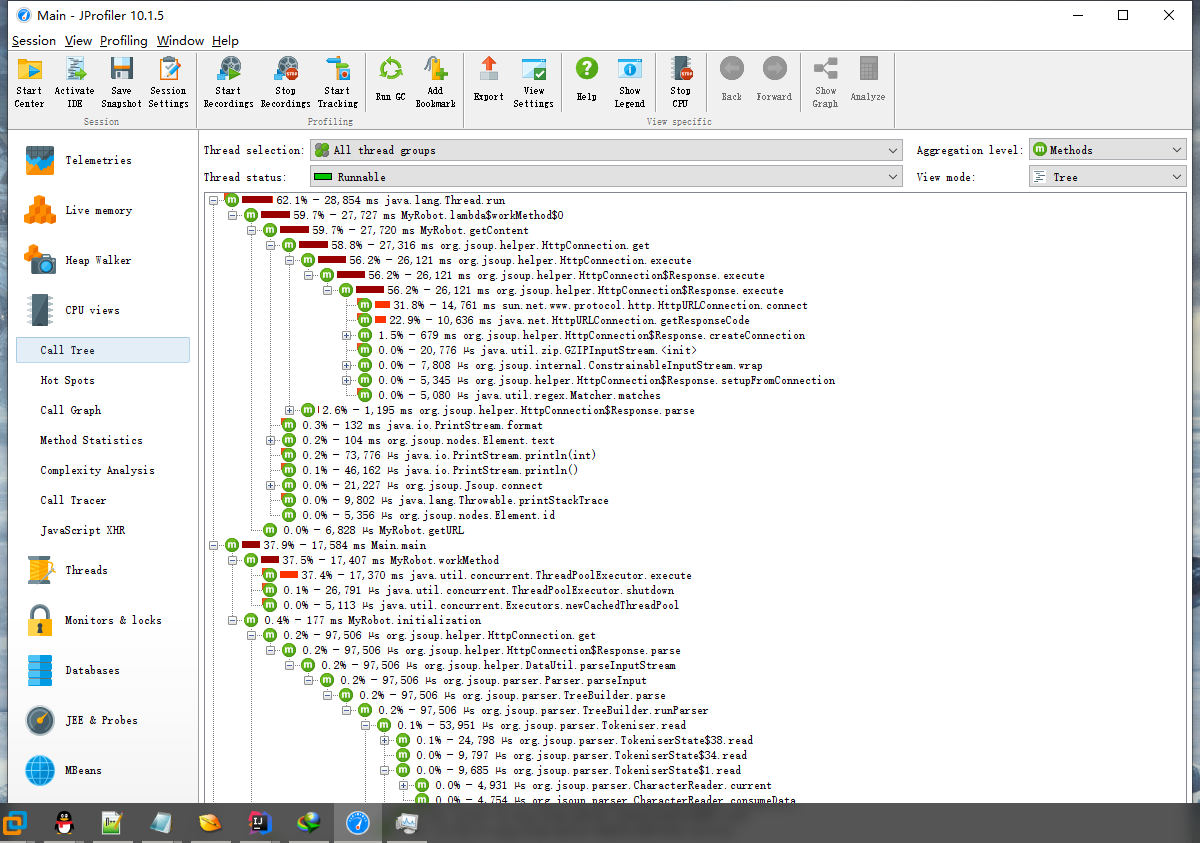
大约花费25秒,效率提升十分明显
在此基础上,我们进一步分析发现因为受制于该网站服务器位于境外的网络原因,每个线程进行网络通信的时候等待时间较久且容易出错,因此进一步的优化考虑为采用位于境外代理池替换本机进行信息爬取,但受制于成本以及时间并未付诸实施.
关键代码展示
基础部分封装的3个API函数
public int getWord_count() { return result.getWord_count(); }
public int getChar_count() { return result.getChar_count(); }
public int getLine_count() { return result.getLine_count(); }
基础部分统计单词函数
private static void process_line_withRegularExpression(String str, Result resultClass){
Matcher m=p.matcher(str);
while(m.find()) {
//System.out.println(m.group(2));
resultClass.addWord(m.group(2));
}
}
基础部分统计字符数代码
while ((s = bufferedReader.readLine()) != null) {
i++;//行计数
resultClass.char_count_plus(s.length());//统计字符数
s = s.replaceAll("[^\\x00-\\x80]", "");
s=trim(s);//去掉开头不显示字符
if(s.length()!=0){//若有可显示字符则处理
resultClass.line_count_plus();//统计行数
process_line_withRegularExpression(s,resultClass);
}
}
基础部分单词数量统计汇总函数
public void addWord(String word) {
String tempWord = word.toLowerCase();
if (resultMap.containsKey(tempWord)) {//resultMap使用HashMap结构
resultMap.put(tempWord, resultMap.get(tempWord) + 1);
word_count_plus();
} else {
resultMap.put(tempWord, 1);
word_count_plus();
}
}
通用单词数量排序函数
public List<Map.Entry<String, Integer>> sort() {
//从HashMap恢复entry集合
//从resultMap.entrySet()创建LinkedList。我们将排序这个链表来解决顺序问题。
//我们之所以要使用链表来实现这个目的,是因为在链表中插入元素比数组列表更快。
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(resultMap.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
//通过传递链表和自定义比较器来使用Collections.sort()方法排序链表。
//降序排序
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if(o2.getValue()==o1.getValue()) return o1.getKey().compareTo(o2.getKey());
return o2.getValue().compareTo(o1.getValue());
//使用自定义比较器,基于entry的值(Entry.getValue()),来排序链表。
}
});
进阶部分短语基础处理函数
private static void process_line_withPhrase(String str, Result resultClass, int number,int weight) {
Matcher m = phrasePattern.matcher(str);
PhraseFactory phraseFactory = new PhraseFactory(number);//短语构造类
PhraseBorder phraseBorder;//result
while (m.find()) {
if (m.start() == 0 || !Character.isDigit(str.charAt(m.start() - 1))){
//判断单词开头是否为数字
resultClass.word_count_plus();
if ((phraseBorder = phraseFactory.storeBorder(m.start(), m.end())) != null) {
//储存单词位置
int newEnd = trimTail(str, phraseBorder.start, phraseBorder.end);
//System.out.println(str.substring(phraseBorder.start, newEnd));
resultClass.addPhrase(str.substring(phraseBorder.start, newEnd), weight);
//添加短语至结果集
}
}
}
}
短语构造函数
public PhraseBorder storeBorder(int start, int end) {//添加新的单词位置
if (!isFull()) {
if (isFormerEnd(start)) {
pool[iterator].start = start;
pool[iterator].end = end;
addIterator();
} else {
clear();
pool[iterator].start = start;
pool[iterator].end = end;
addIterator();
}
} else {
if (isFormerEnd(start)) {
pool[iterator].start = start;
pool[iterator].end = end;
addIterator();
int outputStart = pool[startPoint].start;
addStartPoint();//后移开头指针等于输出
return new PhraseBorder(outputStart, end);
} else {
clear();
pool[iterator].start = start;
pool[iterator].end = end;
addIterator();
}
}
return null;
}
爬虫代码
public int initialization(String URL) {//获得待爬取URL列表
try {
Document document = Jsoup.connect(URL).timeout(1000 * 60).maxBodySize(0).get();//
Elements links = document.getElementsByTag("a");
int i = 0;
for (Element link : links) {
String href = link.attr("href");
if (href.contains("content_cvpr_2018/html/")) {
URLs[i] = "http://openaccess.thecvf.com/" + href;
System.out.format("%d:%s\n", i, URLs[i]);
++i;
}
}
return URL_size = i;
} catch (IOException e) {
e.printStackTrace();
}
return -1;
}
public void workMethod() {//爬取管理方法
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < URL_size; i++) {
cachedThreadPool.execute(() -> getContent(getURL()));
}
try {
bufferedWriter.flush();
} catch (IOException e) {
e.printStackTrace();
}
cachedThreadPool.shutdown();
}
public void getContent(String URL) {//获得内容方法
try {
Document document = Jsoup.connect(URL).timeout(1000 * 600).maxBodySize(0).get();//
Elements links = document.getElementsByTag("div");
String content = null, title = null;
for (Element link : links) {
switch (link.id()) {//case "authors"://and time
case "papertitle":
title = link.text();
break;
case "abstract":
content = link.text();
break;
}
}
synchronized (this) {
System.out.println(outputNumber);
System.out.println();
bufferedWriter.write(String.valueOf(outputNumber));
bufferedWriter.newLine();
System.out.format("Title: %s\n", title);
bufferedWriter.write(String.format("Title: %s\n", title));
System.out.format("Abstract: %s\n", content);
bufferedWriter.write(String.format("Abstract: %s\n", content));
bufferedWriter.newLine();
bufferedWriter.newLine();
outputNumber++;
}
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
public synchronized String getURL() {//获得待爬取URL
if (currentURL < URL_size) return URLs[currentURL++];
else return null;
}
爬虫结果展示:

单元测试
基础测试部分使用C++语言编写了一个随机生成字符的程序,随机生成行数、字符串长度,然后写入到input.txt文件中。在生成字符串的同时,记录生成字符数,行数以及定义上的空行数。然后将生成的input.txt文件做为WordCount程序的测试文件,然后对比WordCount程序的输出结果与之前记录的结果。
#include<cstdio>
#include<time.h>
#include<stdlib.h>
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
srand(time(0)); //产生随机化种子
int count = 0;
int count1 = 0;
int n = rand() % 1000+99;
//在1000-99的范围内随机产生字符串个数
FILE *fp = fopen("input.txt","w");
int temp=n;
while (temp--) //依次产生n个字符串
{
int k = rand() % 150 + 0; //随机生成一个字符串的长度
if(k==0){
count1++;
}
count+=k;
for (int i = 0; i < k; i++)
{
int x;
x = rand() % (127 - 32) + 32;
fprintf(fp, "%c", x); //将x转换为字符输出
}
fprintf(fp, "\n");
}
printf("line: %d", n );
printf("空白line: %d", count1 );
printf("\n character: %d\n",count);
return 0;
}
Junit单元测试截图
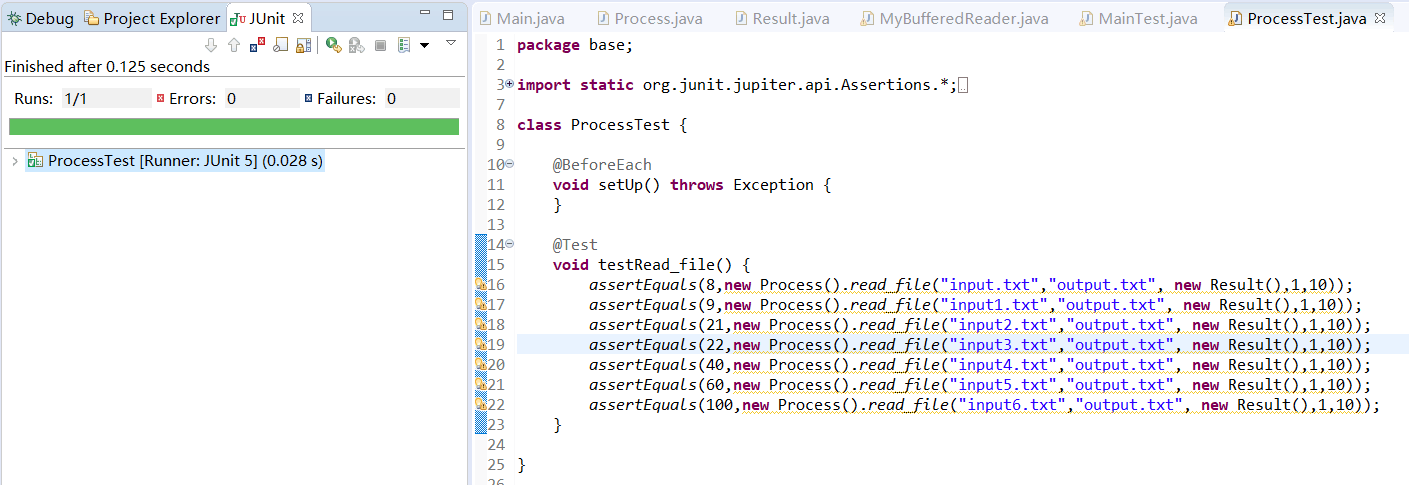
进阶需求采用官网论文文件测试
注:官网爬取结果存在非ASCII字符且位于两个合法单词之间的情况, 本次程序对于此类情况按两个单词处理
若按一个单词计算此类情况单词数量应少掉10个左右
结果

测试数据构造思路
-统计行数
构造思路:1.中间增加空白行
2.单行放入定义空白符
-统计单词
构造思路:1.多种不合法单词,如1aaaa、the、abc123a等
2.分割符分割单词,如task-masn、mesk--a123等
-统计词组
构造思路:1.单词间添加非法单词,如aaaa in bbbb等
2.单词间添加分割符,如aaaa(%bbbb等
-极端情况处理
构造思路:生成大型文本文件(738m)测试程序稳定性
部分测试数据概览:
character: 37854 line: 500 无效空白line: 3
character: 75998 line: 1016 无效空白line: 6

遇到的困难及解决
在这次结对任务中遇到的困难是比较多的,首先在阅读任务、分析需求的时候就出现了相当多的分歧,分隔符划分、词组匹配等。相信这也不只是我们遇上的困难,从微信群里就可以看出,这一点可以说是全班同学的共同问题。这一部分的解决方法就是讨论,不止结对两人间讨论,群内讨论、与其他小组进行讨论并且交换测试数据互相纠错。其次是爬虫部分,因为之前没有接触过,所以是现学的技巧。因为时间限制,所以这一部分还是有点难度的。最后是代码Debug,因为在需求分析时的出现的问题,在后面代码Debug的时候花费了相当多的时间,在给出的PSP表中可以看出,原本预计120分钟要完成的测试(自我测试,修改代码,提交修改)项中,实际花费时间拉长到了980分钟。
最后此次作业本来在规划时划拨了完整的一天时间进行代码的优化,但是需求一直不断在变化,每天在完成新功能的同时还要对之前完成的部分进行修改以适应新的需求.而且由于许多需求此前定义不明确导致我们在需求分析时考虑的情况不够贴近实际,在编码时发现此前的需求分析及功能设计不能满足需要,需要重新构建,并且代码也得推倒重写,浪费了大量时间
而且由于需求定义不明,导致我们对部分情况的处理结果进行了讨论并定义当前程序存在BUG,但是等到我们花费大量时间查找文件内容并定位到具体导致BUG原因,随后又花费一定时间进行修复,挤占了本就为数不多的代码测试时间,结果一觉醒来发现做了无用功?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号