Hive行转列和列转行
Hive行转列和列转行
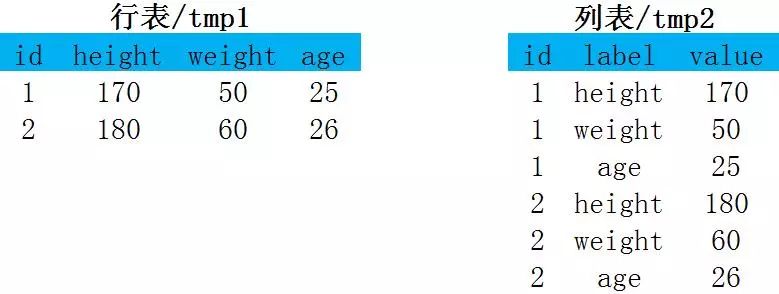
行转列(一行变多行)
方法1:简单粗暴 union all --不推荐
优点:好理解
缺点:多次select同一张表,造成计算量成倍增加;代码冗余,单个select条件复杂后会变得较难维护。
-- concat('height',':',height,',','weight',':',weight,',','age',':',age) as value
select id, 'height' as label, height as value
from tmp1
union all
select id, 'weight' as label, weight as value
from tmp1
union all
select id, 'age' as label, age as value
from tmp1
方法2: concat + split + lateral view explode --推荐
优点:展开效率高,计算量少于多层union all; 代码更精简
缺点:如果value是数值型,concat后数值型将转换为string型,展开后要多一层转换。
-- 最后将info的内容切分
-- 注意:value列按需转换为int/bigint型
select id
,split(info,':')[0] as label
,split(info,':')[1] as value
from
(
-- 先将数据拼接成“height:180,weight:60,age:26”
select id
,concat('height',':',height,',','weight',':',weight,',','age',':',age) as value
from tmp1
) as tmp1
lateral view explode(split(value,',')) mytable as info; -- 然后在借用explode函数将数据膨胀至多行
列转行(多行变一行)
方法1: 简单粗暴left join --不推荐
缺点:多次select同一张表,计算资源浪费。代码冗余高。
优点:没发现
select a.id as id
,tmp1.value as height
,tmp2.value as weight
,tmp3.value as age
from (
select id from tmp2
group by id
) a
left join (
select id
,label
,value
from tmp2
where label = 'height'
) as tmp1join on a.id = tmp1.id
left join (
select id
,label
,value
from tmp2
where label = 'weight'
) as tmp2join on a.id = tmp2.id
join
(
select id
,label
,value
from tmp2
where label = 'age'
) as tmp3 on a.id = tmp3.id;
方法2: group by + sum()/max() --推荐
优点:简洁易懂,适用于任何情形
缺点:计算过程增加了多余的sum()/max()步骤
select id
, sum(if(label='height', value, 0)) as height
, sum(if(label='weight', value, 0)) as weight
, sum(if(label='age', value, 0)) as age
from tmp2
group by id
方法3:concat+ collect_set + concat_ws + str_to_map --推荐
优点:计算资源最节省,最后map取值的方式最优雅
缺点:concat+ collect_set + concat_ws + str_to_map 比较难理解。
select id
,tmpmap['height'] as height
,tmpmap['weight'] as weight
,tmpmap['age'] as age
from
(
select id
,str_to_map(concat_ws(',',collect_set(concat(label,':',value))),',',':') as tmpmap
from tmp2
group by id
) as tmp1;
参考:
https://blog.csdn.net/weixin_30847543/article/details/112421747

 浙公网安备 33010602011771号
浙公网安备 33010602011771号