数据中台的精细化成本管理
数据中台的精细化成本管理
原文连接:08 | 交付速度和质量问题解决了,老板说还得“省” (geekbang.org)
好的数据中台:快、准、省
数据部门是企业的成本中心,如果要展现自己的价值,一方面是支撑好业务,获得业务的认可;另外一方面就是精简成本,为公司省钱。
有哪些成本的陷阱
常见问题:
- 数据上线容易下线难
- 近30日无访问表数量及占比
- 低价值的数据应用消耗了大量的资源
- 一张表的投入和产出是否匹配
- 烟囱式的开发模式
- 数据重复加工
技术性问题:
- 数据倾斜:
- 木桶效应:总任务消耗资源 = max{单个任务消耗的资源} * 任务数量
- 数据未设置生命周期
- 一般原始数据和明细数据,保留完整的历史数据
- 汇总层、应用层,保留几天的快照或者分区
- 调度周期不合理
- 任务有明显的高峰低谷效应,但是服务器资源不是弹性的,整个集群的资源配置取决于高峰期的任务消耗。
- 所以,把一些不必要在高峰期运行的任务迁移到低谷期运行,也可以节省资源的消耗。
- 任务参数配置
- 数据未压缩
- Hadoop的HDFS为了实现高可用,默认数据存储3副本,所以大数据的物理存储量消耗是比较大的。
- 另外,在Hive或Spark的计算过程中,中间结果也需要压缩,可以降低网络传输量,提高Shuffer性能。
如何实现精细化成本管理
成本治理步骤:
-
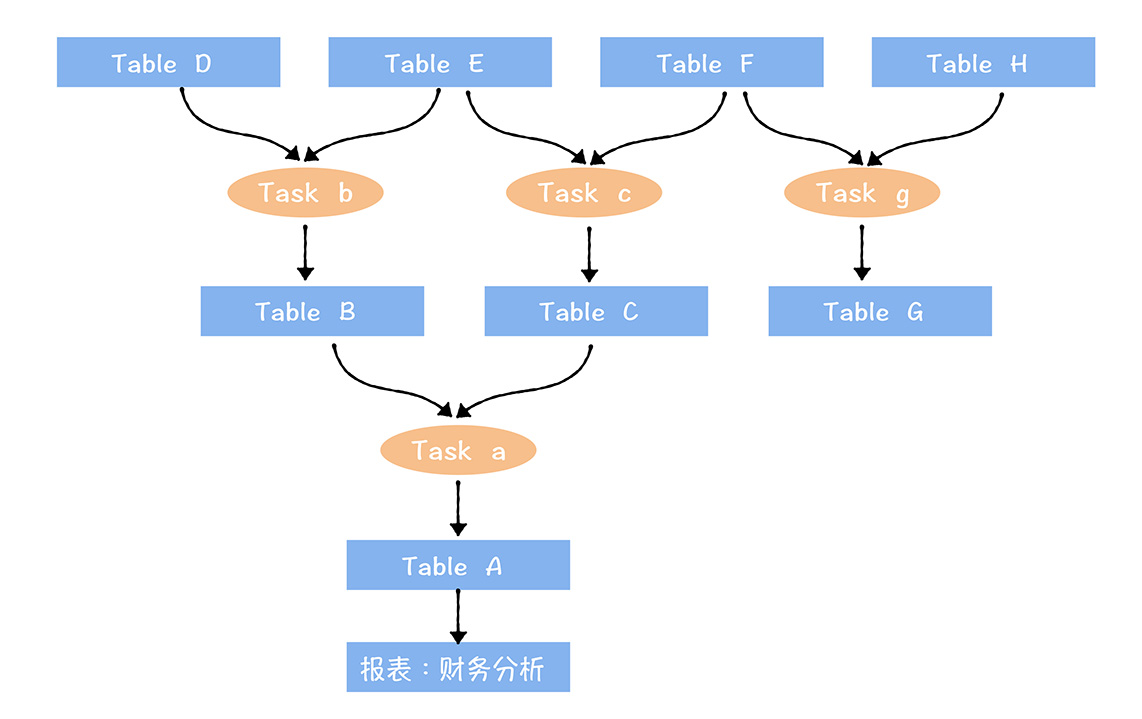
全局盘点:建立全链路数据资产视图
![img]()
核算数据成本:
- 例如:末端报表的成本 = n个任务加工消耗的计算成本 + m个表消耗的存储资源成本
- 如果一个表被多个下游应用复用,那这个表的存储资源成本以及产出任务消耗的成本,需要分摊给多个应用。
核算数据价值:
-
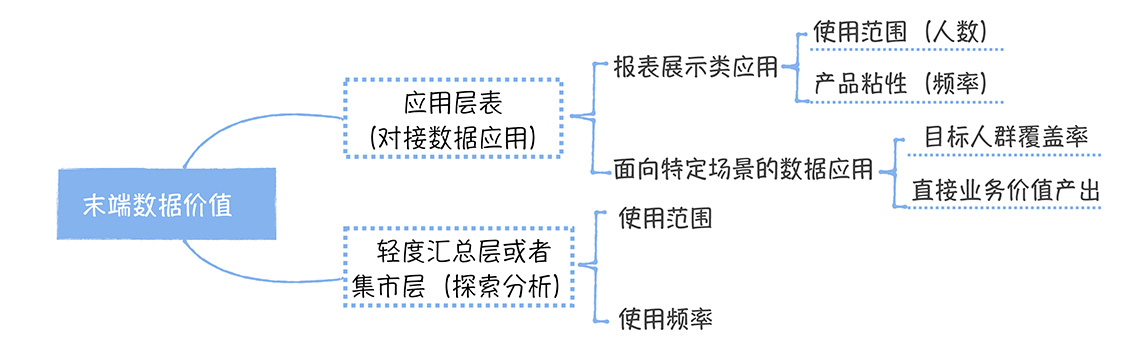
末端数据价值
![img]()
-
在计算使用范围时,通常用周活来评估,同时还要考虑不同管理级别的人权重,对于老板,他一个人的权重可以相当于 1000 个普通员工。
-
发现问题:关注三类问题
-
持续产生成本,但是已经没有使用的末端数据(“没有使用”一般指 30 天内没有访问)
-
数据应用价值很低,成本却很高,这些数据应用上游链路上的所有相关数据
-
高峰期高消耗的数据。
-
-
治理优化
- 对第一类问题:指定下线计划,对表进行下线
- 对第二类问题:按照应用粒度评估应用是否还有存在的必要
- 对第三类问题:具体分为产出数据的任务高消耗和数据存储高消耗
- 任务高消耗:定位问题原因,例如数据倾斜
- 数据存储高消耗:考虑数据压缩方式和数据生命周期设置是否合理
-
效果评估:省了多少钱
- 下线了多少任务和数据
- 这些任务每日消耗了多少资源(只统计高峰时间内)
- 数据占用了多少存储空间
成本治理中心
数据成本治理的产品化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号