pwn——IO_FILE学习(一)
IO_FILE学习(一)
2020-08-22 14:01:55 hawk
因为参加的2020年全国大学生信息安全竞赛创新实践赛时,因为自己十分的菜,pwn题仅仅痛苦的做出了几道。之后学校大佬分享了一下他们的wp,仔细查看部分题目的wp,解法涉及到了之前的盲区——IO_FILE(比如其中的一道题,我傻乎乎的将strdup的got表转换为printf的plt地址,然后再leak对应的调用strdup的函数栈的基址,最后使用格式化字符串漏洞leak程序的libc基址并修改strdup为system,太笨了。。;而当后面出现了FULL RELRO和PIE保护机制时,这个方法就失效了,我也就不会了。。。),因此这里特点学习一下IO_FILE相关的知识,填补一下知识短板。
IO_FILE概述
众所周知,Linux将一切都当作文件进行操作,因此实际上,对于程序的IO来说,也是如此。而顾名思义,IO_FILE就是和描述IO的文件结构体,我们首先查看一下相关的源代码(我的是glibc2.23,不同版本内容可能会有一定差别),其中IO_FILE相关的源代码位于glibc源代码的libio/libioP.h文件中,如下所示
/* We always allocate an extra word following an _IO_FILE. This contains a pointer to the function jump table used. This is for compatibility with C++ streambuf; the word can be used to smash to a pointer to a virtual function table. */ struct _IO_FILE_plus { _IO_FILE file; const struct _IO_jump_t *vtable; };
实际上我们最终描述文件流文件的数据结构是_IO_FILE_plus,其中有_IO_FILE结构体和常量_IO_jump_t(内容不可被修改),而根据成员的名称,我们大概可以推测出不同成员的作用——file成员应该包含的是该文件的一些关键数据;而vtable,也就是virtual table,虚表,即各种操作函数的指针。
下面我们再分别查看一个各自成员的组成,首先是_IO_FILE,其源代码位于libio/libio.h文件中,如下所示
struct _IO_FILE { int _flags; /* High-order word is _IO_MAGIC; rest is flags. */ #define _IO_file_flags _flags /* The following pointers correspond to the C++ streambuf protocol. */ /* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */ char* _IO_read_ptr; /* Current read pointer */ char* _IO_read_end; /* End of get area. */ char* _IO_read_base; /* Start of putback+get area. */ char* _IO_write_base; /* Start of put area. */ char* _IO_write_ptr; /* Current put pointer. */ char* _IO_write_end; /* End of put area. */ char* _IO_buf_base; /* Start of reserve area. */ char* _IO_buf_end; /* End of reserve area. */ /* The following fields are used to support backing up and undo. */ char *_IO_save_base; /* Pointer to start of non-current get area. */ char *_IO_backup_base; /* Pointer to first valid character of backup area */ char *_IO_save_end; /* Pointer to end of non-current get area. */ struct _IO_marker *_markers; struct _IO_FILE *_chain; int _fileno; #if 0 int _blksize; #else int _flags2; #endif _IO_off_t _old_offset; /* This used to be _offset but it's too small. */ #define __HAVE_COLUMN /* temporary */ /* 1+column number of pbase(); 0 is unknown. */ unsigned short _cur_column; signed char _vtable_offset; char _shortbuf[1]; /* char* _save_gptr; char* _save_egptr; */ _IO_lock_t *_lock; #ifdef _IO_USE_OLD_IO_FILE }; struct _IO_FILE_complete { struct _IO_FILE _file; #endif #if defined _G_IO_IO_FILE_VERSION && _G_IO_IO_FILE_VERSION == 0x20001 _IO_off64_t _offset; # if defined _LIBC || defined _GLIBCPP_USE_WCHAR_T /* Wide character stream stuff. */ struct _IO_codecvt *_codecvt; struct _IO_wide_data *_wide_data; struct _IO_FILE *_freeres_list; void *_freeres_buf; # else void *__pad1; void *__pad2; void *__pad3; void *__pad4; # endif size_t __pad5; int _mode; /* Make sure we don't get into trouble again. */ char _unused2[15 * sizeof (int) - 4 * sizeof (void *) - sizeof (size_t)]; #endif };
该数据结构大概如此,其他大小通过输出sizeof可以判断(64/0xd8, 32/0x94)。我们根据源代码中的注释,就很容易注意到中间的那些指针应该就和输入、输出数据有相当大的关系了。这些我们会在后面在进行分析。
下面我们再介绍一下_IO_FILE_plus的另一个重要的成员结构,即_IO_jump_t结构,其源代码位于libio/libioP.h文件中,如下所示
struct _IO_jump_t { JUMP_FIELD(size_t, __dummy); JUMP_FIELD(size_t, __dummy2); JUMP_FIELD(_IO_finish_t, __finish); JUMP_FIELD(_IO_overflow_t, __overflow); JUMP_FIELD(_IO_underflow_t, __underflow); JUMP_FIELD(_IO_underflow_t, __uflow); JUMP_FIELD(_IO_pbackfail_t, __pbackfail); /* showmany */ JUMP_FIELD(_IO_xsputn_t, __xsputn); JUMP_FIELD(_IO_xsgetn_t, __xsgetn); JUMP_FIELD(_IO_seekoff_t, __seekoff); JUMP_FIELD(_IO_seekpos_t, __seekpos); JUMP_FIELD(_IO_setbuf_t, __setbuf); JUMP_FIELD(_IO_sync_t, __sync); JUMP_FIELD(_IO_doallocate_t, __doallocate); JUMP_FIELD(_IO_read_t, __read); JUMP_FIELD(_IO_write_t, __write); JUMP_FIELD(_IO_seek_t, __seek); JUMP_FIELD(_IO_close_t, __close); JUMP_FIELD(_IO_stat_t, __stat); JUMP_FIELD(_IO_showmanyc_t, __showmanyc); JUMP_FIELD(_IO_imbue_t, __imbue); #if 0 get_column; set_column; #endif };
我们简单列出来对应的数据的索引,方便之后进行查询,如下所示
0,size_t, __dummy 1,size_t, __dummy2 2,_IO_finish_t, __finish 3,_IO_overflow_t, __overflow 4,_IO_underflow_t, __underflow 5,_IO_underflow_t, __uflow 6,_IO_pbackfail_t, __pbackfail 7,_IO_xsputn_t, __xsputn 8,_IO_xsgetn_t, __xsgetn 9,_IO_seekoff_t, __seekoff 10,_IO_seekpos_t, __seekpos 11,_IO_setbuf_t, __setbuf 12,_IO_sync_t, __sync 13,_IO_doallocate_t, __doallocate 14,_IO_read_t, __read 15,_IO_write_t, __write 16,_IO_seek_t, __seek 17,_IO_close_t, __close 18,_IO_stat_t, __stat 19,_IO_showmanyc_t, __showmanyc 20,_IO_imbue_t, __imbue
而我们在程序中经常会听到如下一些关键字stdin、stdout等,实际上其也就是上面提到的结构,如下所示
extern struct _IO_FILE_plus _IO_2_1_stdin_; extern struct _IO_FILE_plus _IO_2_1_stdout_; extern struct _IO_FILE_plus _IO_2_1_stderr_;
可以看到,实际上我们所说的stdin、stdout以及stderr等,都是IO_FILE数据结构进行组织的。这样子,我们就基本完成了IO_FILE相关知识的总体概括。而实际上单纯对于IO_FILE结构来说,很难展开去讲——因为涉及的方面过多,但是我们在ctf比赛或者利用的时候,并不需要那么多,因此下面我将结合功能进行讲解。
puts分析
这里我们首先结合puts函数(往往可以用来leak地址),puts函数是由_IO_puts实现的(网络资料),而_IO_puts的功能主要会调用_IO_sputn,而_IO_sputn是_IO_new_file_xsputn的包装。当然这中间的分析极其复杂,我尝试从头到尾分析一遍,最后放弃了,因为过于庞大。但就我有限的尝试来看,实际上前者都是对后者的一些包装,也就是通过各种情况的判断,从而提高对于后者的调用效率,因此我们只需要直接对于最后的_IO_new_file_overflow函数进行分析即可。_IO_new_file_xsputn位于libio/fileops.c文件中,因为代码过长,我这里放置一个经过优化的源代码,如下所示
_IO_size_t _IO_new_file_xsputn (_IO_FILE *f, const void *data, _IO_size_t n) { const char *s = (const char *) data; _IO_size_t to_do = n; int must_flush = 0; _IO_size_t count = 0; if (n <= 0) return 0; /* This is an optimized implementation. If the amount to be written straddles a block boundary (or the filebuf is unbuffered), use sys_write directly. */ /* First figure out how much space is available in the buffer. */ if ((f->_flags & _IO_LINE_BUF) && (f->_flags & _IO_CURRENTLY_PUTTING)) ... } else if (f->_IO_write_end > f->_IO_write_ptr) count = f->_IO_write_end - f->_IO_write_ptr; /* Space available. */
/* Then fill the buffer. */ if (count > 0) { if (count > to_do) count = to_do; #ifdef _LIBC f->_IO_write_ptr = __mempcpy (f->_IO_write_ptr, s, count); #else memcpy (f->_IO_write_ptr, s, count); f->_IO_write_ptr += count; #endif s += count; to_do -= count; }
if (to_do + must_flush > 0) { _IO_size_t block_size, do_write; /* Next flush the (full) buffer. */ if (_IO_OVERFLOW (f, EOF) == EOF) /* If nothing else has to be written we must not signal the caller that everything has been written. */ return to_do == 0 ? EOF : n - to_do; /* Try to maintain alignment: write a whole number of blocks. */ block_size = f->_IO_buf_end - f->_IO_buf_base; do_write = to_do - (block_size >= 128 ? to_do % block_size : 0); if (do_write) { count = new_do_write (f, s, do_write); to_do -= count; if (count < do_write) return n - to_do; } /* Now write out the remainder. Normally, this will fit in the buffer, but it's somewhat messier for line-buffered files, so we let _IO_default_xsputn handle the general case. */ if (to_do) to_do -= _IO_default_xsputn (f, s+do_write, to_do); } return n - to_do; }
实际上我们可以根据源代码中的注释,大体了解程序的流程——首先根据情况获取可用空间大小,然后将字符串复制到_IO_write_ptr所指向的地址处,最后使用_IO_OVERFLOW、new_do_write等进行刷新即可。而实际上_IO_OVERFLOW是对于_IO_new_file_overflow函数的包装,最后仍然引用到了new_do_write,这里我放置一下其他博主https://n0va-scy.github.io/2019/09/21/IO_FILE/优化过的代码,如下所示
int _IO_new_file_overflow (_IO_FILE *f, int ch) { if (f->_flags & _IO_NO_WRITES) /* SET ERROR */ { ... } /* If currently reading or no buffer allocated. */ if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == NULL){ ... } if (ch == EOF) return _IO_do_write (f, f->_IO_write_base, f->_IO_write_ptr - f->_IO_write_base); //进入目标 if (f->_IO_write_ptr == f->_IO_buf_end ) /* Buffer is really full */ if (_IO_do_flush (f) == EOF) return EOF; *f->_IO_write_ptr++ = ch; if ((f->_flags & _IO_UNBUFFERED) || ((f->_flags & _IO_LINE_BUF) && ch == '\n')) if (_IO_do_write (f, f->_IO_write_base, f->_IO_write_ptr - f->_IO_write_base) == EOF) return EOF; return (unsigned char) ch; }
可以看出来,其会有两个判断,判断成功执行的代码都是设置错误并退出,我们在执行时需要绕过,其中对应的标志位宏定义位于libio/libio.h中,可以具体查看。可以看到,最后都可以归纳为对于_IO_do_write的调用,而_IO_do_write实际上又是new_do_write的包装,同样位于libio/fileops.c文件中,同样借鉴一下上面博主整理的代码,方便阅读,如下所示
static _IO_size_t new_do_write (_IO_FILE *fp, const char *data, _IO_size_t to_do) { ... _IO_size_t count; if (fp->_flags & _IO_IS_APPENDING) fp->_offset = _IO_pos_BAD; else if (fp->_IO_read_end != fp->_IO_write_base) { _IO_off64_t new_pos = _IO_SYSSEEK (fp, fp->_IO_write_base - fp->_IO_read_end, 1); if (new_pos == _IO_pos_BAD) return 0; fp->_offset = new_pos; } // 调用函数输出输出缓冲区 count = _IO_SYSWRITE (fp, data, to_do); //最终输出 ... return count; }
同样类似于_IO_new_file_overflow,而我们想要的及时调用的_IO_SYSWRITE,中间的变化到会导致一些不可控的因素,因此我们需要让两个判断都不成立即可。如果我们要让第二个不成立,根据网络资料,程序可能会崩溃,因此我们选择进入第一个判断,也就是让fp->offset & _IO_IS_APPENDING !=0即可。最后总结即可知,实际上打印的数据地址是fp->_IO_write_base,并且f->_flags需要满足如下条件
f->_flags必须包含魔数(结构体注释)
f->_flags & _IO_NO_WRITES = 0 f->_flags & _IO_CURRENTLY_PUTTING != 0 f->_flags & _IO_IS_APPENDING != 0
其各个宏常量定义在libio/libio.h文件中,最后我们可以得出f->_flags字段的值
#define _IO_MAGIC 0xFBAD0000 /* Magic number * #define _IO_NO_WRITES 8 /* Writing not allowd */ #define _IO_CURRENTLY_PUTTING 0x800 #define _IO_IS_APPENDING 0x1000 f->_flags = (~_IO_NO_WRITES) | (_IO_CURRENTLY_PUTTING) | (_IO_IS_APPENDIGN) =0xfbad0000 | 0x800 | 0x1000 & (0xfffffff7) = 0xfbad1800
因此,如果我们修改了stdout的flags和_IO_write_base成员,并且将_IO_write_base减小,则根据上面源代码易知,我们将输出_IO_write_base地址,长度为_IO_write_ptr-_IO_write_base个字节的信息,从而会输出多一些的相关信息,这中间很容易包含glibc地址。
下面说一下常用的地址泄露用法——如果我们要泄露地址,则一定需要要输出函数,这里就是puts函数,因此我们需要修改stdout对应的IO_FILE结构,也就是我们需要修改stdout的flags和_IO_write_base结构,从而获取glibc的地址。那么我们通常会在stdout地址附近,构造一个fake chunk并分配,从而可以修改stdout对应的结构体,完成地址泄露。
我们首先gdb观察一下stdout附近有没有现成的fake chunk,从而方便进行分配,如下所示
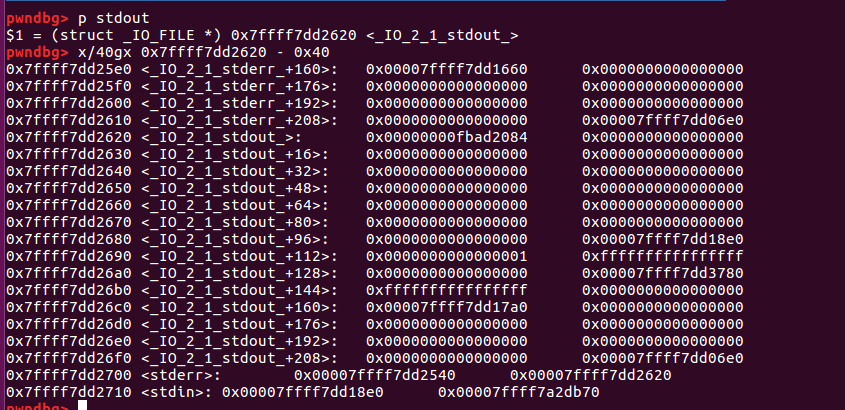
可以看到,貌似在0x7ffff7dd25e0(具体地址根据实际调试情况而定)处可以有伪造的chunk,这里看起来不太方便,我们更换成熟悉的chunk,如下所示
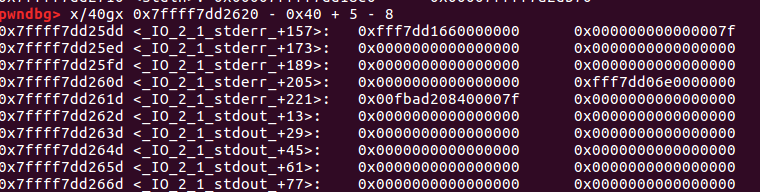
这样子的话,就非常像一个chunk了,也不用担心万一不同电脑不一样怎么办,因为实际上这里是固定存在的(具体数值可能不太一样而已)。除此之外,我们注意到该fake chunk的大小字段的值为0x7f,这并不是一个很理想的值——因为一般chunk分配比较大小的时候,不考虑第三位,都是0x10对齐的(64位),因此这样的话我们不能通过一般unsorted bin进行分配(否则malloc内部比较大小时会不一样),因此我们不妨通过fast bin类型进行分配,因为fast bin比较大小是通过idx,即自动忽略了最后四位,因此这实际上0x7ffff7dd25dd是一个合法的fast bin。
下面的问题就在于如何通过malloc分配到这个fake chunk。一般我们通过修改fast bin的fd字段为该fake chunk的地址,从而获取该fake chunk。但问题就在于我们不知道这个fake chunk的地址,因此我们没有办法直接修改fd字段的值来进行分配。一般遇到这种问题,我们的思路都是通过相对偏移进行解决——如果我们能获取到这个fake chunk附近的地址,我们通过覆盖后几位,从而添加了相对偏移,从而将fd字段的值修正为该chunk即可。实际上,获取该fake chunk周边的地址是非常容易得,因为该fake chunk周边即是main_arena,如图所示
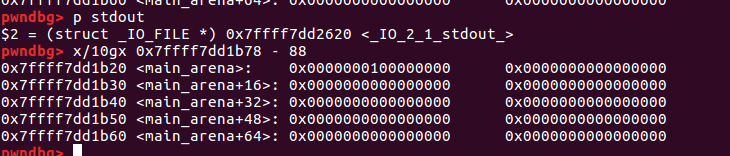
可以看到,实际上仅仅后16比特不同。而虽然main_arena、fake chunk的地址都是变化的,但是根据计算机独有的特性,其内存按照页分配,一个页大小一般是1k,也就是后12比特是固定不变的,因此往往我们只需要爆破一些部分,即可将main_arena的值变换为fake chunk对应的地址。
那么现在的问题重新变换为了如果在fast bin的fd字段获取main_arena周边的地址,实际上这个就是house of Romanhttps://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/house_of_roman-zh/的攻击,这里我简单画图进行示意,方便进行理解。其大体思路如下所示
首先我们申请一个比较大的chunk,确保其释放的时候可以释放到unsorted bin中去,因为根据unsoretd bin的规则,其fd和bk的值就是main_arena附近的值。
然后我们将其释放,确保其释放到unsoretd bin中,而非和top chunk融合,此时其fd字段应该已经为main_arena + 88,这个偏移是固定的,不理解的可以阅读一下malloc分配机制。当然,这个便宜只要不是特别大,是多少都无所谓,因为我们会覆盖掉。结果如下所示
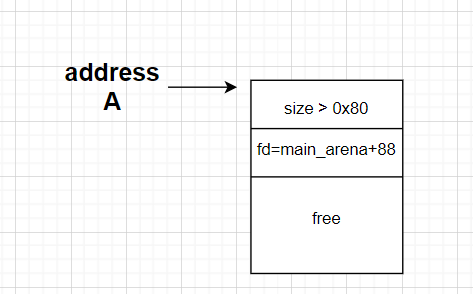
然后我们重新申请相同大小的chunk,这里根据malloc的分配机制,实际上获取的一定是刚刚释放掉的chunk,也就是除了该chunk的fd、bk字段的值进行了修改,其余基本没有什么变化,如图所示
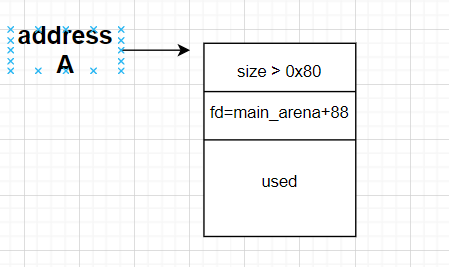
此时,这里需要通过特殊的一些方法(可以是Off By One,可以是UAF等手段)对该chunk进行修改,从而使其成为大小为0x71的free过的fake chunk,并且其fd指向我们想要的stdout附近的那个fake chunk,这样子我们相当于构造了一个假的fast bin链,如果我们将其链接到真的fast bin链上,则基本完成了目标,从而可以修改stdout的结构。如图所示
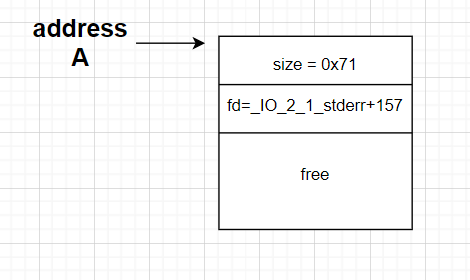
最后我们就是将其链接到真的fast bin上,一般我们通过在创建两个chunk,并且使其连接关系如下,如图所示
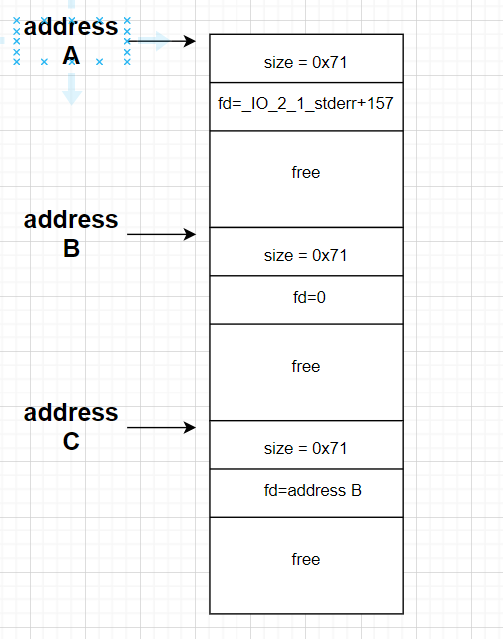
即address C处的chunk->address B处的chunk,一般address A、address B和address C是物理连续的chunk,因此如果我们同样使用一些特殊方法(Off By One、UAF等)技术覆盖掉address C的fd的后几个字节,从而使其指向address A,这样子我们就完成分配一个chunk在stdout附近,从而覆盖掉stdout的成员,完成地址leak。如图所示
最后,假如我们已经成功完成了这些,剩下就是单纯的泄露了,这里给出一下填充的内容模板,如下所示
def leak(addr): r.send('a' * 51 + p64(0xfbad1800) + p64(0) * 3 + p64(addr))
这里稍微解释一下,其中51是根据前面fake chunk和stdout的间隔计算出来的,如下所
0x7ffff7dd2620 - 0x7ffff7dd25dd - 0x10 = 51
而后面的填充是根据stdout数据结构的偏移决定的,如下所示
truct _IO_FILE { int _flags; /* High-order word is _IO_MAGIC; rest is flags. */ #define _IO_file_flags _flags /* The following pointers correspond to the C++ streambuf protocol. */ /* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */ char* _IO_read_ptr; /* Current read pointer */ char* _IO_read_end; /* End of get area. */ char* _IO_read_base; /* Start of putback+get area. */ char* _IO_write_base; /* Start of put area. */ ... }
这里p64(0xfbad1800)对应的是_flags,其余三个p64(0)对应的是_IO_read_ptr、_IO_read_ptr和_IO_read_base。这里唯一可能的问题在于为什么int类型的_flags对应的是64比特——因为字节对齐,c语言的特性,后边都是64比特的指针,所以这里被迫对齐到64比特,其余就没什么了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号