解决 Python 的字符串 center ljust rjust 在面对中文时的 bug
方法一:修改内置 str 的方法,能更灵活的定制,更准确地判断 CJK 字符,全局有效。甚至还能把转义序列也兼容了。
def modify_str():
import gc, ctypes
def curse(klass, attr, value):
"""
这里用的是 forbiddenfruit 库的 curse 简化了一下,省去了下载第三方库
用于修改内置 class 的属性
"""
dikt = gc.get_referents(klass.__dict__)[0]
old_value = dikt.get(attr, None)
old_name = '_c_%s' % attr
dikt[attr] = value
if old_value:
dikt[old_name] = old_value
dikt[attr].__name__ = old_value.__name__
dikt[attr].__qualname__ = old_value.__qualname__
ctypes.pythonapi.PyType_Modified(ctypes.py_object(klass))
CJK_CHARACTERS = [ # 定义 CJK 字符的区间
(0x3400, 0x4DB5), # CJK Unified Ideographs Extension A
(0x4E00, 0x9FA5), # CJK Unified Ideographs
(0x9FA6, 0x9FBB), # CJK Unified Ideographs
(0xF900, 0xFA2D), # CJK Compatibility Ideographs
(0xFA30, 0xFA6A), # CJK Compatibility Ideographs
(0xFA70, 0xFAD9), # CJK Compatibility Ideographs
(0x20000, 0x2A6D6), # CJK Unified Ideographs Extension B
(0x2F800, 0x2FA1D), # CJK Compatibility Supplement
(0xFF00, 0xFFEF), # 全角ASCII、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母
(0x2E80, 0x2EFF), # CJK部首补充
(0x3000, 0x303F), # CJK标点符号
(0x31C0, 0x31EF), # CJK笔划
(0x2F00, 0x2FDF), # 康熙部首
(0x2FF0, 0x2FFF), # 汉字结构描述字符
(0x3100, 0x312F), # 注音符号
(0x31A0, 0x31BF), # 注音符号(闽南语、客家语扩展)
(0x3040, 0x309F), # 日文平假名
(0x30A0, 0x30FF), # 日文片假名
(0x31F0, 0x31FF), # 日文片假名拼音扩展
(0xAC00, 0xD7AF), # 韩文拼音
(0x1100, 0x11FF), # 韩文字母
(0x3130, 0x318F), # 韩文兼容字母
(0x1D300, 0x1D35F), # 太玄经符号
(0x4DC0, 0x4DFF), # 易经六十四卦象
(0xA000, 0xA48F), # 彝文音节
(0xA490, 0xA4CF), # 彝文部首
(0x2800, 0x28FF), # 盲文符号
(0x3200, 0x32FF), # CJK字母及月份
(0x3300, 0x33FF), # CJK特殊符号(日期合并)
(0x2700, 0x27BF), # 装饰符号(非CJK专用)
(0x2600, 0x26FF), # 杂项符号(非CJK专用)
(0xFE10, 0xFE1F), # 中文竖排标点
(0xFE30, 0xFE4F), # CJK兼容符号(竖排变体、下划线、顿号)
]
CJK_CHARACTERS.sort()
CJK_CHARACTERS_LIST = [a for tup in CJK_CHARACTERS for a in tup]
def char_width(char):
'''按一个 CJK 占两个宽度算,返回字符宽度'''
unicode = ord(char)
if unicode < CJK_CHARACTERS_LIST[0]:
return 1
for index, item in enumerate(CJK_CHARACTERS_LIST):
if unicode < item: break
if index % 2:
return 2
return 1
def calculate(string):
'''字符串总宽度'''
return sum([char_width(char) for char in string])
import re
csi_pattern = re.compile("(?:\x9b|\033\[)\d*(?:;\d*)*[A-Za-z]") # 用于匹配转义序列
# 重新定义 str 的三个方法:
def center(self: str, width, *args, **kwargs):
width += sum([len(csi) for csi in csi_pattern.findall(self)]) # 加上转义序列的补偿
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'center')(width, *args, **kwargs)
def ljust(self: str, width, *args, **kwargs):
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'ljust')(width, *args, **kwargs)
def rjust(self: str, width, *args, **kwargs):
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'rjust')(width, *args, **kwargs)
curse(str, 'center', center)
curse(str, 'ljust', ljust)
curse(str, 'rjust', rjust)
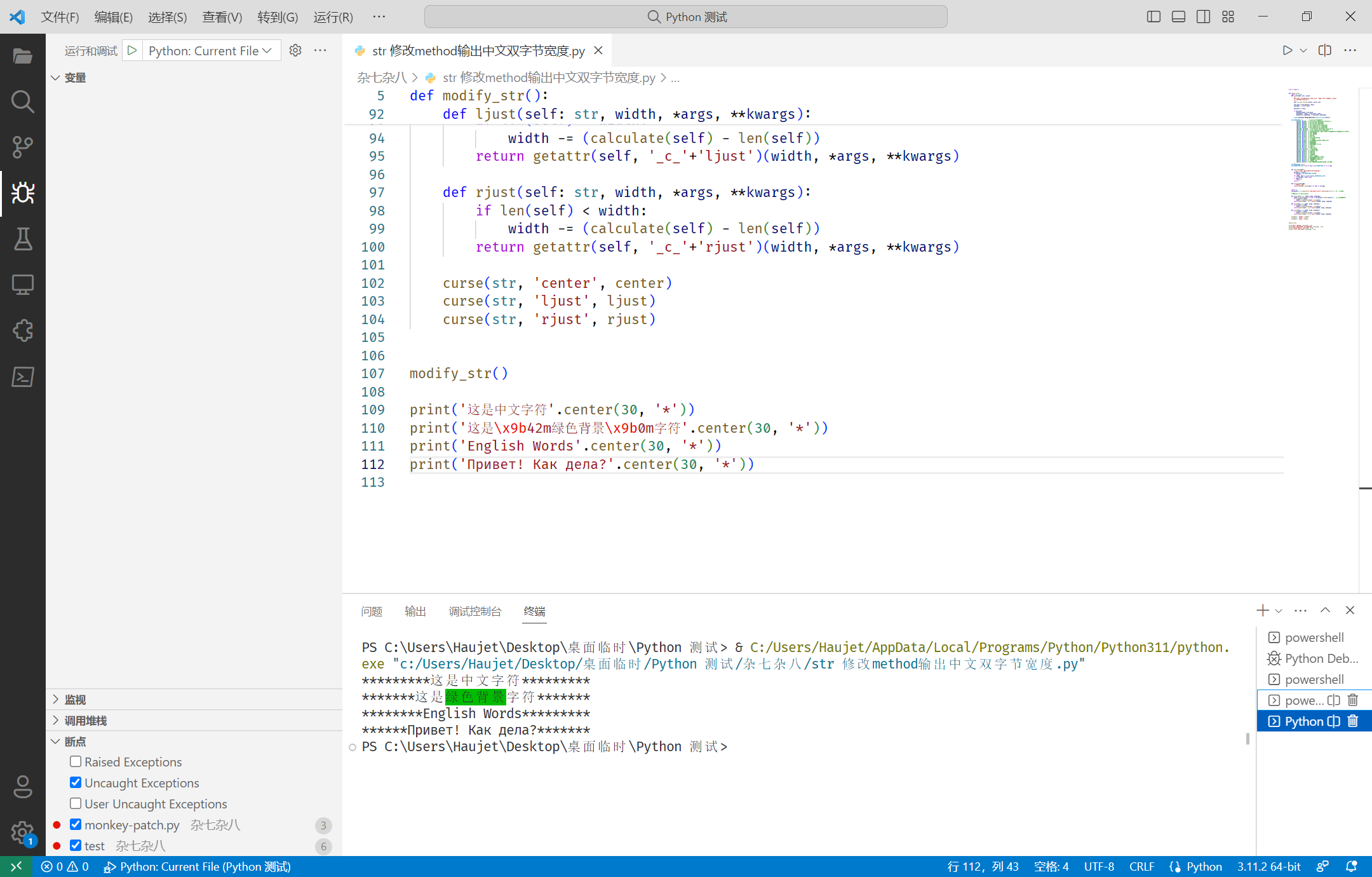
modify_str()
print('这是中文字符'.center(30, '*'))
print('这是\x9b42m绿色背景\x9b0m字符'.center(30, '*'))
print('English Words'.center(30, '*'))
print('Привет! Как дела?'.center(30, '*'))
方法二:先用 gbk 编码,调整后,再解码。局限性较大,不能准确判断 CJK 符号,不易兼容其它国家的语言。
# 一般中文宽度是英文的两倍,带有中文的字符串使用 center ljust rjust 会出现宽度非常不一致
# 我们希望中文可以按两个宽度计算
# 可以利用 gbk 是双字节编码,中文字符占2字节,英文字符占1字节
# 将字符串用 gbk 编码后,再用 center ljust rjust,最后用 gbk 解码,就可以得到视觉上中英文一致的宽度
# 需要注意的是,有一些偏僻字使用 gbk 是无法编码的,例如:𠜎
print('\x9b42m 展示 \x9b0m')
print('这是中文字符'.encode('gbk').center(30, b'*').decode('gbk'))
print('English Words'.encode('gbk').center(30, b'*').decode('gbk'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号