
【CUDA】CUDA C入门、简单介绍
CUDA编程注意事项
CUDA中不能在主机代码中对cudaMalloc()返回的指针进行解引用。
- 可以将cudaMalloc()分配的指针传递给在设备上执行的函数。
- 可以在设备代码中使用cudaMalloc()分配的指针进行内存读/写操作。
- 可以将cudaMalloc()分配的指针传递给在主机上执行的函数。
- 不能在主机代码中使用cudaMalloc()分配的指针进行内存读/写操作。
CUDA运行模式
- CPU传给GPU数据
- GPU计算
- GPU传给CPU结果
详细一点:
- 给GPU设备分配内存
cudaMalloc((void**)&dev_input, sizeof(int)));
cudaMalloc((void**)&dev_result, sizeof(int)));
-
在CPU上为输入变量赋初值 input
-
CPU将输入变量传递给GPU
cudaMemcpy(dev_input, input, sizeof(int), cudaMemcpyHostToDevice);
- GPU对输入变量进行并行计算——核函数
kernel_function<<<N,1>>>(dev_input, dev_result);
其中,N表示设备在执行核函数时使用的并行线程块的数量。
例如,若指定的事kernel<<<2,1>>>(),那么可以认为运行时将创建核函数的两个副本并且并行方式运行。每个并行执行环境就是一个线程块(Block)。而所有的并行线程块集合称为一个线程格(Grid)。另外注意,线程块数组每一维的最大数量都不能超过65535。
问题:如果在代码中知晓正在运行的是哪个线程块?
答:利用内置变量blockIdx(二维索引)。例如:
int tid = blockIdx.x; //计算位于这个索引处的数据。
- GPU将计算结果传回给CPU
cudaMemcpy(result, dev_result, sizeof(int), cudaMemcpyDeviceToHost);
- 释放在GPU上分配的内存
cudaFree(dev_input);
cudaFree(dev_result);
CUDA有趣示例
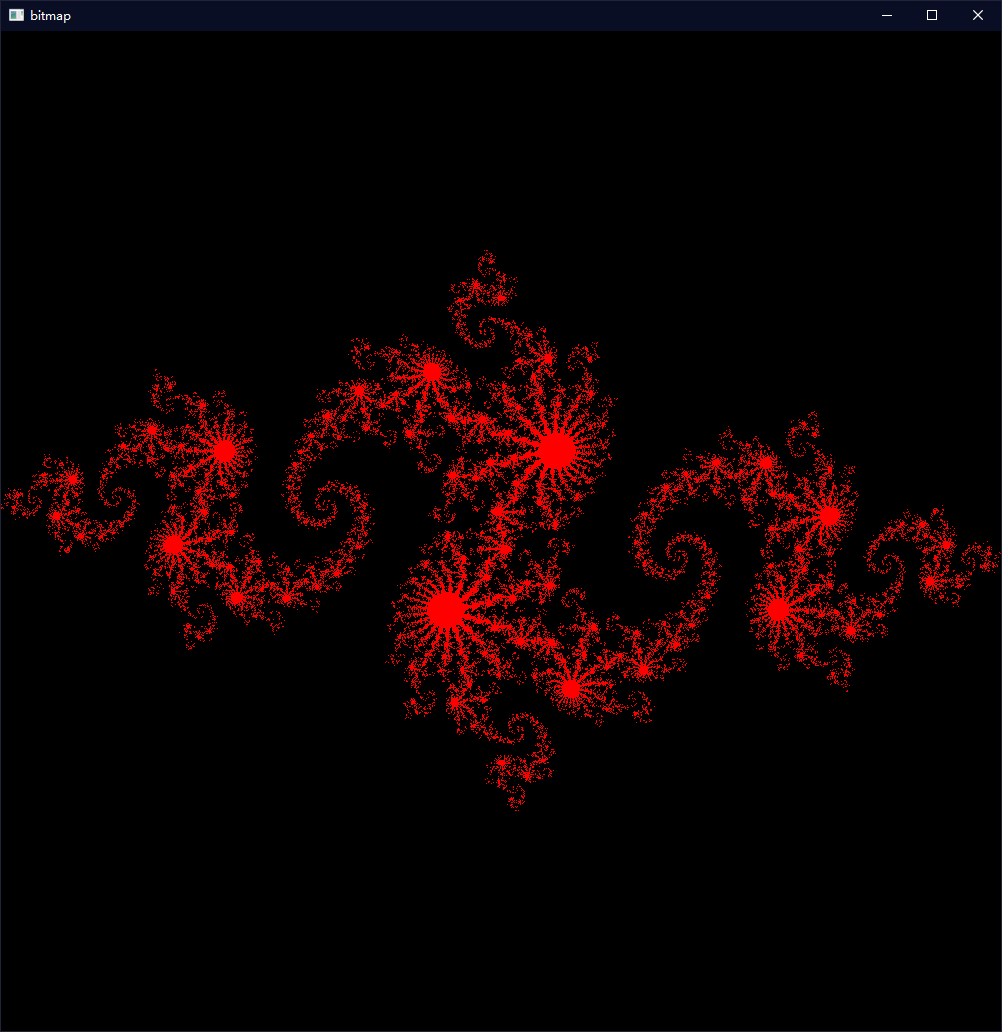
下面放一个实例,是绘制Julia集曲线的例子,需要提前下载好一些cuda官方的头文件,链接在此。代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Projects_CUDA\cuda_by_example\common\cpu_bitmap.h" //这里换成你自己的cuda_by_example路径
#include "D:\Projects_CUDA\cuda_by_example\common\book.h" //这里换成你自己的cuda_by_example路径
#include <stdio.h>
using namespace std;
#define DIM 1000
struct cuComplex{
float r;
float i;
__device__ cuComplex(float a, float b){
r = a;
i = b;
}
__device__ float magnitude2(void) {
return r * r + i * i;
}
__device__ cuComplex operator * (const cuComplex& a){
return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
}
__device__ cuComplex operator + (const cuComplex& a){
return cuComplex(r + a.r, i + a.i);
}
};
__device__ int julia(int x, int y){
const float scale = 1.5;
float jx = scale * (float)(DIM / 2 - x) / (DIM / 2);
float jy = scale * (float)(DIM / 2 - y) / (DIM / 2);
cuComplex c(-0.8, 0.156);
cuComplex a(jx, jy);
int i = 0;
for (i = 0; i < 200; i++){
a = a * a + c;
if (a.magnitude2() > 1000)
return 0;
}
return 1;
}
__global__ void kernel(unsigned char *ptr){
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
int juliaValue = julia(x, y);
ptr[offset * 4 + 0] = 255 * juliaValue;
ptr[offset * 4 + 1] = 0;
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
struct DataBlock {
unsigned char *dev_bitmap;
};
int main(void){
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grid(DIM, DIM);
kernel << <grid, 1 >> >(dev_bitmap);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
HANDLE_ERROR(cudaFree(dev_bitmap));
}
运行结果(美炸了):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号