论文查重
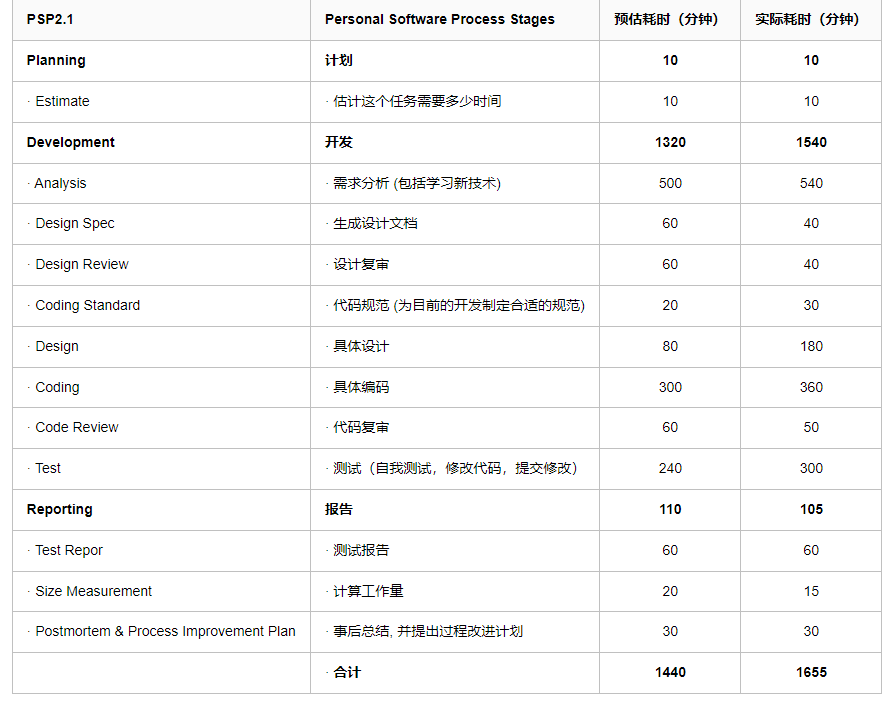
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
| ----------------- | --------------- |
| 这个作业要求在哪里|https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 |论文查重 |
代码链接:https://github.com/lTsasa/PlagiarismDetection/tree/main/3122004618
代码组织
主类 (Main): 负责读取命令行参数,调用查重逻辑,并输出结果。
关键函数与流程图
关键函数
cut(String text): ik分词器完成分词
buildFrequencyVector(List
calculateCosineSimilarity(int[] vector1, int[] vector2): 计算两个文本字符串的相似度,返回相似度百分比。
流程图
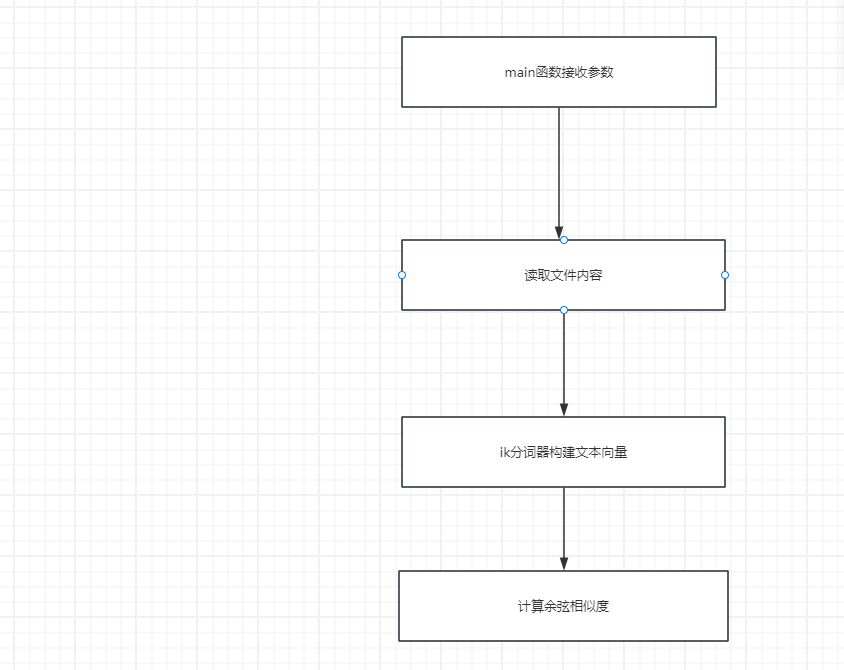
开始
解析命令行参数
读取原文文件路径
读取抄袭版文件路径
读取输出文件路径
读取原文和抄袭版内容
调用 calculateCosineSimilarity
计算相似度
写入结果到文件
使用 Writer 将相似度百分比写入输出文件
结束
算法关键与独到之处
算法选择:余弦相似度算法
独到之处:通过分词进行词语的向量构建并算出余弦相似度
性能改进思路
在信息检索领域,修正余弦相似度可以用于计算查询和文档之间的相似度。由于文档的长度和查询的长度通常差异很大,直接使用余弦相似度可能会导致不准确的结果。通过修正余弦相似度,可以消除这种长度差异的影响,提高检索的准确性。
单元测试设计
测试 test:
构造测试数据:包含正常文本文件、空文件、不存在文件的路径。
空文件
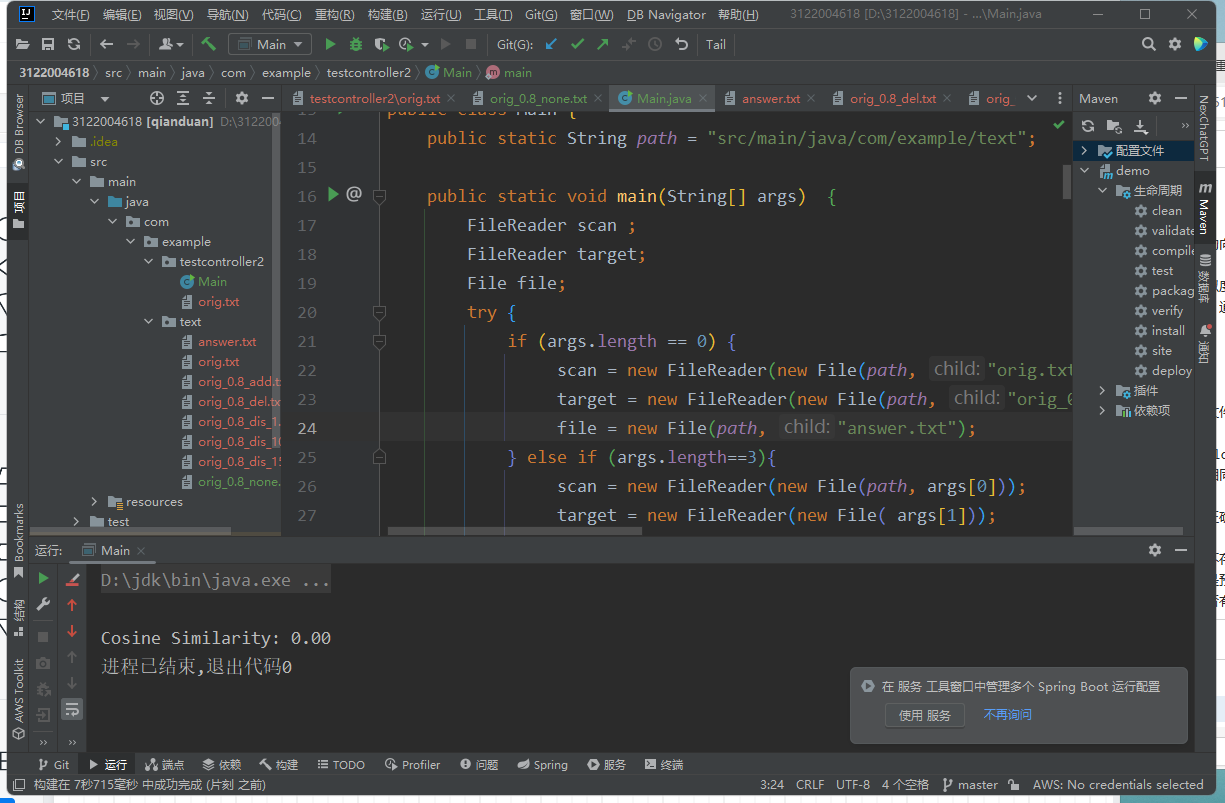
正常文本
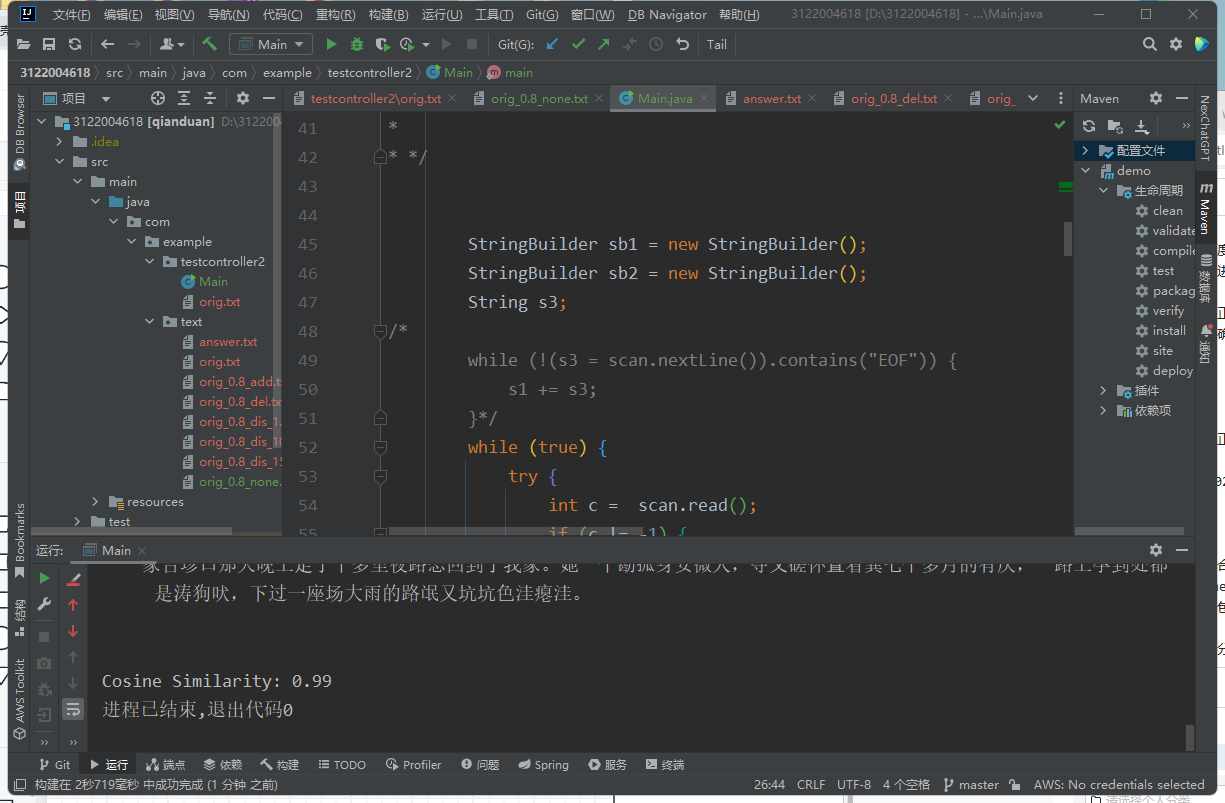
不存在路径
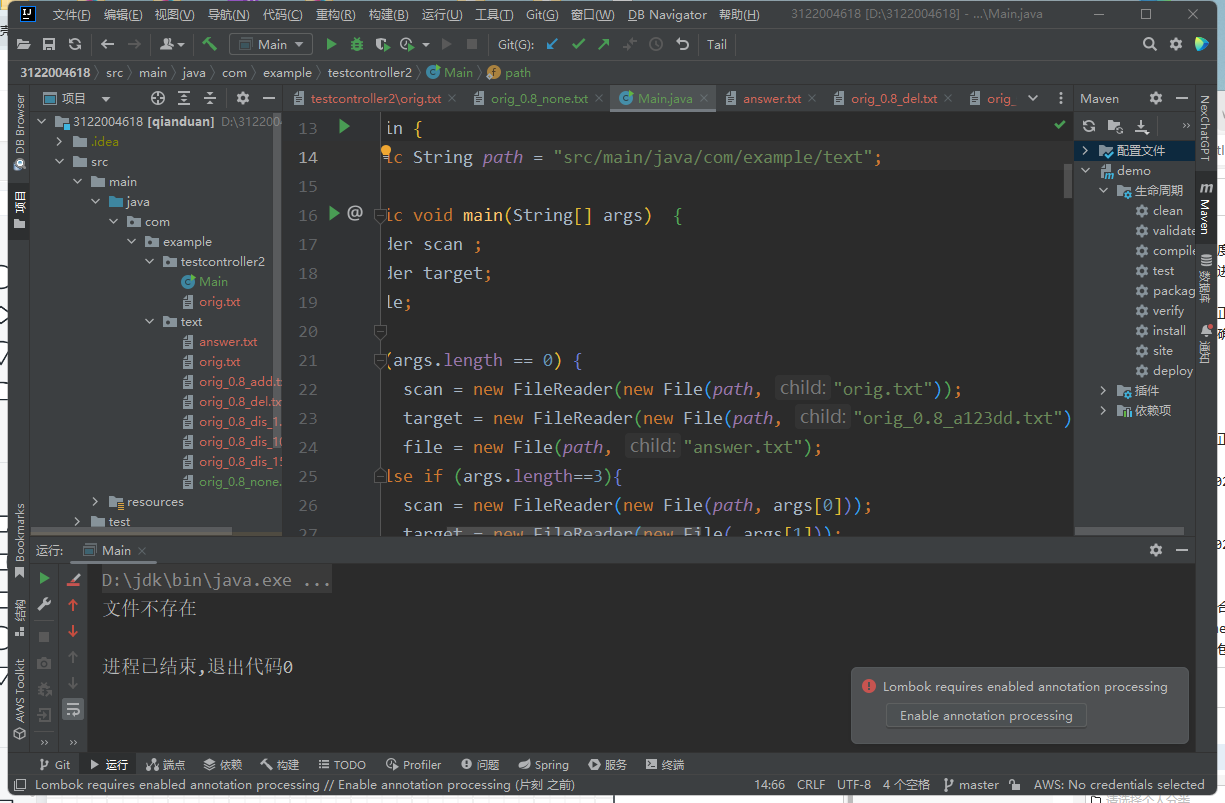
验证返回结果是否符合预期。
测试 SimilarityChecker.calculateSimilarity:
构造多组测试数据,包括完全相同的文本、部分相同的文本、完全不同的文本等。
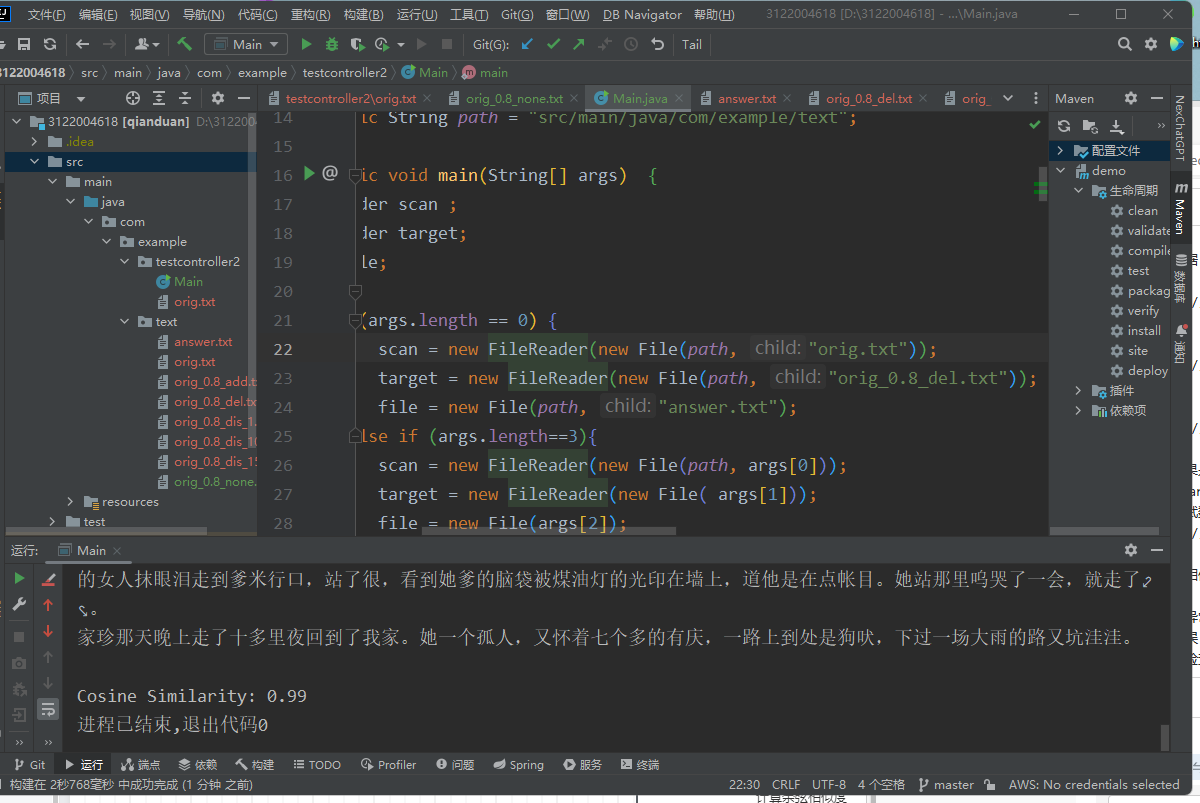
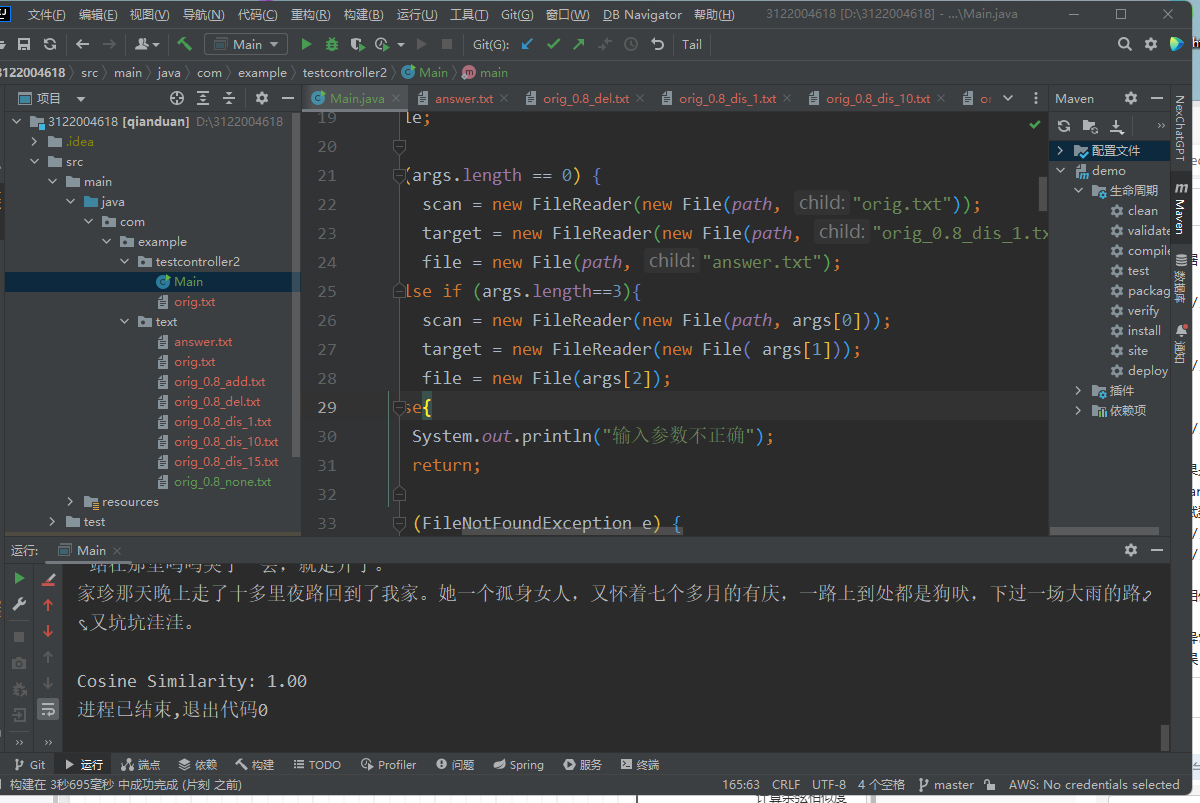

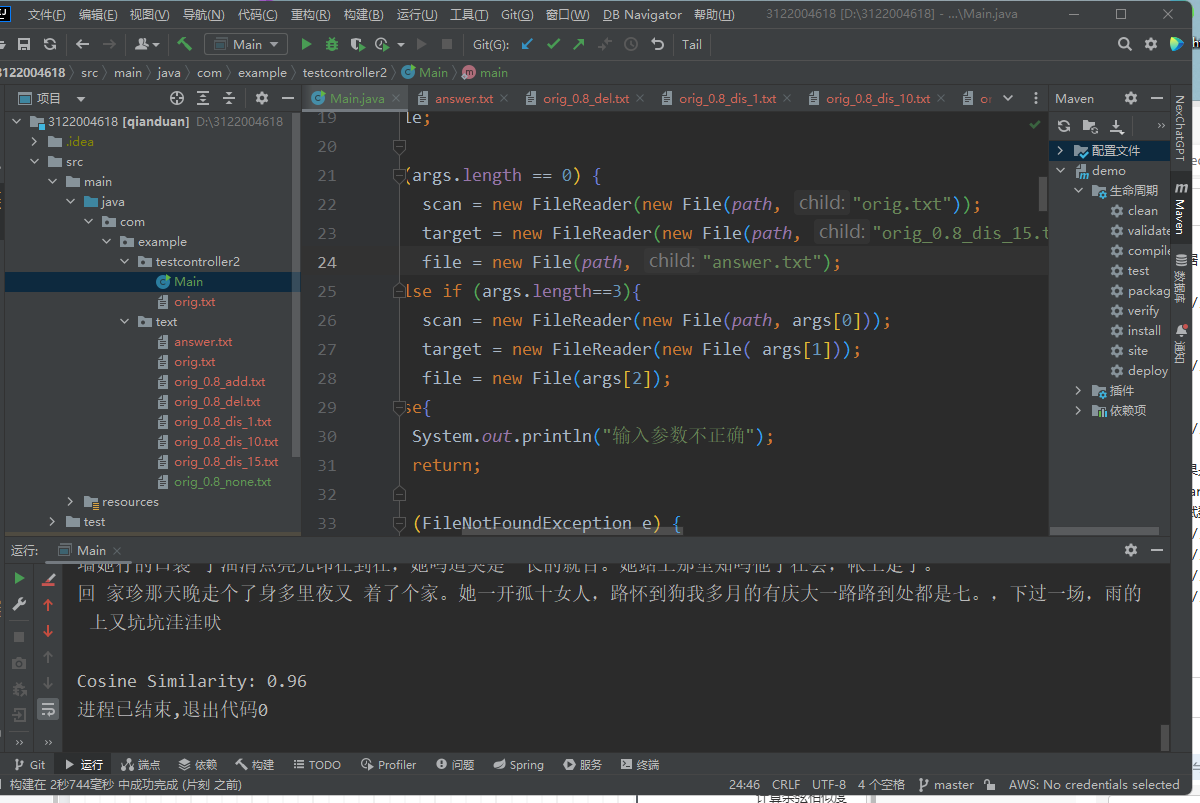
验证返回的相似度百分比是否正确。
异常处理
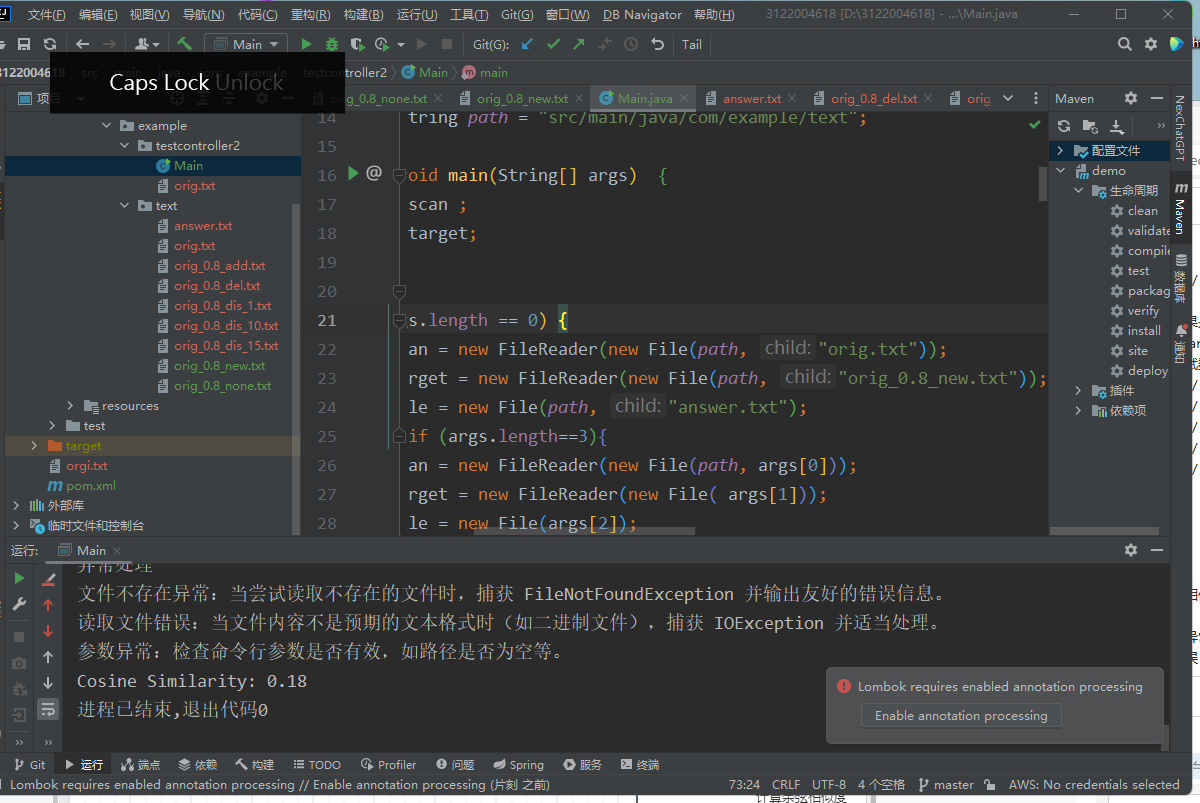
文件不存在异常:当尝试读取不存在的文件时,捕获 FileNotFoundException 并输出友好的错误信息。
读取文件错误:当文件内容不是预期的文本格式时(如二进制文件),捕获 IOException 并适当处理。
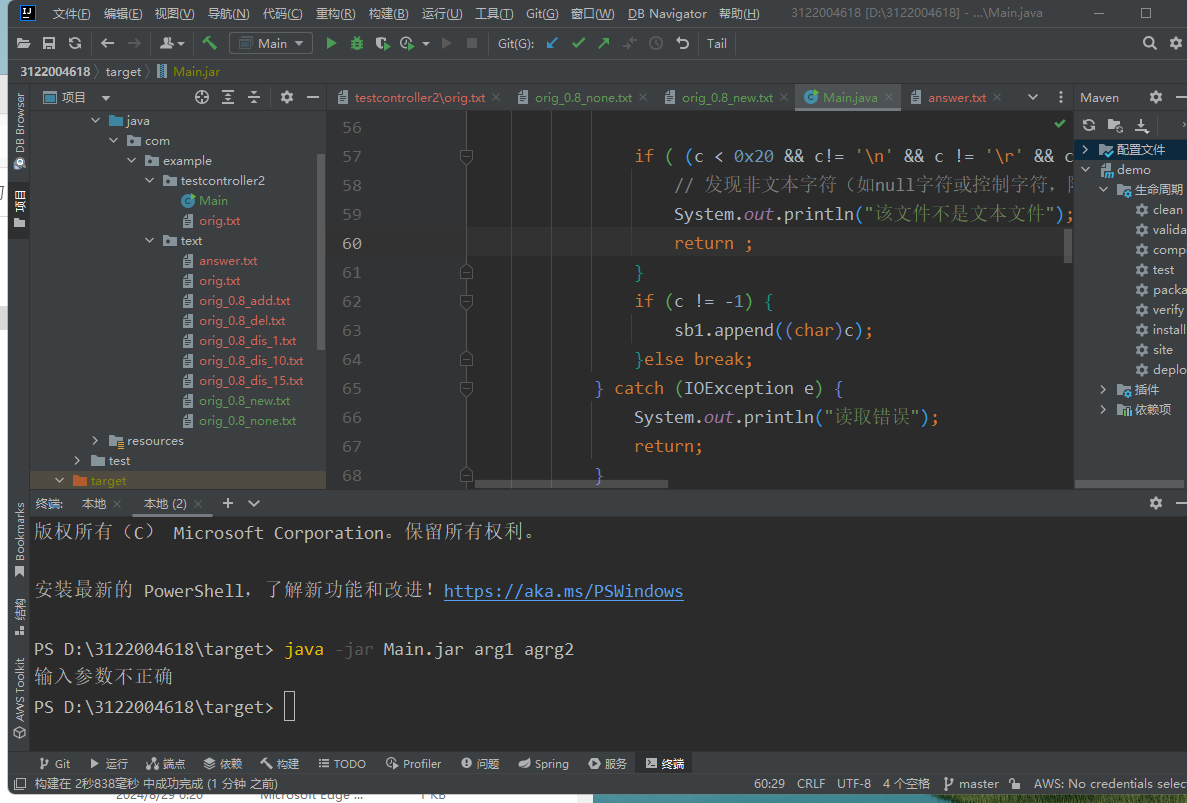
参数异常:检查命令行参数是否有效,如路径是否为空等。
我这里做了无参数的默认使用参数
这是非二进制文件情况

这是参数不合理情况
无警告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号