聚集索引和非聚集索引
在讲聚集索引和非聚集索引之前我们先要了解下什么是索引,想要理解索引的原理我们必须了解一种数据结构「平衡树」(非二叉)。当然也有数据库使用哈希桶做数据索引,但是目前主流都以平衡树(B-Tree索引、B+Tree索引)作为数据的默认索引;
索引
以B+Tree索引是B+Tree在数据库的一种实现方式,也是目前在数据库中使用最频繁的一种索引。B+Tree是从二叉树演化而来,所以在此之前我们必须要先了解二叉查找树、平衡二叉树(AVLTree)和多路平衡查找树(B-Tree);
二叉查找树
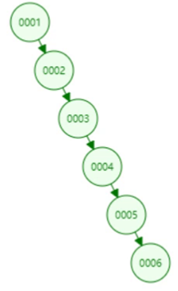
二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。二叉树的搜索相当于一个二分查找。二叉查找能大大提升查询的效率,但是它有一个问题:二叉树是以第一个插入的数据作为根节点,同样的一组数据可能因为顺序不同产生线性链表结构,如下图;
平衡二叉树
为了解决二叉树左右不平衡的问题就有了平衡二叉树,定义是节点的子节点高度差不能超过1,如果因为数据的增删查改导致不平衡则可以通过左旋或右旋解决,但是单单的左右平衡并不能满足数据库库索引的需要;
1、首先树结构中,数据深度决定了检索是的IO次数;
2、查询事件的不稳定导致,有时只需一次IO就查询出数据,而有时则需多次IO才可以;
3、没有利用操作系统和磁盘数据交换的特性以及磁盘的IO预读能力,正常来说操作系统和磁盘间的数据交换是以页(4KB)为单位,也就是说一次数据交换会加载4KB的数据到内存,而平衡二叉树的一个节点只有一个关键词,而这样的IO的操作次数又因为树的高度需要重复多次,极大的浪费系统的性能;
多路平衡二叉树(B-Tree)
首先先有个概念,系统从磁盘读取数据到内存时是以磁盘块为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。其次这里以InnoDB举例,在InnoDB存储引擎中有页(page)的概念,即磁盘管理的最小单位默认是16KB。而往往系统磁盘不可能分配给用户一个完整连续磁盘空间,而是通过多个磁盘块拼接而成,而B-Tree就是了让系统高效的检索磁盘块,通过键值对的形式保存数据;

每个节点占用一个磁盘块,由N个升序关键字和N+1个指针(对应子节点磁盘块地址),如果以上述表结构为例,我们最多只需三次IO操作和内存操作就能获取结果,而且由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,相较于B-Tree有几点不同:
1、非叶子节点只存储键值信息;
2、所有叶子节点之间都有一个链指针;
3、数据记录都存放在叶子节点中;

1、B+Tree是B-Tree的变种,所以B-Tree能解决的问题,B+Tree也能够解决;
2、B+Tree扫库和扫表能力更强,如果我们要根据索引去进行数据表的扫描,对B-Tree进行扫描,需要把整棵树遍历一遍,而B+Tree只需要遍历他的所有叶子节点即可;
3、B+Tree磁盘读写能力更强,因为根节点和支节点不保存数据区,所有根节点和支节点同样大小的情况下,保存的关键字要比B-Tree要多,也就意味着树的高度相对较低,IO的操作更少;
4、B+Tree排序能力更强,叶子节点之间天然具有排序功能;
5、B+Tree查询效率更加稳定,每次查询数据的IO次数一定是相同的;
聚集索引
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
回到我们的索引上来,我们平时在建表的时候都会为其加上主键,有的数据库中如果不指定主键是无法建表的。但是事实上一个加了主键的表并向我们认知中的「表」,而一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引,也就是所谓的「聚集索引」,这也是为什么一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
对于聚集索引来说整张数据表就是平衡树,所以利用其特性,极大的优化数据查询效率。但是凡事都有两面性索引虽然为查询效率带来的提升,但是却严重影响数据修改的效率。因为每次数据的修改都会破坏树结构,为了确保平衡树的结构维持在正确的状态,每次修改操作后都需要重新梳理树结构,这就为系统性能上造成不小的开销,InnoDB存储引擎就是使用了聚合索引。
非聚集索引
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
非聚集索引,也就是我们平时经常提起和使用的常规索引,非聚集索引和聚集索引一样,同样是采用平衡树作为索引的数据结构。但是通俗的来讲非聚集索引数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。如果给表中多个字段加上索引,那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。每次给字段建一个新索引,字段中的数据就会被复制一份出来, 用于生成索引。 因此给表添加索引会增加表的体积, 占用磁盘存储空间,非聚集索引和聚集索引的区别在于, 通过聚集索引可以直接查到需要查找的数据, 而通过非聚集索引可以查到记录对应的磁盘地址, 再磁盘地址找到需要的数据。
总结
1、使用聚集索引的查询效率要比非聚集索引的效率要高,但是写入性能并不高。因为如果需要频繁去改变聚集索引的值,则需要移动对应数据的物理位置;
2、非聚集索引在查询的时候可以的话就避免二次查询,这样性能会大幅提升;
3、不是所有的表都适合建立索引,只有数据量大表才适合建立索引,且建立在选择性高的列上面性能会更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号