从01背包问题到动态规划
前言
动态规划(Dynamic Programming,简称DP),一个让很多初学者望而却步的词语。因为相较于各类排序算法、二叉树遍历算法、以及贪心、回溯算法等,动态规划要更为抽象,它没有模板或者范式,我们不能依靠简单的依葫芦画瓢来解决动态规划问题。它提供的是一种解决问题的思路,“态”指的是对问题状态的设计,“动”指的是状态的转移,所以解决动态规划问题的关键就是对于问题状态转移的抽象,现在不理解没有关系,我们接着往下看。
贪心法的缺陷
贪心法是最符合人类直觉的算法,长期的生活经验也证明贪心法大多数情况下是可靠的,比如找零问题:假设一个商品的价格为173元,现在你有100、50、20、10、5、1元的货币若干张,问如何才能用最少张数的货币付清货款。这个问题,就算是小学二年级的学生也能很快找到最优解:
100元一张、50元一张、20元一张、1元三张。
在思考时,我们会优先考虑面额最大的100,不足100时,再考虑50,然后20、10……。这就是典型的贪心思路,优先考虑当前的最优解,从当前子问题的最优解逐步推向总问题的最优解。
再来看这个问题:你饿了,跑到某快餐店吃饭,现在有五款商品,他们的金额和份量如下:
| 价钱 | 份量 | |
| 窜稀汉堡 | 10元 | 24 |
| 油腻鸡块 | 4元 | 9 |
| 炸糊薯条 | 4 | 9 |
| 淀粉卷 | 5 | 10 |
| 兑水可乐 | 3 | 2 |
现在你的花呗只有13元额度了,你会选择怎么吃这一顿才能获得最大份量的满足(每种商品只能点一份)。依照贪心算法,我们分别计算出每种食物的性价比(份量/价钱):窜稀汉堡2.4,油腻鸡块2.25,炸糊薯条2.25,淀粉卷2,兑水可乐0.67。现在优先选择性价比最高的窜稀汉堡,还剩3元,还能买一份兑水可乐,这样我们套餐的份量是24+2=26。但如果你今年是小学二年级以上,那么你可能会得到另外的答案:油腻鸡块+炸糊薯条+淀粉卷的套餐,份量总和是9+9+10=28。
没错,贪心法这里出问题了。在选择套餐时贪心法的策略是优先选择能够提供份量最大的窜稀汉堡,这本来没有什么问题,但是这样做的后果是,剩下的3元我们只能够买一份性价比超低的兑水可乐,所以贪心法的问题就是:只考虑眼前的情况,而不去管他对后续问题的影响。
求解思路
对于这类问题,我们当然可以暴力枚举出所有套餐的组合,然后对比选择份量最高的套餐,但是当你的额度足够多,商品种类也足够多时,这样去遍历的时间显然是不能承受的。因为存在大量的重复计算,同时,像一些明显不可能的套餐也会去尝试,比如炸糊薯条+淀粉卷+兑水可乐。
现在我们来假设,在套餐内总共已经选了i-1件食物,并且我们的花呗总额度为j。在我们挑选第i件食物时,能获得的最大份量表示为m(i,j),第i件食物的份量为vi,金额为wi。则有以下几种情况:
1.当第i件食物的价钱超过了我们的总额度,那即使把之前选择食物的全部叉掉,也不够买第i件食物,此时能获得的最大份量就是前面i-1件食物提供的份量。即m(i,j)=m(i-1,j),现在我们不用去管m(i-1,j)是怎样计算出来的,只需要知道,依据前面的定义,它能够表示选i-1件食物时,能够获得的最大份量。
2.当第i件食物的价钱没有超过我们的总额度,那么此时有两种策略:
(1)不选择第i件食物,因为它虽然没有超过我们的总额度,但是如果要选择第i件食物可能就不得不放弃一些之前的食物。此时,m(i,j)=m(i-1,j)
(2) 嗯要选第i件食物,那么相当于只有j-wi的额度分配给之前的i-1件食物,此时,m(i,j)=m(i-1,j-wi)+vi
此时,能获得的最大份量就需要去衡量上面两种情况,然后取最大值。
依据上面的结论,我们能得到这样一个表达式:
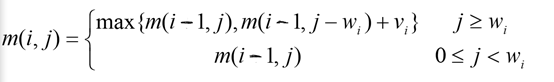
这里的难点在于,要用j表示总额度,而不是剩下的额度。因为我们在选择第i件食物时,如果用剩余额度去考量,那就代表默认前面i-1件食物我们必须选择。然而事实上如果第i件食物的性价比足够高,我们完全可以取消一部分前面选择的食物,转而去选择第i件食物,只要它不超出我们的总额度就行。每一件食物我们都可以选择要或不要,所以这里需要用总额度去考量。
状态转移方程
经过上面的推导,我们写出了m(i,j)的表达式,其实这个就叫做状态转移方程。仔细观察可以发现,我们在求解本阶段的问题m(i,j)时,用到了上一阶段的结果m(i-1,j)。本阶段的状态是上一阶段状态和上一阶段决策的结果,本阶段的状态与上一阶段的状态之间存在的关系,用函数的形式表达出来,就是状态转移方程。
而所谓的动态规划,就是对于问题状态的抽象,以及状态之间数量关系的建立。
在动态规划问题中,只要写出状态状态转移方程,那么问题也就基本解决了,剩下的就是代码实施了。
动态规划的特征
“把一个大问题,拆分成若干子问题,由子问题的解最后推导出大问题的解”。这种描述虽然没错,但是太过于空洞了,像分治策略、递归算法、包括前面提到的贪心算法等等,其实都满足这种特征。不同的地方在于,它们对于子问题的划分策略,以及子问题的性质。而动态规划,必须满足以下两个特征:
1.最优化原理(最优子结构性质) :一个最优化策略具有这样的性质,不论过去状态和决策如何,对前面的决策所形成的状态而言,余下的诸决策必须构成最优策略。简而言之,一个最优化策略的子策略总是最优的,也就是划分出来的子问题必须是求解当前状态的最优解。一个问题满足最优化原理又称其具有最优子结构性质。例如在前面的问题中,我们注意力始终是放在选第i件食物时能达到的最大份量。
2.无后效性:对于某个给定的阶段状态,它以前各阶段的状态无法直接影响它未来的决策,而只能通过当前的这个状态。换句话说,每个状态都是过去历史的一个完整总结。例如,求解m(i,j)时,我们会用到m(i-1,j),但是m(i-1,j)的具体值和计算过程并不会影响我们对m(i,j)的决策,这也是为什么j要用总额度而不是剩余额度的原因,因为如果是剩余额度,那么前面选取的食物毫无疑问会影响我们后面的决策,就像一开始如果就选择了窜稀汉堡,那么后面就只能选择兑水可乐了。
如果我们将大问题拆分成小问题后,如果小问题同时满足无后效性与最优子结构性质,那么这个问题就可以使用动态规划思路求解。
代码实施
动态规划问题的代码实施大致可分为三种方式:1.递归 2.递推 3.记忆化搜索
(1)递推实现
递推的核心思路就是按照状态转移方程的关系,建立动态规划表,按照关系依次填表,然后取出最大值。在这个题目里核心思路就是建立二维数组,用二维数组模拟表格,依照状态转移方程的关系式,依次填入i与j取不同值时,m(i,j)的值,最后取最大值即可。需要注意边界的初始化,即i=0与j=0时的处理。
#include<iostream> #include <algorithm> using namespace std; int main() { //食物价格 int w[5] = { 10 , 4 , 4 , 5 , 3 }; //食物的份量 int v[5] = { 24 , 9 , 9 , 10 ,2 }; //花呗额度 int huabei=13; //动态规划表,以最大容量初始化,注意这里要初始化边界 int dp[6][14] = { { 0 } }; //最大份量 int maxWeight = 0; for (int i = 1; i <= 5; i++) { for (int j = 1; j <= huabei; j++) { if (j < w[i]) dp[i][j] = dp[i - 1][j]; else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - w[i]] + v[i]); //更新答案 if (dp[i][j]>maxWeight){ maxWeight=dp[i][j]; } } } //输出结果 cout<<maxWeight<<endl; }
(2)纯递归实现
按照经典的递归思路,建立函数m(i,j)表示取第i件食物,总额度为j时,返回最大份量。从食物数组最后一位往前递归,递归的出口为数组下标为-1时,返回0。递归关系按照状态转移方程描述即可。
#include<iostream> #include <algorithm> using namespace std; //食物价格 int w[5] = { 10 , 4 , 4 , 5 , 3 }; //食物的份量 int v[5] = { 24 , 9 , 9 , 10 ,2 }; int wallace(int i,int j){ //递归出口 if (i==-1){ return 0; }else{ if(j<w[i]){ return wallace(i-1,j); }else{ return max(wallace(i-1,j),wallace(i-1,j-w[i])+v[i]); } } } int main() { //输出结果,从价格表的最后一件开始向前递归,花呗额度为13 cout<<wallace(4,13)<<endl; }
(3)记忆化搜索
在说明记忆化搜索的原理之前,先来看一个问题,试着计算1+2+3+4+……+100的和为多少?经过短暂的思考,能计算出结果为5050,那如果再问你1+2+3+4+……+100+101的和为多少,你应该很快就能算出结果为5151。因为1到100的和我们已经计算过了结果为5050,这次就只需要计算5050+101了。
这就是记忆化搜索的原理,也是动态规划的核心思想之一:在需要重复使用子问题的计算结果时,将子问题的答案保存下来,后面就可以直接使用而无需重复计算。
在纯递归实现的过程当中,有一些组合是会被重复计算的,这样会造成时间的浪费。而根据记忆化搜索的原理,我们用一个数组将计算过的组合存取下来,下次如果遇到已经计算过的结果就可以直接返回。从表现上来看,记忆化搜索的实现,像是结合了递推和递归两种方法的优势,利用二维数组,记录下已经计算过的组合,在递归的过程中,如果遇到已经计算过的组合就可以直接返回而无需重新递归,另外,由于递归算法设计了递归的出口,因此也无需对二维数组的边界进行初始化。
#include<iostream> #include <algorithm> using namespace std; //食物价格 int w[5] = { 10 , 4 , 4 , 5 , 3 }; //食物的份量 int v[5] = { 24 , 9 , 9 , 10 ,2 }; //动态规划表,因为函数里有设置递归出口,所以这里不需要初始化边界 int dp[5][13]={0}; int wallace(int i,int j){ //递归出口 if(i==-1){ return 0; } //当需要计算的结果已存在表中,则直接返回表中数据,不需要重复计算 if (dp[i][j]!=0){ cout<<dp[i][j]<<endl; return dp[i][j]; } else{ //递归的同时记录下当前的计算结果,供后面使用 if(j<w[i]){ dp[i][j] = wallace(i-1,j); }else{ dp[i][j] = max(wallace(i-1,j),wallace(i-1,j-w[i])+v[i]); } return dp[i][j]; } } int main() { //输出结果,从价格表的最后一件开始向前递归,花呗额度为13 cout<<wallace(4,13)<<endl; }
使用例
1.DAG最短\长路径问题
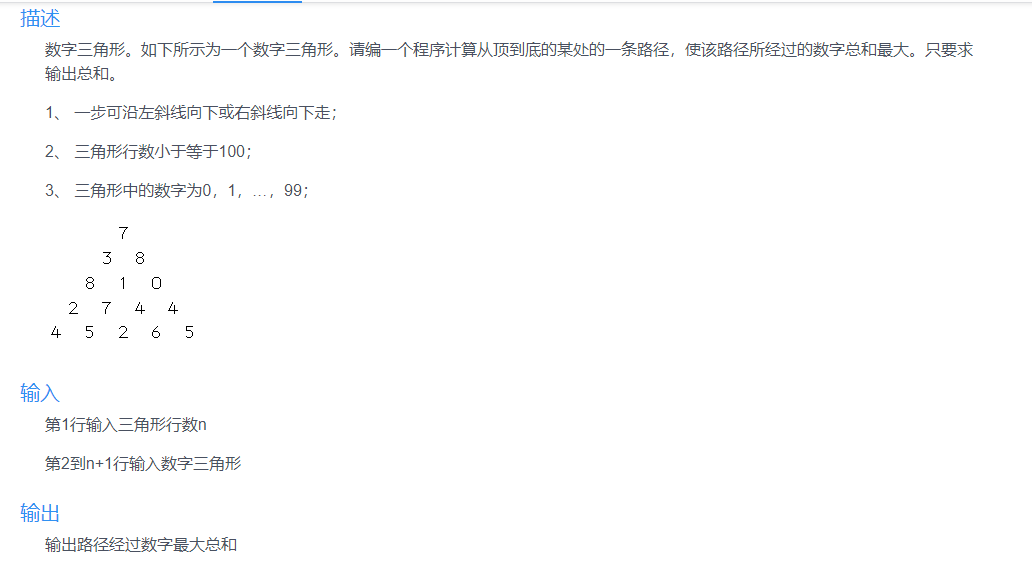
分析:这是一个经典的有向无环图(DAG)求最长路径问题,可以用动态规划思想求解,整体看问题比较复杂,但是对于每一个点,无非是从左上角下来或者是右上角下来,假设用函数f(A)表示到走到点A所用的最长路径,则f(B)=f(A)+A到B的路径。
设m(i,j)表示到达第i层的第j个点时(从1开始计数),所经过的最长路径,a[n][n]表示原始二维数组则有:
1.当i=1时,m(i,j)=a[0][0]
2.当j=1时,只能由右上角的点到达,即m(i,j)=m(i-1,j)+a[i-1][j-1]
3.当j=i时,只能由左上角的点到达,即m(i,j)=m(i-1,j-1)+a[i-1][j-1]
4. 其它情况,取左上角达到路径和右上角达到路径的最大值
题解:
#include<iostream> #include <algorithm> using namespace std; int main(){ int n; cin>>n; int dag[n][n]={0}; //动态规划表 int dp[n+1][n+1]={0}; //输入数组 for(int i=0;i<n;i++){ for(int j=0;j<=i;j++){ cin>>dag[i][j]; } } int maxLenth = 0; for(int i=1;i<=n;i++){ for(int j=1;j<=i;j++){ //顶点值 if(i==1){ dp[i][j]=dag[0][0]; } else{ //左边界 if(j==1){ dp[i][j]=dp[i-1][j]+dag[i-1][j-1]; } //右边界 else if(j==i){ dp[i][j]=dp[i-1][j-1]+dag[i-1][j-1]; } //中间的点,取左上角和右上角的最大值 else{ dp[i][j]=max(dp[i-1][j]+dag[i-1][j-1],dp[i-1][j-1]+dag[i-1][j-1]); } } //更新答案 if(dp[i][j]>maxLenth){ maxLenth=dp[i][j]; } } } cout<<maxLenth; }
2.最长子序列和问题
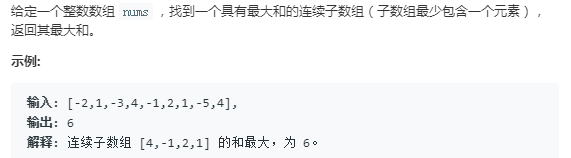
分析:求子序列的和,则假设某子序列是从第i到第j个元素(j>=i),则到第j个元素为止的和为前第i到第j-1的和加上第j个元素
假设sum(i,j)表示从第i到第j个元素的最大子序和,则数到第j个元素时,有两种选择:
1.算上j之后,和会更大(j为正数),此时m(i,j)=m(i,j-1)+nums[j-1]
2.算上j之后,和会变小(j为负数),则此时应该舍去j,即m(i,j)=m(i,j-1)
最终的结果为前面两种情况取最大值,所以状态转移方程为:
m(i,j)=max{m(i,j-1)+nums[j-1],m(i,j-1)}
一般确实会这样想,但是输出的结果为12,仔细分析可以发现12是1+4+2+1+4,即不连续子串的最大和。因此如果这样去定义,没有保证子串的连续性。
因为dp[i][j-1]舍弃了nums[j-1]之后,还会继续向后搜索,如果m(i,j)=m(i,j-1)成立,我们就跳过了第j个元素,从而导致子串不连续。因此m(i,j)的每种取值都必须包含第j个元素。
因此,我们应该这样来考虑,数到第j个元素时,有两种选择:
1.第j个元素加上前面的子序和之后,整体和会变大(前面子序和为正数),此时m(i,j)=m(i,j-1)+nums[j-1]
2.第j个元素加上前面的子序和之后,整体和会变小(前面子序和为负数),这时应该舍去前面的子序,从第j个元素开始重新搜索,此时m(i,j)=nums[j-1].
所以状态转移方程为:
m(i,j)=max{m(i,j-1)+nums[j-1],nums[j-1]}
题解:
#include<iostream> #include <algorithm> using namespace std; int main(){ //原始数组 int nums[9] = {-2,1,-3,4,-1,2,1,-5,4}; //动态规划表 int dp[10][10]={0}; //答案 int maxSum=0; for(int i=1;i<=9;i++){ for(int j=1;j<=9;j++){ dp[i][j]=max(dp[i][j-1]+nums[j-1],nums[j-1]); if(dp[i][j]>maxSum){ maxSum=dp[i][j]; } } } cout<<maxSum; }

